Tensorflow手写数字识别
一.MNIST数据集
当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
为了便于下载MNIST数据集,执行下面的python代码【需要提前安装好tensorflow】可以将该数据集下载到本地:
from tensorflow.examples.tutorials.mnist import input_data
# mn.SOURCE_URL = "http://yann.lecun.com/exdb/mnist/"
my_mnist = input_data.read_data_sets("C:/Users/Administrator/MNIST_data_bak/", one_hot=True)
下载下来的数据集被分为两部分:60000行的训练数据集【mnist.train】和10000行的测试数据集【mnist.test】。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不是用于训练模型,而是用于评估模型的性能,从而更加容易地把设计的模型推广到其它数据集上【泛化能力】。
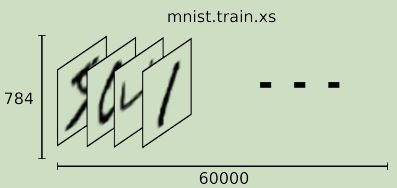
每一个MNIST数据单元由两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为xs,把这些标签设为ys。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是mnist.train.images,训练数据集的标签是mnist.train.labels。
每张图片包含2828个像素点。我们可以用一个数字数组来表示这张图片:
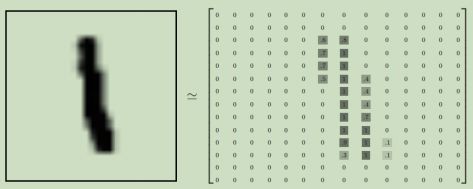
我们把这个数组展开成一个向量,长度是2828=784。如何展开这个数组【数字间的顺序】并不重要,只需保证各个图片的展开方式相同。从这个角度来看,MNIST数据集的图片就是在784维向量空间里面里面的点,并且拥有比较复杂的结构【此类数据的可视化是计算密集型】。
展开图片的数字数组会丢失图片的二维结构信息。这显然是不理想的,最优秀的计算机视觉方法会挖掘并利用这些结构信息。但在此处我们忽略这些结构,所介绍的简单数学模型,softmax回归【softmax regression】不会利用这些结构信息。
因此,在MNIST训练数据集中,mnist.train.images是一个形状为[60000, 784]的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,介于0~1之间。
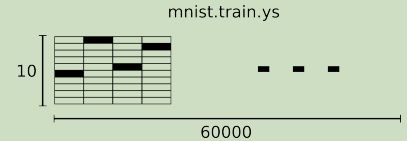
相对应的MNIST数据集的标签介于0~9之间的数字,用来描述给定图片里表示的数字。为了便于分析,我们把标签数据转换为one-hot编码向量。一个one-hot向量除了某一位的数字是1之外,其余各个维度数字都是0。因此,数字n将表示成一个只有在第n维度数字为1的10维向量。比如,标签0将表示为:[1,0,0,0,0,0,0,0,0,0]。因此,mnist.train.labels将是一个[60000,10]的数字矩阵。
二.Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9.我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%,但是判断它是8的概率是5%【8和9比较接近】,然后给予它代表其他数字更小的概率值。
这是一个使用softmax回归模型的经典案例。softmax模型可以用来给不同的对象分配概率。即使使用更加复杂的模型时,最后一步也需要用softmax来分配概率。
softmax回归模型分两步:
1.为了得到一张给定图片属于某个特定数字的证据,我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该数字,那么相应的权值为负数,否则权值为正值。
下面的图片显示了一个模型学习到的图片上每个像素对于特定数字的权值。红色代表负数权值,蓝色代表正数权值。

我们也需要加入一个额外的偏置量【bias】,因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片x它代表的是数字i的证据可以表示为:
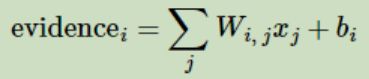
其中bi代表数字i的偏置量,j代表给定图片x的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率y:
![]()
这里的softmax可以看成是一个激励【activation】函数或者链接【link】函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为:
![]()
展开等式右边的子式,可以得到:

