企业实战——Hadoop大数据平台三个节点实现(1个master+2个slave)
先在server1上停掉刚才的运行文件
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
[hadoop@server1 hadoop]$ cd /tmp/
[hadoop@server1 tmp]$ rm -fr *

现在开始做三个节点的集群
在server2上新建hadoop用户(server3与server2相同操作)
[root@server2 ~]# useradd hadoop
[root@server2 ~]# id hadoop


在三个节点上均安装nfs服务并且开启服务共享hadoop
[root@server1 ~]# yum install -y nfs-utils
[root@server1 ~]# systemctl start rpcbind



在server1(master节点)上配置nfs服务,设置共享目录,并且开启服务
[root@server1 ~]# systemctl start nfs-server
[root@server1 ~]# vim /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server1 ~]# exportfs -rv


[root@server1 ~]# showmount -e

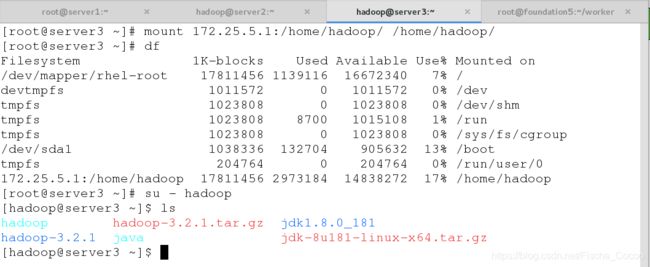
在server2和server3上建立用户并且挂载server1上的nfs共享目录到本地
[root@server2 ~]# mount 172.25.5.1:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1139376 16672080 7% /
devtmpfs 1011572 0 1011572 0% /dev
tmpfs 1023808 0 1023808 0% /dev/shm
tmpfs 1023808 8700 1015108 1% /run
tmpfs 1023808 0 1023808 0% /sys/fs/cgroup
/dev/sda1 1038336 132704 905632 13% /boot
tmpfs 204764 0 204764 0% /run/user/0
172.25.5.1:/home/hadoop 17811456 2973184 14838272 17% /home/hadoop
[root@server2 ~]# su - hadoop
[hadoop@server2 ~]$ ls
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181
hadoop-3.2.1 java jdk-8u181-linux-x64.tar.gz

[root@server3 ~]# mount 172.25.5.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1139116 16672340 7% /
devtmpfs 1011572 0 1011572 0% /dev
tmpfs 1023808 0 1023808 0% /dev/shm
tmpfs 1023808 8700 1015108 1% /run
tmpfs 1023808 0 1023808 0% /sys/fs/cgroup
/dev/sda1 1038336 132704 905632 13% /boot
tmpfs 204764 0 204764 0% /run/user/0
172.25.5.1:/home/hadoop 17811456 2973184 14838272 17% /home/hadoop
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ls
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181
hadoop-3.2.1 java jdk-8u181-linux-x64.tar.gz
在server1上修改相关的文件
[hadoop@server1 ~]# cd /home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]# vim hdfs-site.xml

[hadoop@server1 hadoop]# vim workers

由于家目录共享,因此三个节点上的公钥和私钥是一样的,因此可以互相免密连接
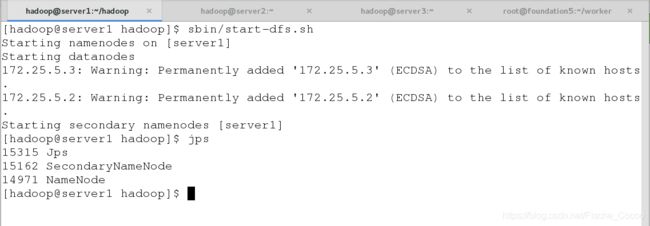
在server1上再次开启服务,发现datanode转移到了slave节点上面
[hadoop@server1 hadoop]# bin/hdfs namenode -format ##初始化

[hadoop@server1 hadoop]# sbin/start-dfs.sh
[hadoop@server1 hadoop]$ jps
[hadoop@server2 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server2 hadoop]$ cat workers
172.25.5.2
172.25.5.3
[hadoop@server2 hadoop]$ jps
11356 Jps
11277 DataNode

[hadoop@server3 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server3 hadoop]$ cat workers
172.25.5.2
172.25.5.3
[hadoop@server3 hadoop]$ jps
11347 Jps
11269 DataNode

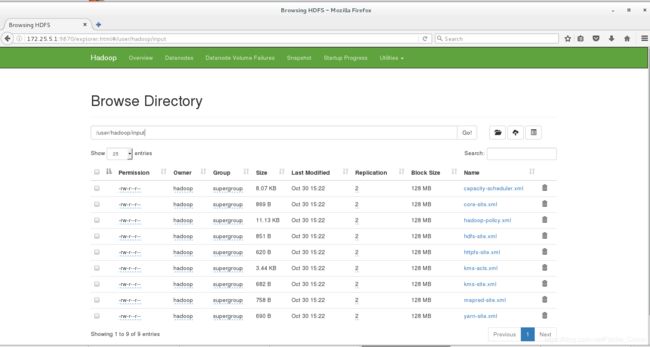
在master节点上再次上传一个文件并且在浏览器里面查看
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bin include libexec logs README.txt share
etc lib LICENSE.txt NOTICE.txt sbin
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input

[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
在浏览器查看