spark core之 RDD 之间的依赖关系
什么是 RDD 之间的依赖关系?
-
什么是关系(依赖关系) ?
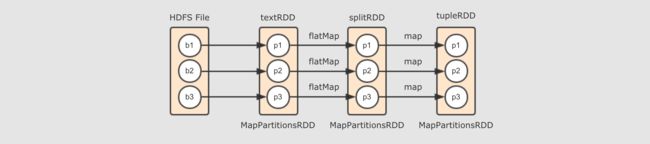
从算子视角上来看,
splitRDD通过map算子得到了tupleRDD, 所以splitRDD和tupleRDD之间的关系是map但是仅仅这样说, 会不够全面, 从细节上来看,
RDD只是数据和关于数据的计算, 而具体执行这种计算得出结果的是一个神秘的其它组件, 所以, 这两个RDD的关系可以表示为splitRDD的数据通过map操作, 被传入tupleRDD, 这是它们之间更细化的关系但是
RDD这个概念本身并不是数据容器, 数据真正应该存放的地方是RDD的分区, 所以如果把视角放在数据这一层面上的话, 直接讲这两个 RDD 之间有关系是不科学的, 应该从这两个 RDD 的分区之间的关系来讨论它们之间的关系 -
那这些分区之间是什么关系?
如果仅仅说
splitRDD和tupleRDD之间的话, 那它们的分区之间就是一对一的关系但是
tupleRDD到reduceRDD呢?tupleRDD通过算子reduceByKey生成reduceRDD, 而这个算子是一个Shuffle操作,Shuffle操作的两个RDD的分区之间并不是一对一,reduceByKey的一个分区对应tupleRDD的多个分区
reduceByKey 算子会生成 ShuffledRDD
reduceByKey 是由算子 combineByKey 来实现的, combineByKey 内部会创建 ShuffledRDD 返回, 具体的代码请大家通过 IDEA 来进行查看, 此处不再截图, 而整个 reduceByKey 操作大致如下过程