但是更多的时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型【hypothesis】里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0或者负值。Softmax会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:
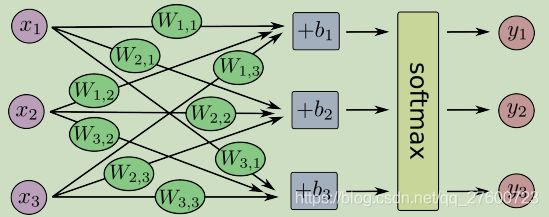
如果把它写成一个等式,我们可以得到:

我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。

更近一步,可以写成更加紧凑的方式:
![]()
三.实现回归模型
为了用python实现高效的数值计算,我们通常会使用函数库,比如NumPy,会把类似矩阵乘法这样复杂的运算使用其他外部语言实现。不幸的是,从外部计算切换回Python的每一个操作,仍然是一个很大的开销。如果你是使用的GPU来进行外部计算,这样的开销会更大。用分布式的计算方式,也会花费更多的资源用来传输数据。
TensorFlow也会把复杂的计算放在python之外完成,但是为了避免前面说的那些开销,它做了进一步的完善。TensorFlow不单独运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。
使用TensorfFlow之前,首先导入它:
import tensorflow as tf
我们通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder("float", [None, 784])
x不是一个特定的值,而是一个占位符placeholder,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展开成784维的向量。用2维的浮点数张量来表示这些图,这个张量的形状是【None, 784】。
备注:None表示此张量的第一个维度可以是任何长度的!
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入【使用占位符】,但TensorFlow有一个更好的方法来表示它们:Variable。一个Variable代表一个可修改的张量,存在在TensorFlow的用于描述交互式操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用Variable表示。
w = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
我们赋予tf.Variable不同的初值来创建不同的变量,在这里,我们都是用全为零的张量来初始化w和b的。因为我们要学习w和b的值,它们的初值可以随意设置。
注意,w的维度是【784,10】,因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同的数字。b的形状是【10】,所以我们可以直接把它加到输出上面。
现在,我们可以实现自己的模型,只需要一行代码:
y = tf.nn.softmax(tf.matmul(x, w) + b)
首先,我们用tf.matmul(x, w)表示x乘以w,对应之前等式里面的Wx,这里x是一个2维张量拥有多个输入。然后再加上b,把和输入到tf.nn.softmax函数里面。
至此,我们先用了几行简短的代码来设置变量,然后只使用 一行代码来定义我们的模型。TensorFlow不仅仅可以使softmax回归模型计算变得特别简单,它也用这种非常灵活的方式来描述其它各种数值计算,从机器学习模型到物理学模拟仿真模型。一旦被定义好之后,我们的模型就可以在不同的设备上运行:计算机的CPU/GPU,甚至是手机!
四.训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型的好坏。其实在机器学习领域,我们通常定义指标来表示一个模型的好坏程度,这个指标称为成本【cost】或损失【loss】,然后尽量最小化这个指标。
一个非常常见的,非常漂亮的成本函数是交叉熵【cross-entropy】。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其它领域里的重要技术手段。它的定义如下:

y是我们预测的概率分布,y`是实际的分布【我们输入的one-hot vector】。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None, 10])
然后我们可以用:
![]()
计算交叉熵:
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
首先,用tf.log计算y的每个元素的对数。接下来,我们把y_的每一个元素和tf.log(y)的对应元素相乘。最后,用tf.reduce_sum计算张量的所有元素的总和【这里交叉熵不仅仅用来衡量单一的一对预测和实际值,而是所有100张图片的交叉熵的总和】。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型性能。
TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法【backpropagation algorithm】来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
train_step = tf.train.GradientDescentOptimizer(0.01).mininize(cross_entropy)
在这里,我们要求TensorFlow用梯度下降算法【gradient descent algorithm】以0.01的学习速率最小化交叉熵。梯度下降算法是一个简单的学习过程,TensorFlow只需将每个变量一点点地往成本减小的方向移动。当然TensorFlow也提供了其他优化算法,只要简单地调整一行代码就可以使用其他的算法。
TensorFlow在这里实际上的做法是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减小成本。
现在,我们已经设置好了我们的模型。在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variable()
现在我们可以在一个Session里面启动我们的模型,并且初始化变量:
sess = tf.Session()
sess.run(init)
然后开始训练模型,这里我们让模型循环训练100次:
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_:batch_ys})
该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行train_step。
使用一小部分的随机数据来进行训练被称为随机训练【stochastic training】,在这里更确切的说是随机梯度下降训练。在理想状态下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一步训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以更大化地学习到数据集的总体特性。
五.模型评估
那么我们的模型性能如何呢?
首先让我们找到那些预测正确的标签。tf.argmax是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成的,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而tf.argmax(y_,1)代表正确的标签,我们可以用tf.equal来检测我们的预测是否与真实标签匹配。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,【True,False,True,True】会变成【1,0,1,1】,取平均值后得到0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
最后,我们计算所学习到的模型在测试数据集上面的正确率如下:
print("TestSet acc : %s" % accuracy.eval({x: my_mnist.test.images, y_: my_mnist.test.labels}))
这个最终结果值大概为88%。
六.保存与加载模型
TensoFlow提供了Saver来保存和加载训练好的模型,分别使用save【保存模型】和restore【加载模型】来操作模型。
首先,创建一个saver:
# 创建Saver节点,用于保存训练的模型
saver = tf.train.Saver()
保存模型:
save_path = saver.save(sess, "C:/Users/Administrator/MNIST_data_bak/saver/softmax_middle_model.ckpt")
加载模型:
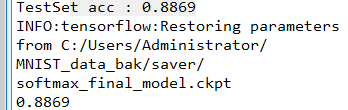
saver.restore(sess_back, "C:/Users/Administrator/MNIST_data_bak/saver/softmax_final_model.ckpt")
保存和加载模型对机器学习算法具有极其重要的作用,常见的预测功能所用到的模型几乎都是提前训练好保存下来的,在需要预测时直接加载模型进行预测,再需要时重新训练模型并保存。
七.完整代码
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 16 19:04:35 2020
@author: Administrator
"""
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
# mn.SOURCE_URL = "http://yann.lecun.com/exdb/mnist/"
my_mnist = input_data.read_data_sets("C:/Users/Administrator/MNIST_data_bak/", one_hot=True)
# The MNIST data is split into three parts:
# 55,000 data points of training data (mnist.train)
# 10,000 points of test data (mnist.test), and
# 5,000 points of validation data (mnist.validation).
# Each image is 28 pixels by 28 pixels
# 输入的是一堆图片,None表示不限输入条数,784表示每张图片都是一个784个像素值的一维向量
# 所以输入的矩阵是None乘以784二维矩阵
x = tf.placeholder(dtype=tf.float32, shape=(None, 784))
# 初始化都是0,二维矩阵784乘以10个W值
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 训练
# labels是每张图片都对应一个one-hot的10个值的向量
y_ = tf.placeholder(dtype=tf.float32, shape=(None, 10))
# 定义损失函数,交叉熵损失函数
# 对于多分类问题,通常使用交叉熵损失函数
# reduction_indices等价于axis,指明按照每行加,还是按照每列加
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 评估
# tf.argmax()是一个从tensor中寻找最大值的序号,tf.argmax就是求各个预测的数字中概率最大的那一个
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 用tf.cast将之前correct_prediction输出的bool值转换为float32,再求平均
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化变量
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# 创建Saver节点,用于保存训练的模型
saver = tf.train.Saver()
for i in range(100):
batch_xs, batch_ys = my_mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 每隔一段时间保存一次中间结果
if i % 10 == 0:
save_path = saver.save(sess, "C:/Users/Administrator/MNIST_data_bak/saver/softmax_middle_model.ckpt")
# 测试
print("TestSet acc : %s" % accuracy.eval({x: my_mnist.test.images, y_: my_mnist.test.labels}))
# 保存最终的模型
save_path = saver.save(sess, "C:/Users/Administrator/MNIST_data_bak/saver/softmax_final_model.ckpt")
# 使用训练好的模型直接进行预测
with tf.Session() as sess_back:
saver.restore(sess_back, "C:/Users/Administrator/MNIST_data_bak/saver/softmax_final_model.ckpt")
# 评估
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accruary = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 测试
print(accuracy.eval({x : my_mnist.test.images, y_ : my_mnist.test.labels}))
执行结果: