【python】Numpy
Numpy of Python
- 什么是Numpy?
- 为什么Numpy很高效?
- numpy的安装
- numpy的基本操作
-
- (一)创建数组 array
- (二)数组的形状 shape & reshape
- (三)列表的加减乘除
- (四)列表的切片
- (五)基本初等函数
- (六)数量积向量积
- (七)Sigmoid Function
- (八)最大值最小值以及和
- (九)规范化、平均值与标准差
- (十)转置
- (十一)计算方阵的行列式
- (十二)计算行列式的逆
- (十三)对比numpy与loop
2022年9月29日更新
什么是Numpy?
Numpy 是 python 中进行科学计算的基础包,可以提供多维数组快速计算,基本线性函数,基本统计计算,随机模拟等等,具有高效、代码少的优点,尤其在处理极大数据集时有极为明显的优势。
为什么Numpy很高效?
Vectorization矢量化。
Vectorization 矢量化是什么概念?最通俗易懂的方式就是通过示例来解释。
e.g. 假设要计算两个向量的数量积,即 A=(x1,x2), B=(y1, y2), 则A·B=x1*y1+x2*y2
我们同时用两种方式进行计算,第一种是通过 for loop, 第二种通过 numpy.dot 函数。
# for loop 示例
for j in range(0,16):
# f = f + w[j]*x[j]
print("f = f + w[{}]*x[{}]".format(j,j))

# numpy 示例
import numpy as np
f = np.dot(w,x)
print(f)

直观来看,numpy方法明显代码更短,直接意味着编程难度降低以及编程代码出错概率的下降。但是在这里我们更加关注代码的效率。此案例中没有设置两个向量w以及x,想要尝试可以复制代码并且自行设置向量尝试。
@@@---------@@@
高效的原因:矢量化
@@@---------@@@
用 for 循环的方法,一步一步执行,重复len(w)次后执行完成;
用 numpy 方法,第一步是将w列为一行,x列为一行,通过计算机硬件的矢量化,将w行中每个元素与x中每个元素同时一一对应相乘,第二步相加,然后完成。
(吴恩达《机器学习》Multiple linear regression part2)

numpy 与 loop 很直观的差距:
(吴恩达《机器学习》Vector实验室数据)

@@@-------------------------@@@
选择numpy处理数据集的必然性
@@@-------------------------@@@
在超大型4V(Volume, Variety, Velocity, Veracity) 大数据的驱动下,加上算法的不断改进完善,机器学习在21世纪的进步非常可观。
但是大数据并不是意味着成百上千的数据,而是成百万上千万的ZB级别(img)的数据作为数据集,通过训练集对算法函数进行训练。
通过对比上述两个方案,很明显我们需要选择效率更高的numpy替换loop进行处理。因此学好numpy是在必然。
numpy的安装
正常来说,numpy会作为基本包在安装python时直接安装,但是不妨有特殊情况,若存在numpy可跳过本部分。
@@@—@@@
下载安装numpy
@@@—@@@
Step 1: 打开 anaconda prompt
Step 2: 输入下列安装命令安装numpy
conda install numpy
numpy的基本操作
(一)创建数组 array
通过 np.array 直接创建自己需要的数组。
import numpy as np
# 创建一维数组
a = np.array([1,2,3,4,5])
print(a)
print(a.ndim) # 打印数组a的维度
import numpy as np
# 创建多(2)维数组
b = np.array([1,2,3],[4,5,6])
print(b)
print(b.ndim) # 打印数组a的维度
import numpy as np
# 创建两行三列,元素值全部为1的数组
a = np.ones([2,3], dtype=np.int32)
# 创建三行两列,元素值全部为1的数组
a = np.ones([3,2], dtype=np.int32)
import numpy as np
# 创建三行两列,元素值全部为0的数组
a = np.zeros([3,2]) # all zero matrix of shape 3x2
# array([[0., 0.],
# [0., 0.],
# [0., 0.]])
(二)数组的形状 shape & reshape
@@@-------------------@@@
shape 函数获得数组的形状
@@@-------------------@@@
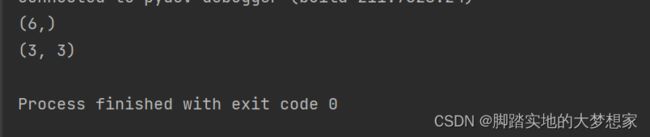
import numpy as np
# 打印数组的形状
x = np.array([1,2,3,4,5,6])
print(x.shape)
y = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(y.shape)
@@@-------------------@@@
reshape 函数重新构造其形状
@@@-------------------@@@
import numpy as np
# 重新构造数组形状
x = np.array([1,2,3,4,5,6])
print(x.reshape(3,2))
y = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(y.reshape(9,))

