pytorch-模型训练中过拟合和欠拟合问题。从模型复杂度和数据集大小排查问题
-
评价了机器学习模型在训练数据集和测试数据集上的表现。如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不一定更准确。这是为什么呢?
-
训练误差和泛化误差
- 在解释上述现象之前,需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平方损失函数和softmax回归用到的交叉熵损失函数。
- 让我们以高考为例来直观地解释训练误差和泛化误差这两个概念。训练误差可以认为是做往年高考试题(训练题)时的错误率,泛化误差则可以通过真正参加高考(测试题)时的答题错误率来近似。假设训练题和测试题都随机采样于一个未知的依照相同考纲的巨大试题库。如果让一名未学习中学知识的小学生去答题,那么测试题和训练题的答题错误率可能很相近。但如果换成一名反复练习训练题的高三备考生答题,即使在训练题上做到了错误率为0,也不代表真实的高考成绩会如此。
-
在机器学习里,通常假设训练数据集(训练题)和测试数据集(测试题)里的每一个样本都是从同一个概率分布中相互独立地生成的。基于该独立同分布假设,给定任意一个机器学习模型(含参数),它的训练误差的期望和泛化误差都是一样的。
- 例如,如果我们将模型参数设成随机值(小学生),那么训练误差和泛化误差会非常相近。模型的参数是通过在训练数据集上训练模型而学习出的,参数的选择依据了最小化训练误差(高三备考生)。所以,训练误差的期望小于或等于泛化误差。也就是说,一般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。
-
机器学习模型应关注降低泛化误差。
模型选择
- 在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这一过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。为了得到有效的模型,我们通常要在模型选择上下一番功夫。下面,我们来描述模型选择中经常使用的验证数据集(validation data set)。
- 验证数据集
- 从严格意义上讲,测试集只能在所有超参数和模型参数选定后使用一次。不可以使用测试数据选择模型,如调参。由于无法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
- 然而在实际应用中,由于数据不容易获取,测试数据极少只使用一次就丢弃。因此,实践中验证数据集和测试数据集的界限可能比较模糊。从严格意义上讲,除非明确说明,否则本书中实验所使用的测试集应为验证集,实验报告的测试结果(如测试准确率)应为验证结果(如验证准确率)。
K折交叉验证
- 由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
欠拟合和过拟合
-
探究模型训练中经常出现的两类典型问题:
-
一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);
-
另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。
-
-
在实践中,要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。
-
模型复杂度
-
为了解释模型复杂度,我们以多项式函数拟合为例。给定一个由标量数据特征x和对应的标量标签y组成的训练数据集,多项式函数拟合的目标是找一个K阶多项式函数
-
y ^ = b + ∑ k = 1 K x k w k \hat{y} = b + \sum_{k=1}^K x^k w_k y^=b+k=1∑Kxkwk
-
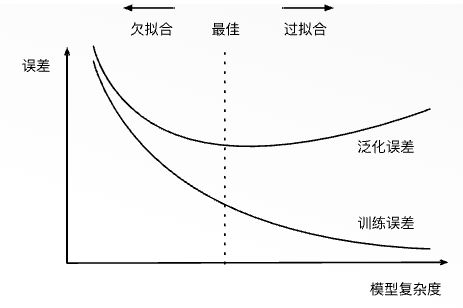
来近似 y y y。在上式中, w k w_k wk是模型的权重参数, b b b是偏差参数。与线性回归相同,多项式函数拟合也使用平方损失函数。特别地,一阶多项式函数拟合又叫线性函数拟合。因为高阶多项式函数模型参数更多,模型函数的选择空间更大,所以高阶多项式函数比低阶多项式函数的复杂度更高。因此,高阶多项式函数比低阶多项式函数更容易在相同的训练数据集上得到更低的训练误差。给定训练数据集,模型复杂度和误差之间的关系通常如下图所示。给定训练数据集,如果模型的复杂度过低,很容易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的一个办法是针对数据集选择合适复杂度的模型。
-
-
-
训练数据集大小
- 影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
多项式函数拟合实验
-
生成数据集
- 将生成一个人工数据集。在训练数据集和测试数据集中,给定样本特征 x x x,使用如下的三阶多项式函数来生成该样本的标签: y = 1.2 x − 3.4 x 2 + 5.6 x 3 + 5 + ϵ y = 1.2x - 3.4x^2 + 5.6x^3 + 5 + \epsilon y=1.2x−3.4x2+5.6x3+5+ϵ,其中噪声项 ϵ \epsilon ϵ服从均值为0、标准差为0.01的正态分布。训练数据集和测试数据集的样本数都设为100。