去掉两个 reducer 端的分区, 只留下一个的话, 如下
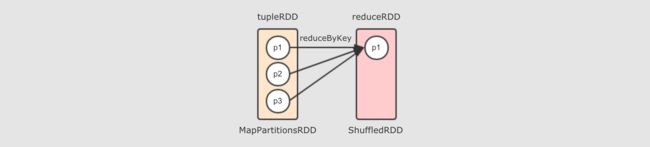
所以, 对于 reduceByKey 这个 Shuffle 操作来说, reducer 端的一个分区, 会从多个 mapper 端的分区拿取数据, 是一个多对一的关系
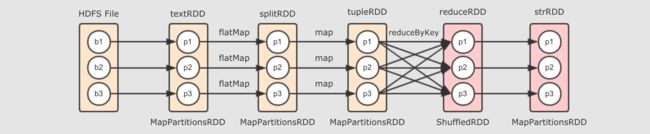
至此为止, 出现了两种分区见的关系了, 一种是一对一, 一种是多对一
整体上的流程图
-
一对一, 一般是直接转换
-
多对一, 一般是 Shuffle
本小节会说明如下问题:
-
如果分区间得关系是一对一或者多对一, 那么这种情况下的 RDD 之间的关系的正式命名是什么呢?
-
RDD 之间的依赖关系, 具体有几种情况呢?
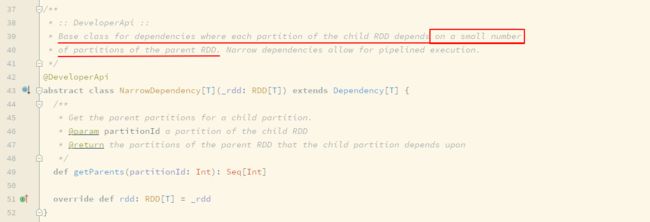
假如 rddB = rddA.transform(…), 如果 rddB 中一个分区依赖 rddA 也就是其父 RDD 的少量分区, 这种 RDD 之间的依赖关系称之为窄依赖
换句话说, 子 RDD 的每个分区依赖父 RDD 的少量个数的分区, 这种依赖关系称之为窄依赖
举个栗子
val sc = ...
val rddA = sc.parallelize(Seq(1, 2, 3))
val rddB = sc.parallelize(Seq("a", "b"))
/**
* 运行结果: (1,a), (1,b), (2,a), (2,b), (3,a), (3,b)
*/
rddA.cartesian(rddB).collect().foreach(println(_))-
上述代码的
cartesian是求得两个集合的笛卡尔积 -
上述代码的运行结果是
rddA中每个元素和rddB中的所有元素结合, 最终的结果数量是两个RDD数量之和 -
rddC有两个父RDD, 分别为rddA和rddB
对于 cartesian 来说, 依赖关系如下
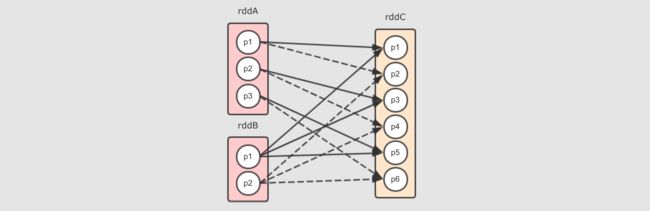
上述图形中清晰展示如下现象
-
rddC中的分区数量是两个父RDD的分区数量之乘积 -
rddA中每个分区对应rddC中的两个分区 (因为rddB中有两个分区),rddB中的每个分区对应rddC中的三个分区 (因为rddA有三个分区)
它们之间是窄依赖, 事实上在 cartesian 中也是 NarrowDependency 这个所有窄依赖的父类的唯一一次直接使用, 为什么呢?
因为所有的分区之间是拷贝关系, 并不是 Shuffle 关系
如何分辨宽窄依赖 ?
其实分辨宽窄依赖的本身就是在分辨父子 RDD 之间是否有 Shuffle, 大致有以下的方法
总结
但是这样判断其实不准确, 如果想分辨某个算子是否是窄依赖, 或者是否是宽依赖, 则还是要取决于具体的算子, 例如想看 cartesian 生成的是宽依赖还是窄依赖, 可以通过如下步骤
常见的窄依赖其实也是有分类的, 而且宽窄以来不太容易分辨, 所以通过本章, 帮助同学明确窄依赖的类型
-
rddC中的每个分区并不是依赖多个父RDD中的多个分区 -
rddC中每个分区的数量来自一个父RDD分区中的所有数据, 是一个FullDependence, 所以数据可以直接从父RDD流动到子RDD -
不存在一个父
RDD中一部分数据分发过去, 另一部分分发给其它的RDD -
宽依赖
并没有所谓的宽依赖, 宽依赖应该称作为
ShuffleDependency在
ShuffleDependency的类声明上如下写到Represents a dependency on the output of a shuffle stage.上面非常清楚的说道, 宽依赖就是
Shuffle中的依赖关系, 换句话说, 只有Shuffle产生的地方才是宽依赖那么宽窄依赖的判断依据就非常简单明确了, 是否有 Shuffle ?
举个
reduceByKey的例子,rddB = rddA.reduceByKey( (curr, agg) ⇒ curr + agg )会产生如下的依赖关系
-
rddB的每个分区都几乎依赖rddA的所有分区 -
对于
rddA中的一个分区来说, 其将一部分分发给rddB的p1, 另外一部分分发给rddB的p2, 这不是数据流动, 而是分发 -
如果是
Shuffle, 两个RDD的分区之间不是单纯的数据流动, 而是分发和复制 -
一般
Shuffle的子RDD的每个分区会依赖父RDD的多个分区 -
查看
map算子生成的RDD
-
进去
RDD查看getDependence方法
-
RDD 的逻辑图本质上是对于计算过程的表达, 例如数据从哪来, 经历了哪些步骤的计算
-
每一个步骤都对应一个 RDD, 因为数据处理的情况不同, RDD 之间的依赖关系又分为窄依赖和宽依赖 *
常见的窄依赖其实也是有分类的, 而且宽窄以来不太容易分辨, 所以通过本章, 帮助同学明确窄依赖的类型
- 一对一窄依赖
- 其实
RDD中默认的是OneToOneDependency, 后被不同的RDD子类指定为其它的依赖类型, 常见的一对一依赖是map算子所产生的依赖, 例如rddB = rddA.map(…)

每个分区之间一一对应, 所以叫做一对一窄依赖
- 2 Range 窄依赖
Range 窄依赖其实也是一对一窄依赖, 但是保留了中间的分隔信息, 可以通过某个分区获取其父分区, 目前只有一个算子生成这种窄依赖, 就是 union 算子, 例如 rddC = rddA.union(rddB)

- 3多对一窄依赖
多对一窄依赖其图形和 Shuffle 依赖非常相似, 所以在遇到的时候, 要注意其 RDD 之间是否有 Shuffle 过程, 比较容易让人困惑, 常见的多对一依赖就是重分区算子 coalesce, 例如 rddB = rddA.coalesce(2, shuffle = false), 但同时也要注意, 如果 shuffle = true 那就是完全不同的情况了

宽窄以来的核心区别是: 窄依赖的 RDD 可以放在一个 Task 中运行
再谈宽窄依赖的区别
宽窄依赖的区别非常重要, 因为涉及了一件非常重要的事情: 如何计算 RDD ?
-
rddC其实就是rddA拼接rddB生成的, 所以rddC的p5和p6就是rddB的p1和p2 -
所以需要有方式获取到
rddC的p5其父分区是谁, 于是就需要记录一下边界, 其它部分和一对一窄依赖一样 -
因为没有
Shuffle, 所以这是一个窄依赖
总结:RDD 之间的依赖关系不是指RDD 之间关系,而是分区之间的关系
如何RDD 的宽窄依赖关系 主要是看是否产生shuffle操作,如果有就是宽依赖,否则就是窄依赖