十四天——我都经历了爬虫的哪些坑(一些心得与反思,仅以次纪念,不作参考)
直接进入正题(记录我初学爬虫的一些心得):
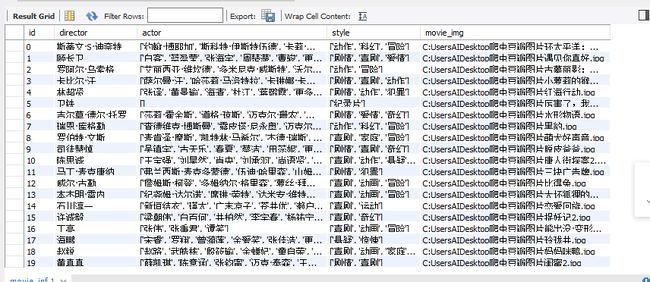
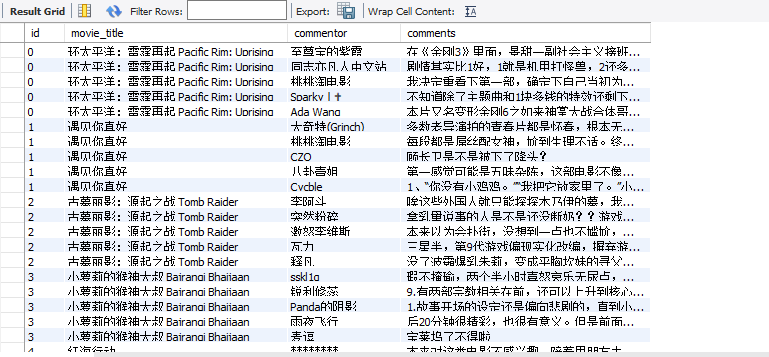
我爬的是豆瓣的电影,具体项目有电影名称、导演名、演员名、影片类型、影片海报、还有部分关于电影的短评(太多了的话爬一次时间太长,不太好往数据库里存)
先上最后结果吧:

首先,
先明确爬虫思路:①伪装成浏览器访问豆瓣网(https://movie.douban.com/),通过Google浏览器的网页编辑功能(具体操作就是F12),找到浏览器信息,然后访问
②在返回的html.text中,找到下面的“正在热映”的电影的链接地址、图片URL、正则表达式匹配信息(后来再看BeautifulSoup真的好用,不过正则表达式也确实无敌的一匹)通过链接地址找到每个电影的网页,然后继续爬取每个电影的信息,分别存储到几个列表中

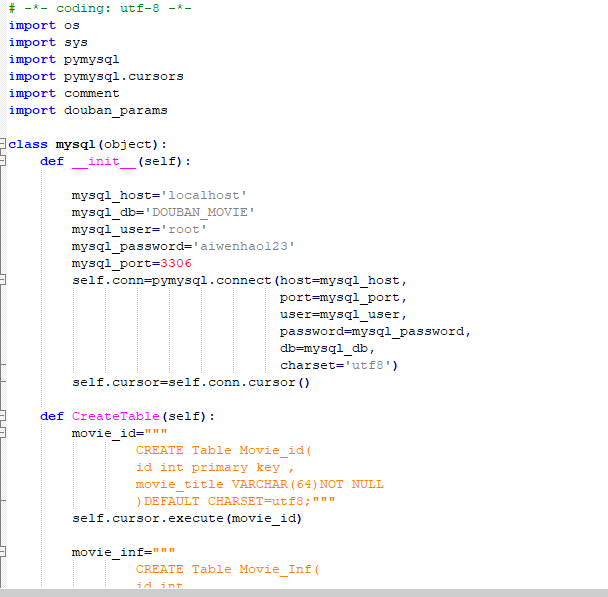
③和mysql链接,创建一个数据库,然后创建三个表,分别存储不同信息。
OK,大致思路准备完成,就可以开始动手操练起来了。
算了,不想写过程了,总之踩了一个有一个坑,有时候一个坑要踩好几遍,想起来都是淡淡的忧伤啊。。。
最后,写一下心得吧:
①utf8!!! utf8!!! utf8!!!重要的事情说三遍,从来没有想过一个编码格式的问题能把我伤成这个样子,读取html需要改为utf8
往列表中存储文件需要看看是不是utf8,最后往数据库里还需要再看看是不是utf8,不过据说BeautifulSoup可以自己解决编码问题,这个我还没确定过,不敢说死,不过初步尝试了一下BeautifulSoup,直接解析网页格式的方法真的好用。
②往文件中写入图片时,一定要注意时.content,而且是以二进制格式写进去,这个也困扰了我好久。
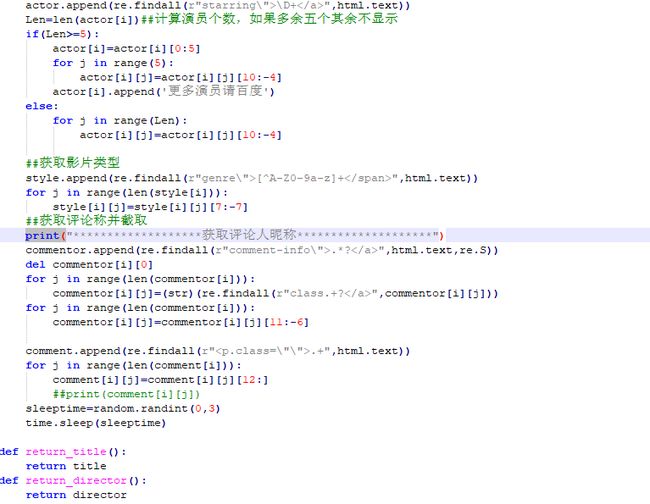