-
%matplotlib inline import torch import numpy as np import sys n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5 features = torch.randn((n_train + n_test, 1)) poly_features = torch.cat((features, torch.pow(features, 2), torch.pow(features, 3)), 1) labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1] + true_w[2] * poly_features[:, 2] + true_b) labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float) print(features[:2], poly_features[:2], labels[:2]) # 查看前两个样本信息 -
tensor([[-1.6202], [-0.5634]]) tensor([[-1.6202, 2.6250, -4.2531], [-0.5634, 0.3174, -0.1788]]) tensor([-29.6964, 2.2427]) - 数据可视化展示
-
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.figure(figsize=(5, 5), dpi=100) plt.scatter(features, labels, c='blue') plt.xlabel("自变量") plt.ylabel("因变量") plt.show() 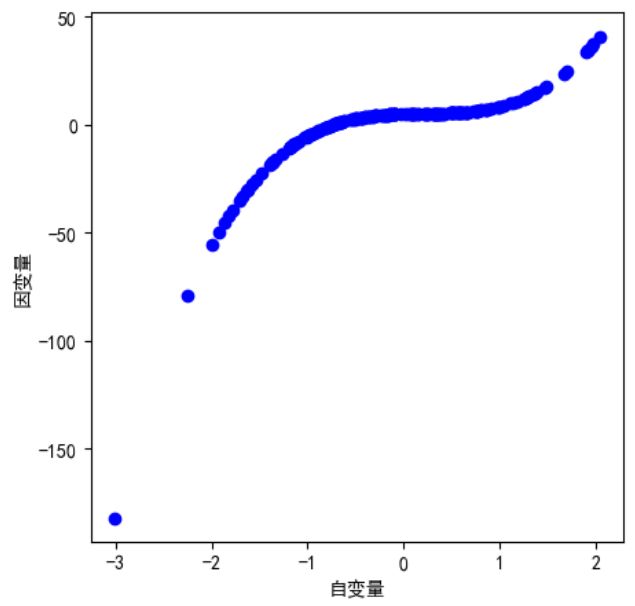
定义、训练和测试模型
-
先定义作图函数
semilogy,其中 y 轴使用了对数尺度。 -
from IPython import display def use_svg_display(): # 用矢量图显示 display.display_svg() def set_figsize(figsize=(3.5, 2.5)): use_svg_display() # 设置图的尺寸 plt.rcParams['figure.figsize'] = figsize def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None, legend=None, figsize=(3.5, 2.5)): set_figsize(figsize) plt.xlabel(x_label) plt.ylabel(y_label) plt.semilogy(x_vals, y_vals) if x2_vals and y2_vals: plt.semilogy(x2_vals, y2_vals, linestyle=':') plt.legend(legend) -
和线性回归一样,多项式函数拟合也使用平方损失函数。尝试使用不同复杂度的模型来拟合生成的数据集,所以我们把模型定义部分放在
fit_and_plot函数中。 -
num_epochs, loss = 100, torch.nn.MSELoss() def fit_and_plot(train_features, test_features, train_labels, test_labels): net = torch.nn.Linear(train_features.shape[-1], 1) # 通过Linear文档可知,pytorch已经将参数初始化了,所以我们这里就不手动初始化了 batch_size = min(10, train_labels.shape[0]) dataset = torch.utils.data.TensorDataset(train_features, train_labels) train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) optimizer = torch.optim.SGD(net.parameters(), lr=0.01) train_ls, test_ls = [], [] for _ in range(num_epochs): for X, y in train_iter: l = loss(net(X), y.view(-1, 1)) optimizer.zero_grad() l.backward() optimizer.step() train_labels = train_labels.view(-1, 1) test_labels = test_labels.view(-1, 1) train_ls.append(loss(net(train_features), train_labels).item()) test_ls.append(loss(net(test_features), test_labels).item()) print('final epoch: train loss', train_ls[-1], 'test loss', test_ls[-1]) semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss', range(1, num_epochs + 1), test_ls, ['train', 'test']) print('weight:', net.weight.data, '\nbias:', net.bias.data)
