单台服务器百万并发实现 C10K, C1000K, C10M
基本概念
并发量:服务器能够承载的客户端数量
吞吐量:单位时间内,能够处理的数量
举例:客户端发一个请求,服务端能够在200ms内能够返回结果
需要考虑的因素:
- 数据库
- io操作(日志、文件、网络等)
- 网络带宽
- 内存操作
注:服务器能够同时建立的连接数量就是服务器的并发量这种认知是错误的。连接数量只是服务器并发量的一个基础或者说是前提。
什么是C10K, C1000K, C10M?
C10K:单台服务器可以同时承载1w个网络连接
C1000K:单台服务器可以同时承载100w个网络连接
C10M:单台服务器可以同时承载1000w个网络连接
并发量的瓶颈是什么?
可以分两个大类:
- 系统限制
- 代码限制
系统限制
以Linux为主,存在几个问题
open_files 的值,这个值代表了一个进程最多可以打开的文件fd的数量。当然这个值不能超过file-max,超出file-max的部分是无效的。
# 方法一:重启后无效
ulimit -HSn 102400
# 方法二:重启后依旧生效
# 将方法一内容写到/etc/profile中,因为每次登录终端时,都会自动行/etc/profile
# 方法三:重启后生效
vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535fs.file-max的值,表示系统级别的能够打开的文件fd的数量。是对整个系统的限制,并不是针对用户的。超过fs.file-max值的fd是无效的。
// 方式一
$ echo 6553560 > /proc/sys/fs/file-max
// 方式二
$ sysctl -w "fs.file-max=34166"
// 以上2种,重启机器后会恢复为默认值
// 方式三,立即生效,此方式永久生效
$ echo "fs.file-max = 6553560" >> /etc/sysctl.conf
$ sysctl -p
代码限制
实现C10K
C10K问题最早由Dan Kegel在1999年提出,那时的服务器还只是32位系统,运行着Linux 2.2版本(后来又升级到了2.4和2.6,而2.6才支持x86_64)只配置了很少的内存(2GB)和千兆网卡。
从资源上对2GB内存和千兆网卡的服务器来说,同时处理10000个请求,只要每个请求处理占用不到200KB(2GB/10000)的内存和100Kbit (1000Mbit/10000)的网络带宽就可以。所以,物理资源是足够的,接下来自然是软件的问题,特别是网络的I/O模型问题。
在C10K以前,Linux中网络处理都用同步阻塞的方式,也就是每个请求都分配一个进程或者线程,请求数只有100个时,这种方式自然没问题。但增加到10000个请求时,10000个进程或线程的调度、上下文切换乃至它们占用的内存,都会成为瓶颈。
所以要实现C10k,只需要使用网络io多路复用模型即可(select/poll/epoll)
实现C1000K
在早期实现C10k后,大多数都采用的是select/poll。select/poll的主要问题是,select每次去监听等待的时候,需要把用户的fd集合复制到内核中,并且是以遍历的方式带出来给应用程序。且select最多一次只能处理1024个网络io事件。poll本质上跟select没有区别,只是它没有最大事件数的限制。
采用epoll即可实现C1000k。
epoll为什么快呢?这个方式不再需要每次都将用户的fd集合复制一份到内核,而是将要用到的IO通过epoll_ctl的方式加入到内核里面,内核里面有一颗红黑树存储这些IO,一旦某个结点活跃有数据,就将结点通过链表的方式连接成一个队列(注意:加入队列但并没有移出红黑树)。而epoll_wait所做的事情,就说将就绪队列从内核中复制出来。此时就只需要复制有数据的结点,且不需要拷贝大量数据到内核,所以快。
实现C10M
从网络请求到应用程序的过程中,要经过网卡->协议栈->应用。这里系统会先将数据拷贝到内核中,然后应用通过调用recv函数,从内核中再次拷贝到应用层,所以这里的数据进行了2次拷贝。
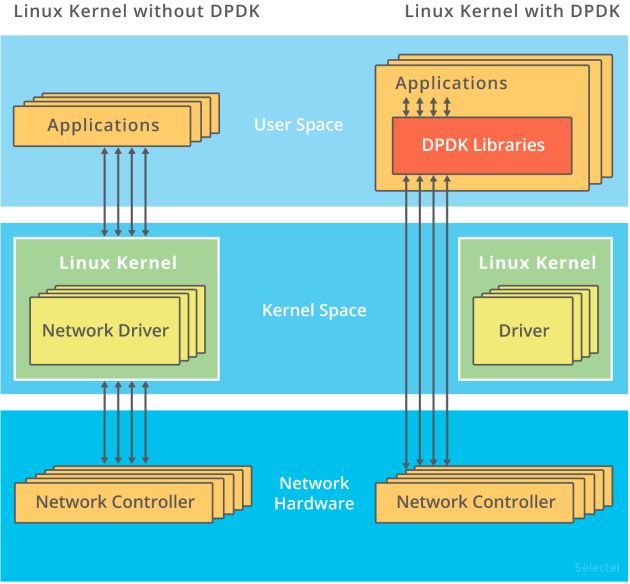
这时候可以选择将协议栈放弃,直接应用与网卡进行交互,减少了协议栈这一层,提升速度。这里有两种常见的机制DPDK和XDP
DPDK
是用户态网络的标准,它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收
说起轮询,会下意识认为它是低效的象征,它的低效主要体现在哪里呢?