③关于正则表达式的应用,正则表达式大法好,刚开始用的时候(脑子中就是一个想法:我是谁,我在哪儿,我在做什么),后来用的再熟一些,嗯,别跟我说BeautifulSoup,我就信正则表达式!就没有一个正则表达式匹配不到的东西,一个不够用,用十个你还够不够用? 总之,正则表达式博大精深,这条路上我还得走的再远一点。

④关于字符串切片,有时候提取更加精确的目标时(比如影片名称),需要再切一下,这时候python 基础的重要性就显示出来了,学好数理化,走遍天下都不怕,基础很重要!身边常备python小教程~
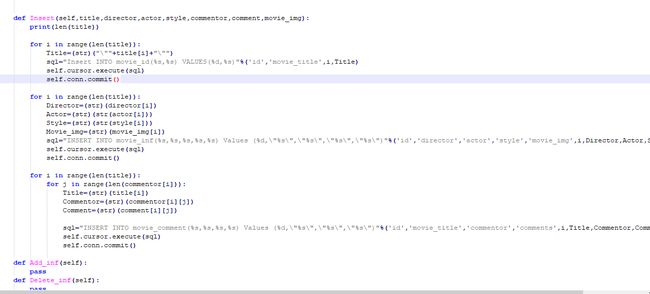
⑤关于数据库存储问题,不要忘了conn.commit(),不要忘了conn.commit(),不要忘了conn.commit()我就是因为这个东西没有弄,导致既不报错又存不进去数据,哎,那一个下午世界都暗淡了。。。
⑥关于反爬虫机制,嗯,涉世不深的我就因为没有礼貌的爬别人数据,结果被封了一小时IP。网上有不少解决方法,比如在网上爬一些ip(自己得试一下好不好用),或者花点儿钱从淘宝买一点儿,然后random()随机调用一下,再比如改一下User-Agent参数啥的(实测并不好用。。。),再比如time.sleep(),爬一会儿,歇一会儿。我觉得既然是骗人家的数据,就不要再给人找更多的麻烦了,还是文明索取,反对暴力执法(爬虫)。
弄完之后还存在的一些小问题以及反思:
①还是utf8的问题,往数据库里存的时候,有些emoji表情存不进去,网上的办法是修改mysql文件,但是我没有改成功,我的处理办法还是太粗糙了(直接舍弃这样的样本),关于这个还得多琢磨琢磨。另外网站转码也是我时时刻刻需要面对的难题,每次碰到这样的问题我都要头痛半天,各种查教程,总之这个还要多学一点
②关于编程习惯问题,我一个小程序往往需要很长时间的调试,但是我实在是不太习惯try:XXX except:XXX 这样的方式,这就给我带来了我需要不停的print(),来看我到底是哪一个地方出了错误,最终的结果就是我的最后代码很难看,难看到我委实不太想贴图的地步,以后还要多接触一下try:XXX,