三阶多项式函数拟合(正常)
-
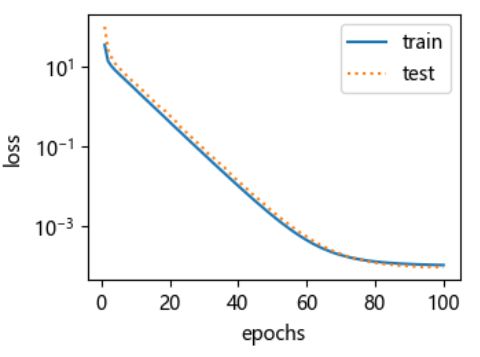
先使用与数据生成函数同阶的三阶多项式函数拟合。实验表明,这个模型的训练误差和在测试数据集的误差都较低。训练出的模型参数也接近真实值: w 1 = 1.2 , w 2 = − 3.4 , w 3 = 5.6 , b = 5 w_1 = 1.2, w_2=-3.4, w_3=5.6, b = 5 w1=1.2,w2=−3.4,w3=5.6,b=5。
-
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :], labels[:n_train], labels[n_train:]) -
final epoch: train loss 0.0001002745411824435 test loss 8.844204421620816e-05 weight: tensor([[ 1.1969, -3.3979, 5.6006]]) bias: tensor([4.9976]) -
线性函数拟合(欠拟合)
-
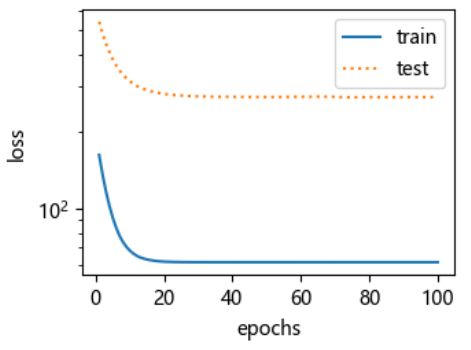
试试线性函数拟合。很明显,该模型的训练误差在迭代早期下降后便很难继续降低。在完成最后一次迭代周期后,训练误差依旧很高。线性模型在非线性模型(如三阶多项式函数)生成的数据集上容易欠拟合。
-
fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train],labels[n_train:]) -
final epoch: train loss 61.378780364990234 test loss 273.34600830078125 weight: tensor([[12.6879]]) bias: tensor([2.6623]) -
训练样本不足(过拟合)
-
事实上,即便使用与数据生成模型同阶的三阶多项式函数模型,如果训练样本不足,该模型依然容易过拟合。让我们只使用两个样本来训练模型。显然,训练样本过少了,甚至少于模型参数的数量。这使模型显得过于复杂,以至于容易被训练数据中的噪声影响。在迭代过程中,尽管训练误差较低,但是测试数据集上的误差却很高。这是典型的过拟合现象。
-
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2],labels[n_train:]) -
final epoch: train loss 1.659356713294983 test loss 171.44386291503906 weight: tensor([[1.2923, 1.4181, 3.3863]]) bias: tensor([3.1349]) -
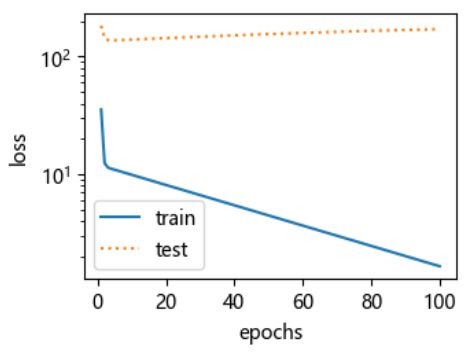
-
由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。机器学习模型应关注降低泛化误差。可以使用验证数据集来进行模型选择。欠拟合指模型无法得到较低的训练误差,过拟合指模型的训练误差远小于它在测试数据集上的误差。应选择复杂度合适的模型并避免使用过少的训练样本。
权重衰减,正则化
- 观察了过拟合现象,即模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。应对过拟合问题的常用方法:权重衰减(weight decay)。
- 权重衰减等价于 L 2 L_2 L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。先描述L_2范数正则化,再解释它为何又称权重衰减。
- L 2 L_2 L2范数正则化在模型原损失函数基础上添加 L 2 L_2 L2范数惩罚项,从而得到训练所需要最小化的函数。 L 2 L_2 L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以线性回归中的线性回归损失函数为例:
- ℓ ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n 1 2 ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) 2 \ell(w_1, w_2, b) = \frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2 ℓ(w1,w2,b)=n1i=1∑n21(x1(i)w1+x2(i)w2+b−y(i))2
- 其中 w 1 , w 2 w_1, w_2 w1,w2是权重参数,b是偏差参数,样本i的输入为 x 1 ( i ) , x 2 ( i ) x_1^{(i)}, x_2^{(i)} x1(i),x2(i),标签为 y ( i ) y^{(i)} y(i),样本数为n。将权重参数用向量 w = [ w 1 , w 2 ] \boldsymbol{w} = [w_1, w_2] w=[w1,w2]表示,带有L_2范数惩罚项的新损失函数为
- ℓ ( w 1 , w 2 , b ) + λ 2 n ∥ w ∥ 2 \ell(w_1, w_2, b) + \frac{\lambda}{2n} \|\boldsymbol{w}\|^2 ℓ(w1,w2,b)+2nλ∥w∥2
- 其中超参数 λ > 0 \lambda > 0 λ>0。当权重参数均为0时,惩罚项最小。当 λ \lambda λ较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当 λ \lambda λ设为0时,惩罚项完全不起作用。上式中 L 2 L_2 L2范数平方 ∣ w ∣ 2 |\boldsymbol{w}|^2 ∣w∣2展开后得到 w 1 2 + w 2 2 w_1^2 + w_2^2 w12+w22。有了 L 2 L_2 L2范数惩罚项后,在小批量随机梯度下降中,将线性回归一节中权重 w 1 w_1 w1和 w 2 w_2 w2的迭代方式更改为
- w 1 ← ( 1 − η λ ∣ B ∣ ) w 1 − η ∣ B ∣ ∑ i ∈ B x 1 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) , w 2 ← ( 1 − η λ ∣ B ∣ ) w 2 − η ∣ B ∣ ∑ i ∈ B x 2 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) . \begin{aligned} w_1 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\ w_2 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right). \end{aligned} w1w2←(1−∣B∣ηλ)w1−∣B∣ηi∈B∑x1(i)(x1(i)w1+x2(i)w2+b−y(i)),←(1−∣B∣ηλ)w2−∣B∣ηi∈B∑x2(i)(x1(i)w1+x2(i)w2+b−y(i)).
- 可见, L 2 L_2 L2范数正则化令权重 w 1 w_1 w1和 w 2 w_2 w2先自乘小于1的数,再减去不含惩罚项的梯度。因此, L 2 L_2 L2范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,有时也在惩罚项中添加偏差元素的平方和。
高维线性回归实验
-
以高维线性回归为例来引入一个过拟合问题,并使用权重衰减来应对过拟合。设数据样本特征的维度为p。对于训练数据集和测试数据集中特征为 x 1 , x 2 , … , x p x_1, x_2, \ldots, x_p x1,x2,…,xp的任一样本,使用如下的线性函数来生成该样本的标签:
- y = 0.05 + ∑ i = 1 p 0.01 x i + ϵ y = 0.05 + \sum_{i = 1}^p 0.01x_i + \epsilon y=0.05+i=1∑p0.01xi+ϵ
-
其中噪声项 ϵ \epsilon ϵ服从均值为0、标准差为0.01的正态分布。为了较容易地观察过拟合,考虑高维线性回归问题,如设维度p=200;同时,特意把训练数据集的样本数设低,如20。
-
%matplotlib inline import torch import torch.nn as nn import numpy as np import sys n_train, n_test, num_inputs = 20, 100, 200 true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05 features = torch.randn((n_train + n_test, num_inputs)) labels = torch.matmul(features, true_w) + true_b labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float) train_features, test_features = features[:n_train, :], features[n_train:, :] train_labels, test_labels = labels[:n_train], labels[n_train:] print(features.size()) print(labels[:3]) print(train_features.size()) print(test_features.size()) -
torch.Size([120, 200]) tensor([[0.0141], [0.2036], [0.1064]]) torch.Size([20, 200]) torch.Size([100, 200])
-
初始化模型参数,定义 L 2 L_2 L2范数惩罚项
-
从零开始实现权重衰减的方法。我们通过在目标函数后添加L_2范数惩罚项来实现权重衰减。首先,定义随机初始化模型参数的函数。该函数为每个参数都附上梯度。定义 L 2 L_2 L2范数惩罚项。这里只惩罚模型的权重参数。
-
def init_params(): w = torch.randn((num_inputs, 1), requires_grad=True) b = torch.zeros(1, requires_grad=True) return [w, b] def l2_penalty(w): return (w**2).sum() / 2
定义训练和测试
-
下面定义如何在训练数据集和测试数据集上分别训练和测试模型。这里在计算最终的损失函数时添加了L_2范数惩罚项。
-
import matplotlib.pyplot as plt def linreg(X, w, b): return torch.mm(X, w) + b def squared_loss(y_hat, y): # 注意这里返回的是向量, 另外, pytorch里的MSELoss并没有除以 2 return ((y_hat - y.view(y_hat.size())) ** 2) / 2 batch_size, num_epochs, lr = 1, 100, 0.003 net, loss = linreg, squared_loss dataset = torch.utils.data.TensorDataset(train_features, train_labels) train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) def sgd(params, lr, batch_size): # 为了和原书保持一致,这里除以了batch_size,但是应该是不用除的,因为一般用PyTorch计算loss时就默认已经 # 沿batch维求了平均了。 for param in params: param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data from IPython import display def use_svg_display(): # 用矢量图显示 display.display_svg() def set_figsize(figsize=(3.5, 2.5)): use_svg_display() # 设置图的尺寸 plt.rcParams['figure.figsize'] = figsize def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None, legend=None, figsize=(3.5, 2.5)): set_figsize(figsize) plt.xlabel(x_label) plt.ylabel(y_label) plt.semilogy(x_vals, y_vals) if x2_vals and y2_vals: plt.semilogy(x2_vals, y2_vals, linestyle=':') plt.legend(legend) def fit_and_plot(lambd): w, b = init_params() train_ls, test_ls = [], [] for _ in range(num_epochs): for X, y in train_iter: # 添加了L2范数惩罚项 l = loss(net(X, w, b), y) + lambd * l2_penalty(w) l = l.sum() if w.grad is not None: w.grad.data.zero_() b.grad.data.zero_() l.backward() sgd([w, b], lr, batch_size) train_ls.append(loss(net(train_features, w, b), train_labels).mean().item()) test_ls.append(loss(net(test_features, w, b), test_labels).mean().item()) semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss', range(1, num_epochs + 1), test_ls, ['train', 'test']) print('L2 norm of w:', w.norm().item()) -
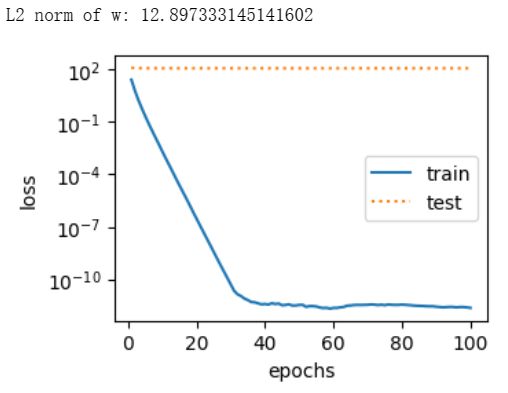
接下来,让我们训练并测试高维线性回归模型。当
lambd设为0时,我们没有使用权重衰减。结果训练误差远小于测试集上的误差。这是典型的过拟合现象。 -
fit_and_plot(lambd=0) -
使用权重衰减
-
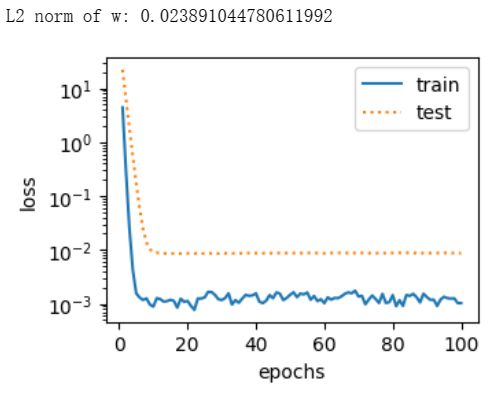
下面我们使用权重衰减。可以看出,训练误差虽然有所提高,但测试集上的误差有所下降。过拟合现象得到一定程度的缓解。另外,权重参数的 L 2 L_2 L2范数比不使用权重衰减时的更小,此时的权重参数更接近0。
-
fit_and_plot(lambd=10) -
用pytorch简洁实现一下权重衰减
-
%matplotlib inline import torch import torch.nn as nn import numpy as np import matplotlib.pyplot as plt from IPython import display def linreg(X, w, b): return torch.mm(X, w) + b def squared_loss(y_hat, y): # 注意这里返回的是向量, 另外, pytorch里的MSELoss并没有除以 2 return ((y_hat - y.view(y_hat.size())) ** 2) / 2 def use_svg_display(): # 用矢量图显示 display.display_svg() def set_figsize(figsize=(3.5, 2.5)): use_svg_display() # 设置图的尺寸 plt.rcParams['figure.figsize'] = figsize def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None, legend=None, figsize=(3.5, 2.5)): set_figsize(figsize) plt.xlabel(x_label) plt.ylabel(y_label) plt.semilogy(x_vals, y_vals) if x2_vals and y2_vals: plt.semilogy(x2_vals, y2_vals, linestyle=':') plt.legend(legend) n_train, n_test, num_inputs = 20, 100, 200 true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05 features = torch.randn((n_train + n_test, num_inputs)) labels = torch.matmul(features, true_w) + true_b labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float) train_features, test_features = features[:n_train, :], features[n_train:, :] train_labels, test_labels = labels[:n_train], labels[n_train:] batch_size, num_epochs, lr = 1, 100, 0.003 net, loss = linreg, squared_loss dataset = torch.utils.data.TensorDataset(train_features, train_labels) train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) def fit_and_plot_pytorch(wd): # 对权重参数衰减。权重名称一般是以weight结尾 net = nn.Linear(num_inputs, 1) nn.init.normal_(net.weight, mean=0, std=1) nn.init.normal_(net.bias, mean=0, std=1) optimizer_w = torch.optim.SGD(params=[net.weight], lr=lr, weight_decay=wd) # 对权重参数衰减 optimizer_b = torch.optim.SGD(params=[net.bias], lr=lr) # 不对偏差参数衰减 train_ls, test_ls = [], [] for _ in range(num_epochs): for X, y in train_iter: l = loss(net(X), y).mean() optimizer_w.zero_grad() optimizer_b.zero_grad() l.backward() # 对两个optimizer实例分别调用step函数,从而分别更新权重和偏差 optimizer_w.step() optimizer_b.step() train_ls.append(loss(net(train_features), train_labels).mean().item()) test_ls.append(loss(net(test_features), test_labels).mean().item()) semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss', range(1, num_epochs + 1), test_ls, ['train', 'test']) print('L2 norm of w:', net.weight.data.norm().item()) -