(三)列表的加减乘除
@@----@@
列表加减法
@@----@@
规则是必须是两个shape的相同才可以相加减
import numpy as np
# 加法 规则是必须要求两个shape相同的才可以相加
a = np.array([[1, 2],
[5, 6]])
b = np.array([[2, 2],
[2, 2]])
c = a + b
print(c)
# 减法 规则是必须要求两个shape相同的才可以相减
a = np.array([[1, 2],
[5, 6]])
b = np.array([[2, 2],
[2, 2]])
c = a - b
print(c)
@@----@@
列表乘除法
@@----@@
import numpy as np
a = np.array([[1, 2],
[5, 6]])
b = 2
c = a * b
print(c)
(四)列表的切片
import numpy as np
a = np.array([1,2,3,4,5,6,7,8,9])
print(a[1:4]) # 打印数组中第2-4个元素
print(a[:2]) # 打印数组中第1-2个元素
print(a[3:]) # 打印数组中第4个元素以及其后所有元素
print(a[::2]) # 每间隔一个打印一个数组中元素

(五)基本初等函数
import numpy as np
# 三角函数
print(np.sin(np.pi/6)) # sin(Π/6)
# 平方
print(np.square(99)) # 99 * 99
# 开方
print(np.sqrt(9801)) # 9801^1/2
# n次方
print(np.power(11, 3)) # 11 * 11 * 11
# e的n次方
print(np.exp(2)) # e^2
# 对数函数,以2,e,10为底
print(np.log(7.38)) # 默认以e为底,e^2=7.38
print(np.log2(16)) # np.log只能以2、e和10为底
print(np.log10(1000)) # np.log只能以2、e和10为底
(六)数量积向量积
a * b
a @ b
np.dot(a, b)
以上三个表达式中,有两个为数量积,一个为向量积。

故:
a * b (向量积)
a @ b (数量积)
np.dot(a, b) (数量积)
求向量积:
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[1,2,3],[4,5,6]])
print(a.shape)
print(b.shape)
print(a * b)
求数量积:
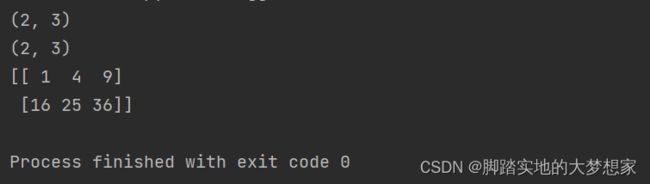
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[1,1],[1,1],[1,1]])
print(a.shape)
print(b.shape)
print(np.dot(a, b))
print(a @ b)

(七)Sigmoid Function
sigmoid function 作为机器学习中重要函数之一,在监督学习的分类领域比较常用。
sigmoid ( x ) = 1 1 + e − x \operatorname{sigmoid}(x) = \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
# Sigmoid 函数部分
import numpy as np
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
return s
# 绘制Sigmoid完整代码
import numpy as np
import matplotlib.pyplot as plt
x = []
y = []
for i in range(-1000,1000):
x.append(i)
s = 1 / (1 + np.exp(-i))
y.append(s)
# 绘图
plt.plot(x, y, c='r', label='Sigmoid function')
plt.title("Sigmoid Function")
plt.ylabel('y')
plt.xlabel('x')
plt.legend()
plt.show()