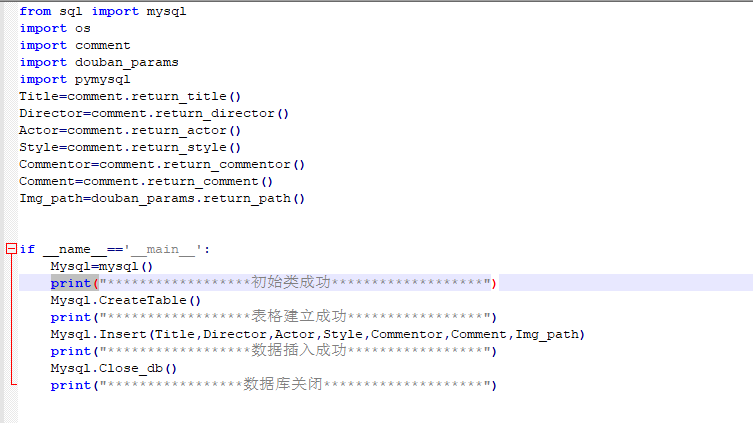
③还是编码习惯的问题,这个爬虫小代码,由于我不是一天弄完的,而且为了更好的分步骤完成我的思路,我用了好几个.py文件去实现,再回头看这些文件,发现我的习惯还是有很大改观的,从最开始的一条代码走到黑,到后来的用函数来调用,再到最后想办法把函数封装到一个类里面再去调用,不得不说视觉效果还是好了不少的(这里再说一下,调用类函数之前,要先把类初始化,调用类函数之前,要先把类初始化,调用类函数之前,要先把类初始化)。
④凡事应该有两手准备:刚写代码的时候还没有这种感觉,写到后来(往数据库里存数据的时候),需要一遍又一遍调用前面的爬虫程序,第一,花费的时间太长了,第二,确实不太好调试(本来就不停的print,然后再一遍一遍执行文件,确实不太好找问题出在哪里),第三,爬的频率太多导致被封IP(谁还没个年轻的时候——spiderboy),现在再看,豆瓣还真是好脾气,只封了我1个小时(然后我就开始time.sleep(),然后花的事假更长了。。。),我应该先把这些数据存到文件夹里面,这样再直接调用这些数据就会方便很多,而不应该一条路走到黑(每次都想着这事一个完整的爬虫思路,我不能割裂开)
⑤关于开始思路的问题,其实从一开始我就有了路线上的错误,我应该直接把爬到的数据往数据库里扔的,而不应该存到列表里再从列表往数据库里扔,我应该先弄数据库,再开始爬虫,这种路线上的错误,给我带来了不小的麻烦。
⑥再就是花费时间问题,从开始学爬虫到完成这个小程序,来回花费了近半个月,不得不承认效率太低了,回头再看,要是我从开始就认真点儿,不因为受一点儿打击就想着放弃(其实刚开始准备爬一本小说的,后来佛性的放弃了。。。),十天之内怎么也完事儿了,万事开头难,这句话真不是说说,但是仅仅是开头难。
贴一下我学习爬虫的网站(很小白,傻瓜教程 很适合像我这种编程能力基本为0的同学,也在这里谢谢这个作者):
https://blog.csdn.net/zangker/article/details/77864701
最后就贴一下我很不想贴的代码吧(截个图吧,我写的还真不是啥好东西,不值得借鉴,谨以此纪念一下):