什么是分布式系统
分布式系统
分布式体系

分布式与集群区别
分布式是相对中心化而来,强调的是任务在多个物理隔离的节点上进行。中心化带来的主要问题是可靠性,若中心节点宕机则整个系统不可用,分布式除了解决部分中心化问题,也倾向于分散负载,但分布式会带来很多的其他问题,最主要的就是一致性。
集群就是逻辑上处理同一任务的机器集合,可以属于同一机房,也可分属不同的机房。分布式这个概念可以运行在某个集群里面,某个集群也可作为分布式概念的一个节点。
-
分布式:不同的业务模块部署在不同的服务器上或者同一个业务模块分拆多个子业务,部署在不同的服务器上,解决高并发的问题
-
集群:同一个业务部署在多台机器上,提高系统可用性
分布式要点
CAP
CAP 理论的定义很简单,CAP 三个字母分别代表了分布式系统中三个相互矛盾的属性:
- Consistency (一致性):CAP 理论中的副本一致性特指强一致性(1.3.4 );
Availiablity(可用性):指系统在出现异常时已经可以提供服务; - Tolerance to the partition of network (分区容忍):指系统可以对网络分区(1.1.4.2 )这种异常情 况进行容错处理;
- CAP 理论指出:无法设计一种分布式协议,使得同时完全具备CAP 三个属性,即1)该种协议下的副本始终是强一致性,2)服务始终是可用的,3)协议可以容忍任何网络分区异常;分布式系统协议只能在CAP 这三者间所有折中。
热力学第二定律说明了永动机是不可能存在的,不要去妄图设计永动机。与之类似,CAP 理论的意义就在于明确提出了不要去妄图设计一种对CAP 三大属性都完全拥有的完美系统,因为这种系统在理论上就已经被证明不存在。
Paxos协议
Paxos 协议是少数在工程实践中证实的强一致性、高可用的去中心化分布式协议。Paxos 协议的流程较为复杂,但其基本思想却不难理解,类似于人类社会的投票过程。Paxos 协议中,有一组完全对等的参与节点(称为accpetor),这组节点各自就某一事件做出决议,如果某个决议获得了超过半数节点的同意则生效。Paxos 协议中只要有超过一半的节点正常,就可以工作,能很好对抗宕机、网络分化等异常情况。
两阶段提交协议
两阶段提交协议是一种典型的“中心化副本控制”协议。在该协议中,参与的节点分为两类:一个中心化协调者节点(coordinator)和N 个参与者节点(participant)。每个参与者节点即上文背景介绍中的管理数据库副本的节点。
两阶段提交的思路比较简单,在第一阶段,协调者询问所有的参与者是否可以提交事务(请参与者投票),所有参与者向协调者投票。在第二阶段,协调者根据所有参与者的投票结果做出是否事务可以全局提交的决定,并通知所有的参与者执行该决定。在一个两阶段提交流程中,参与者不能改变自己的投票结果。两阶段提交协议的可以全局提交的前提是所有的参与者都同意提交事务,只要有一个参与者投票选择放弃(abort)事务,则事务必须被放弃。
CAP理论和适用场景
在分布式系统中,围绕着CAP理论,主要关注点就是复制,一致性,容错性。
1、复制
为了保证系统的高可用和高可靠性,通过复制的方式,让数据在系统中存储多个副本。以服务实例多副本为例,当一个服务发生异常时,客户端就直接调用其他正常的副本。如下:
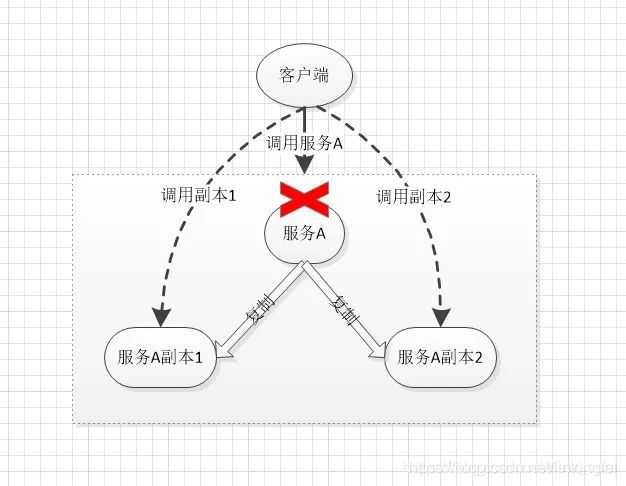
服务A有两个副本,分别为副本1和副本2。当客户端调用服务A时,如果服务A发生异常无法调用,此时,客户端调用副本1或者副本2,这样就保证了系统的高可用。
可以就这么认为,每个服务实例发生异常是无法避免的。例如,因为内存错误,第三方中间件挂掉了,甚至服务器停电等原因造成服务器宕机。或者,因为消息丢失,消息乱序,或者网络包数据错误造成网络异常等等。
2、一致性
在数据的复制中,由于存在多个数据副本,就会存在主数据与副本数据一致性的问题。在同一份数据的副本中,一般有一个副本为主副本,其他的备副本。在数据的复制过程中,复制的方式分为两种分别如下:
-
强同步复制,数据的写操作需要同步到主副本和所有的备副本,并且全部写入成功后,才返回成功状态。这样,当系统出现异常时,切换到其他任何一个备份副本时,数据是一致的。但是,强同步复制性能不好,而且可用性比较差。如果,在复制过程中,如果某个备份节点出现故障,这时,会阻塞数据的正常写服务。
-
异步复制,当数据写入操作成功后,当数据成功复制到主副本时,甚至还没复制时,写操作就返回成功状态。这样,异步复制的性别比较好,但是,当主备出现故障时可能出现数据丢失。
3、容错性
分布式系统中,集群的规模越大发生错误的概率就也大。一般,分布式系统发生异常时,都能够自动容错,保证系统的高可用。
CAP理论
CAP理论是Eric Brewer教授提出的,分别是一致性(Consistency),可用性(Availability),分区容错性(Tolerance of network Partition),三者不能同时满足。CAP三者可以按照如下的方式来理解:
-
一致性:数据复制的时候,按照强一致性的方式进行数据复制。保证了在读操作总是能够读取到之前写入的数据,无论从那个主数据或者副本数据。
-
可用性:数据写入成功后,正在进行数据复制时,任何一个副本节点发生异常也不会影响此次写入操作。可以理解为,此时数据的复制采用的是弱一致性,数据的读写操作在单台机器发生故障的情况下仍然可以正常执行。
-
分区容错性:在服务实例发生异常时,分布式系统仍然能够满足一致性和可用性。
在分布式系统中,是必须要求系统能够自动容错的,所以,必须满足分区容错性。因此,一致性和可用性就需要根据系统需求二选一了。
CAP使用场景
AP模式
eureka服务注册与发现中心集群,在集群中,新增一个eureka实例时,集群中的实例是相互复制其注册的服务实例数据。示例如下:

如图,在服务B向Eureka2注册成功后,此时,Eureka2还没向Eureka3复制成功就挂掉了,此时,在Eureka的服务注册与发现中心集群中造成了数据不一致。当服务A通过服务注册于发现中心集群通过Eureka3来拿服务B的地址时,就无法拿到。
mysql数据集群与redis集群,由于mysql和redis的数据复制都是采用的异步复制,所以mysql数据集群与redis集群都属于AP类型,在集群中获取数据时,会存在数据不一致的情况。
CP模式
zookeeper服务注册与发现中心集,在集群中,包含一个Leader节点,其余全部为Follower 节点。Leader节点负责读和写操作,Follower 节点只负责读操作。当客户端向集群发出写请求时,写请求会转发到Leader节点,Leader写操作完成后,采用广播的形式,向其余Follower 节点复制数据,Follower节点也写成功,返回给客户端成功。流程如图:

如图,在服务A向zookeeper集群注册时,写请求会被转发到Leader节点(zookeeper1),此时,Leader节点写入成功后,会通知 zookeeper2和zookeeper3节点进行复制,并且复制成功了才会向服务A返回注册成功的状态。此后,服务B通过集合获取服务A的地址,无论从哪个节点都能获取服务A的服务地址。
-
数据库两阶段提交,第一阶段,事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交。第二阶段,事务协调器要求每个数据库提交数据。如果有任何一个数据库否决此次提交,那么所有数据库操作的数据都会回滚。
-
Kafka集群(ack=all的配置时),Kafka消息集群中,生产者生成消息时,采用ack=all的配置时,消息成功写入分区,以及其所有分区副本后才算写入成功。此时,消费者从集群中获取的数据都是一致的。