基于深度学习的安全帽监管系统
摘 要
安全生产管理是建筑、重工业等高危企业发展的重要方针,安全帽在施工生产环境中对人员头部防护起着关键作用,因此加强安全帽佩戴监管十分必要。近年来,基于图像视觉的安全帽佩戴监测方法成为了企业实施管理的主要手段,如何提高安全帽佩戴检测精度和检测速度是应用的关键难题。针对上述问题,文中提出了一种基于改进YOLO v4的安全帽佩戴检测算法。首先,在YOLO v4算法的3个特征图输出的基础上增加了128×128特征图输出,从而将特征图输出的8倍下采样改为4倍下采样,为后续特征融合提供了更多小目标特征。其次,基于密集连接的思想对特征融合模块进行改进以实现特征重用,使得负责小目标检测的Yolo Head分类器可以结合不同层次特征层的特征,从而得到更好的目标检测分类结果。最后,对比实验的结果表明,所提方法的平均精度高达91.17%,相比原网络检测精度提高了2.96%,检测速度基本不变,可达52.9 frame/s,从而在满足实时检测需求的同时可以得到更优的检测精度,有效实现了安全帽佩戴的高速高精度检测。
关键词:深度学习、安全帽
ABSTRACT
Safety production management is an important policy for the development of high-risk enterprises such as construction and heavy industry. Safety helmets play a key role in personnel head protection in the construction and production environment. Therefore, it is necessary to strengthen the supervision of safety helmet wearing. In recent years, helmet wearing monitoring method based on image vision has become the main means of enterprise management. How to improve the detection accuracy and speed of helmet wearing is the key problem of application. To solve the above problems, a helmet wearing detection algorithm based on improved Yolo V4 is proposed in this paper. Firstly, 128 are added to the output of three characteristic graphs of Yolo V4 algorithm × 128 feature map output, which changes the 8 times down sampling of feature map output to 4 times down sampling, providing more small target features for subsequent feature fusion. Secondly, based on the idea of dense connection, the feature fusion module is improved to realize feature reuse, so that the Yolo head classifier responsible for small target detection can combine the features of different feature layers, so as to get better target detection and classification results. Finally, the results of comparative experiments show that the average accuracy of the proposed method is as high as 91.17%, which is 2.96% higher than the original network detection accuracy, and the detection speed is basically unchanged, up to 52.9 frame / s. therefore, it can obtain better detection accuracy while meeting the real-time detection requirements, and effectively realize the high-speed and high-precision detection of helmet wearing
Keywords: Deep learning、safety helmet
目 录
第1章 引言
第2章 本文算法
2.1 YOLOv4
2.2 目标检测器通用框架
2.3 CSPDarknet53
2.4 SPP结构
2.5 PAN结构
第3章 BackBone训练策略
3.1 数据增强
3.2 DropBlock正则化
3.3 类标签平滑
第4章 系统概述
4.1系统结构图
4.2 模型训练
参考文献
- 引言
安全生产管理是建筑、重工业等高危企业发展的重要方针,安全帽在施工生产环境中对人员头部防护起着关键作用。 然而,由于施工人员流动性大、安全意识匮乏以及监管人员不 到位等多种因素,导致实际工作中施工人员未佩戴安全帽的 不安全行为时有发生,带来了极大的安全隐患。因此,安全帽佩戴监管是高危作业环境中不可或缺的环节。传统依靠人工 监管的方式存在效率低下、管理范围有限时效性差、无法全场监测等诸多缺陷,因此基于图像视觉的安全帽佩戴监测方法逐渐成为企业实施管理的主要手段。
鉴于安全帽佩戴检测的重要性,利用图像视觉和神经网络算法对安全帽佩戴情况进行检测一直是研究的热点,国内外许多学者已对此做了大量工作,RCNN系列、SSD和YOLO系列等算法在安全帽检测中都得到了广泛应用。然而,在实际应用中,由于安全帽佩戴检测外部环境通常为建筑工地、大型工厂、车间等复杂环境,目标遮挡、光线等因素极易影响检测精度,另一方面,在安全帽实时监测的视频采集原始图像中,安全帽目标相比图像尺寸通常占比很小,往往会造成目标漏检。因此,如何提高复杂环境下的安全帽佩戴检测精度和检测速度是应用的关键。针对上述难题,本文提出了一种基于改进YOLOv4的安全帽佩戴检测方法。
- 2.12
2.1 YOLOv4
YOLOV4其实是一个结合了大量前人研究技术,加以组合并进行适当创新的算法,实现了速度和精度的完美平衡。可以说有许多技巧可以提高卷积神经网络(CNN)的准确性,但是某些技巧仅适合在某些模型上运行,或者仅在某些问题上运行,或者仅在小型数据集上运行;我们来码一码这篇文章里作者都用了哪些调优手段:加权残差连接(WRC),跨阶段部分连接(CSP),跨小批量标准化(CmBN),自对抗训练(SAT),Mish激活,马赛克数据增强,CmBN,DropBlock正则化,CIoU Loss等等。经过一系列的堆料,终于实现了目前最优的实验结果:43.5%的AP(在Tesla V100上,MS COCO数据集的实时速度约为65FPS)。
2.2 目标检测器通用框架
目前检测器通常可以分为以下几个部分,不管是two-stage还是one-stage都可以划分为如下结构,只不过各类目标检测算法设计改进侧重在不同位置:
如上图,除了输入,一般one-stage的目标检测算法通常由提取特征的backbone,传输到检测网络的Neck部分和负责检测的Head部分。而two-stage的算法通常还包括空间预测部分。网络中常用的模块为:
Input: 图像,图像金字塔等
Backbone: VGG16,Resnet-50,ResNeXt-101,Darknet53,……
Neck: FPN,PANet,Bi-FPN,……
Head: Dense Prediction:RPN,YOLO,SSD,RetinaNet,FCOS,……
Head: Sparse Prediction:Faster RCNN,Fast RCNN,R-CNN,……
而作为one-stage的YOLO网络主要由三个主要组件组成:
Backbone -在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
Head:对图像特征进行预测,生成边界框和并预测类别。
YOLOv4的整体原理图如下:
2.3 CSPDarknet53
我们前面知道在YOLOv3中,特征提取网络使用的是Darknet53,而在YOLOv4中,对Darknet53做了一点改进,借鉴了CSPNet,CSPNet全称是Cross Stage Partial Networks,也就是跨阶段局部网络。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。如下图:

CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主要有CSPResNext50 和CSPDarknet53两种改造Backbone网络。
考虑到几方面的平衡:输入网络分辨率/卷积层数量/参数数量/输出维度。一个模型的分类效果好不见得其检测效果就好,想要检测效果好需要以下几点:
更大的网络输入分辨率——用于检测小目标
更深的网络层——能够覆盖更大面积的感受野
更多的参数——更好的检测同一图像内不同size的目标
这样最终的CSPDarknet53结构就如下图:
2.4 SPP结构
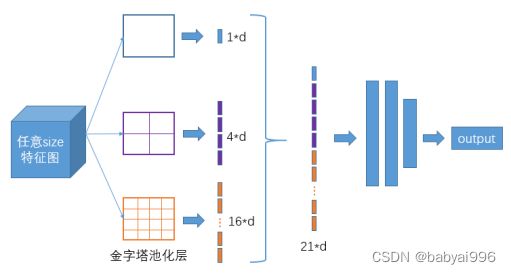
SPP-Net结构我们之前也有学过,SPP-Net全称Spatial Pyramid Pooling Networks,当时主要是用来解决不同尺寸的特征图如何进入全连接层的,直接看下图,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
2.5 PAN结构
YOLOv4使用PANet(Path Aggregation Network)代替FPN进行参数聚合以适用于不同level的目标检测, PANet论文中融合的时候使用的方法是Addition,YOLOv4算法将融合的方法由加法改为Concatenation。如下图:
- BackBone训练策略
3.1 数据增强
YOLOv4选择用CutMix的增强方式,CutMix的处理方式也比较简单,同样也是对一对图片做操作,简单讲就是随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整,比如0.6像狗,0.4像猫,计算损失时同样采用加权求和的方式进行求解。这里借CutMix的地方顺带说下几种类似的增强方式:

几种增强方式做的对比,结果显而易见,CutMix的增强方式在三个数据集上的表现都是最优的。其中Mixup是直接求和两张图,如同附身,鬼影一样,模型很难学到准确的特征图响应分布。Cutout是直接去除图像的一个区域,这迫使模型在进行分类时不能对特定的特征过于自信。然而,图像的一部分充满了无用的信息,这是一种浪费。在CutMix中,将图像的一部分剪切并粘贴到另一个图像上,使得模型更容易区分异类。
3.2 DropBlock正则化
正则化技术有助于避免数据科学专业人员面临的最常见的问题,即过拟合。对于正则化,已经提出了几种方法,如L1和L2正则化、Dropout、Early Stopping和数据增强。这里YOLOv4用了DropBlock正则化的方法。
DropBlock方法的引入是为了克服Dropout随机丢弃特征的主要缺点,Dropout被证明是全连接网络的有效策略,但在特征空间相关的卷积层中效果不佳。DropBlock技术在称为块的相邻相关区域中丢弃特征。这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。如下图:

3.3 类标签平滑
对于分类问题,特别是多分类问题,常常把向量转换成one-hot-vector,而one-hot带来的问题: 对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
无法保证模型的泛化能力,容易造成过拟合;
全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难适应。会造成模型过于相信预测的类别。
对预测有100%的信心可能表明模型是在记忆数据,而不是在学习。标签平滑调整预测的目标上限为一个较低的值,比如0.9。它将使用这个值而不是1.0来计算损失。这个概念缓解了过度拟合。说白了,这个平滑就是一定程度缩小label中min和max的差距,label平滑可以减小过拟合。所以,适当调整label,让两端的极值往中间凑凑,可以增加泛化性能。
- 系统概述
4.1系统结构图

4.2 模型训练

参考文献
- 钟子义深度学习原理[M]北京:北京邮电大学出版社2013.
[2]周世勋.深度学习教程[M] 2版北京:高等教育出版社,2009.
[3]郭邦红,胡敏,毛睿等深度学习[J]深圳大学学报(理工版),2020,37(6):551-558.
- 高鹏.周华旭,YOLO当前应用分析[J]电子设计工程2020,28(16):115-118,123.
[5]张亮亮,张翌维梁洁等YOLO时代下的信息安全[J]计算机科学,2017 ,44(7):1-7,15.
项目下载:商用Python工地安全帽识别安全帽检测预警yolo可以检测图片,视频流,有界面python商用源码_python安全帽识别-深度学习文档类资源-CSDN下载
项目部署教程:商用Python工地安全帽识别安全帽检测预警yolo可以检测图片,视频流,有界面python商用源码视频讲解_python安全帽检测-深度学习文档类资源-CSDN下载