是查询时间明显多于实际工作时间的情况!那么,换个角度来想,如果每时每刻都有新的网络包需要处理,轮询的优势就很明显了。比如在PPS非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包而跳过内核协议栈后,就省去了繁杂的硬中断、软中断再到Linux网络协议栈逐层处理的过程。应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节。此外DPDK还通过大页、CPU绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率
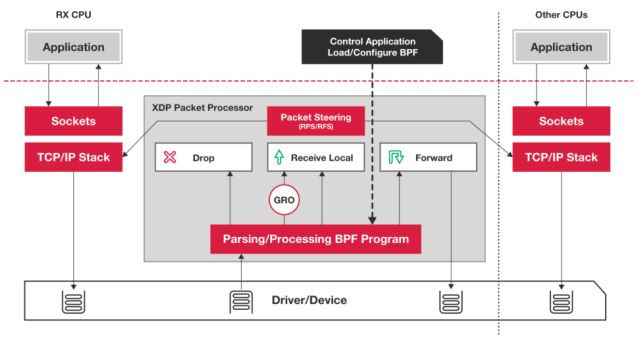
XDP(eXpress Data Path)
Linux内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。XDP底层跟之前用到的bcc-tools一样,都是基于Linux内核的eBPF机制实现的
XDP对内核的要求比较高,需要的是Linux 4.8以上版本,并且它也不提供缓存队列。基于XDP的应用程序通常是专用的网络应用,常见的有IDS(入侵检测系统)、DDoS防御、 cilium容器网络插件等
其他优化-工作模型优化
主进程 + 多个 worker 子进程(nginx)
- 主进程执行 bind() + listen() 后,创建多个子进程;
- 在每个子进程中,通过 accept() 或 epoll_wait(),来处理相同的套接字;
accept线程组+worker线程组(netty)
- accept线程组负责accept(),然后放进队列
- worker线程组负责业务逻辑的处理
其他问题
客户端发起连接只能发起6W多个连接的原因
执行sudo sysctl -p 查看
看net.nf_conntrack_max的值,这个值默认65535,限制了发起数量
系统默认不加载的,需要加载一下,因为客户端发起超大量请求才会出现这个问题。
# 开启:
sudo modprobe ip_conntrack
# 方法一:重启后无效
echo 1048576 > /proc/sys/net/nf_conntrack_max
# 方法二:重启后无效
sysctl -w "net.nf_conntrack_max=1048576"
# 方法三:重启后生效
vim /etc/sysctl.conf
net.nf_conntrack_max = 6553560单个客户端可发起连接数已经修改,还是报错
报错信息: cannot assign requested address
这个问题在于网络五元组导致的,由于源ip和目的ip固定,源端口最大数量也固定,那么能改变的也只有目的端口了,所以服务器多开端口可以解决同一个机子发起大量链接的问题。
客户端连接到一定数量的网络请求后,报错: connection timed out
这个问题主要是linux系统内核为了安全,有个netfilter组件,iptables就是基于netfilter组件实现的。在大量连接了同一个服务器ip:port后,iptables会以为是垃圾请求,会拒绝把网络请求在发送的服务器。所以导致了connection timed out。
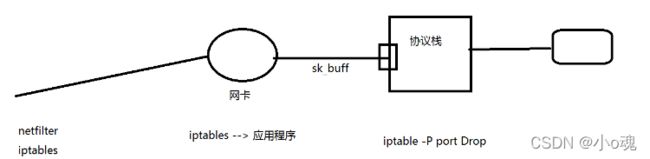
解决:
$ echo "net.nf_conntrack_max = 1048576" >> /etc/sysctl.conf
$ sysctl -p Error: /proc/sys/net/nf_conntrack_max no such file or directory
sudo modprobe ip_conntrack如何客户端connect的耗时变短???
限制原因:服务器的accept的限制,一个accept可处理的事件太少太慢。
解决办法:增加accept。(多线程、多进程)
如何让多个ACCEPT工作?
- 多个accept分配在不同的线程。
- 多个accept分配在不同的进程。(nginx做法)
多线程与多进程的区别???
- 多进程不需要加锁。
- 单个进程fd的上限比多线程多。(参考open_file、fs.file-max的定义)
参考技术
- 单线程同步:NTP
- 多线程同步:Netty
- 纯异步:Redis、HAProxy
- 半同步半异步:Netty
- 多进程同步:fastcgi
- 多线程异步:memcached
- 多进程异步:nginx
- 一个请求一个进程或线程:apache、cgi
- 微进程框架:erlang、go、lua
- 协程框架:libco