(八)最大值最小值以及和
import numpy as np
a = np.array([[2, 1, 3],
[4, 5, 6]])
print(np.min(a)) # 获取数组中最小值
print(np.max(a)) # 获取数组中最大值
print(np.sum(a)) # 获取数组中所有元素和
(九)规范化、平均值与标准差
c i = x i − mean ( x i ) σ ( x i ) c_i = \frac{x_i - \operatorname{mean}(x_i)}{\sigma(x_i)} ci=σ(xi)xi−mean(xi)
import numpy as np
a = np.array([1,2,3,4,5,6,7,8,9,10])
def normalize(x):
mean = np.mean(x)
print("means:{}".format(mean))
sigma = np.std(x)
print("sigma:{}".format(sigma))
c = (x-mean)/sigma
return c
print(normalize(a))

(十)转置
import numpy as np
A = np.array([[5, 2, 9],
[6, 1, 0]])
print(A.T)
(十一)计算方阵的行列式
import numpy as np
A = np.array([[5, 2, 9],
[6, 1, 0],
[1, 2, 3]])
print(np.linalg.det(A))

(十二)计算行列式的逆
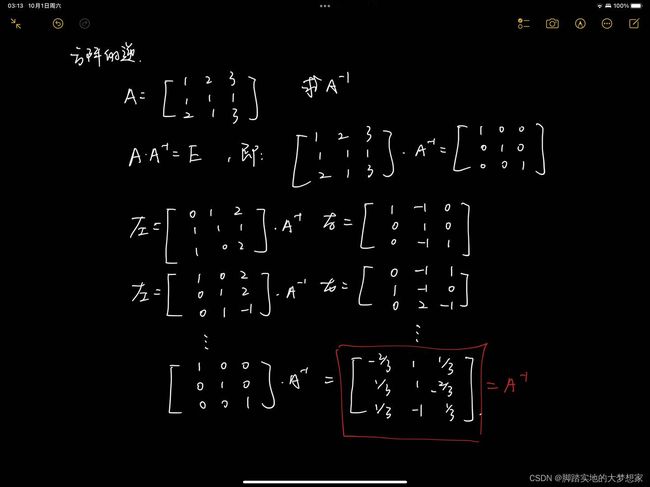
import numpy as np
A = np.array([[1, 2, 3],
[1, 1, 1],
[2, 1, 3]])
print(np.linalg.inv(A))
(十三)对比numpy与loop
import numpy as np
import time
def my_dot(a, b):
x=0
for i in range(a.shape[0]):
x = x + a[i] * b[i]
return x
np.random.seed(1)
a = np.random.rand(10000000) # very large arrays
b = np.random.rand(10000000)
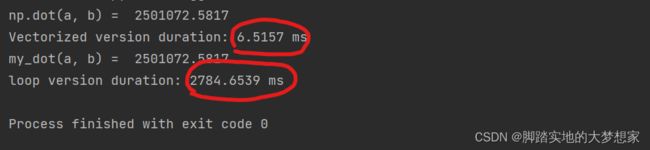
tic = time.time() # capture start time
c = np.dot(a, b)
toc = time.time() # capture end time
print(f"np.dot(a, b) = {c:.4f}")
print(f"Vectorized version duration: {1000*(toc-tic):.4f} ms ")
tic = time.time() # capture start time
c = my_dot(a,b)
toc = time.time() # capture end time
print(f"my_dot(a, b) = {c:.4f}")
print(f"loop version duration: {1000*(toc-tic):.4f} ms ")
del(a);del(b) #remove these big arrays from memory
未完待续
end – >