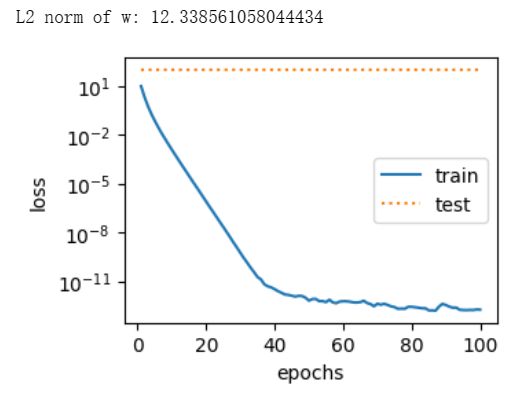
与从零开始实现权重衰减的实验现象类似,使用权重衰减可以在一定程度上缓解过拟合问题。
-
fit_and_plot_pytorch(0) -
-
fit_and_plot_pytorch(10) -
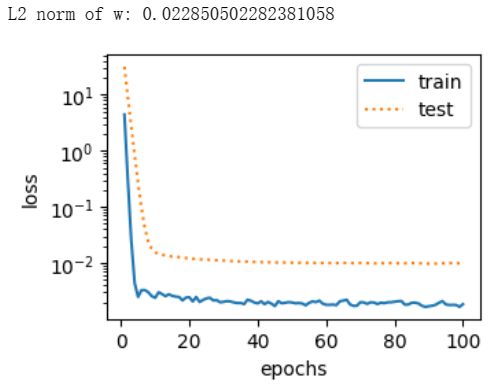
-
正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。权重衰减等价于 L 2 L_2 L2范数正则化,通常会使学到的权重参数的元素较接近0。权重衰减可以通过优化器中的
weight_decay超参数来指定。可以定义多个优化器实例对不同的模型参数使用不同的迭代方法。
dropout
- 除了前文介绍的权重衰减以外,深度学习模型常常使用丢弃法(dropout)来应对过拟合问题。丢弃法有一些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
- 一个单隐藏层的多层感知机。其中输入个数为4,隐藏单元个数为5,且隐藏单元 h i ( i = 1 , … , 5 ) h_i(i=1, \ldots, 5) hi(i=1,…,5)的计算表达式为
- h i = ϕ ( x 1 w 1 i + x 2 w 2 i + x 3 w 3 i + x 4 w 4 i + b i ) h_i = \phi\left(x_1 w_{1i} + x_2 w_{2i} + x_3 w_{3i} + x_4 w_{4i} + b_i\right) hi=ϕ(x1w1i+x2w2i+x3w3i+x4w4i+bi)
- 这里 ϕ \phi ϕ是激活函数, x 1 , … , x 4 x_1, \ldots, x_4 x1,…,x4是输入,隐藏单元i的权重参数为 w 1 i , … , w 4 i w_{1i}, \ldots, w_{4i} w1i,…,w4i,偏差参数为 b i b_i bi。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为p,那么有p的概率 h i h_i hi会被清零,有1-p的概率 h i h_i hi会除以1-p做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量 ξ i \xi_i ξi为0和1的概率分别为p和1-p。使用丢弃法时我们计算新的隐藏单元 h i ′ h_i' hi′.
- h i ′ = ξ i 1 − p h i h_i' = \frac{\xi_i}{1-p} h_i hi′=1−pξihi
- 即丢弃法不改变其输入的期望值。让我们对全连接多层感知机的隐藏层使用丢弃法,一种可能的结果如下图所示,其中 h 2 h_2 h2和 h 5 h_5 h5被清零。这时输出值的计算不再依赖 h 2 h_2 h2和 h 5 h_5 h5,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即 h 1 , … , h 5 h_1, \ldots, h_5 h1,…,h5都有可能被清零,输出层的计算无法过度依赖 h 1 , … , h 5 h_1, \ldots, h_5 h1,…,h5中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,为了拿到更加确定性的结果,一般不使用丢弃法。
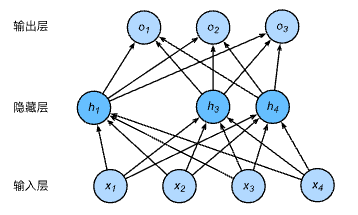
从零开始实现
-
根据丢弃法的定义,可以很容易地实现它。下面的
dropout函数将以drop_prob的概率丢弃X中的元素。-
%matplotlib inline import torch import torch.nn as nn import numpy as np import sys def dropout(X, drop_prob): X = X.float() assert 0 <= drop_prob <= 1 keep_prob = 1 - drop_prob # 这种情况下把全部元素都丢弃 if keep_prob == 0: return torch.zeros_like(X) mask = (torch.rand(X.shape) < keep_prob).float() return mask * X / keep_prob X = torch.arange(16).view(2, 8) print(X) print(dropout(X, 0)) print(X) print(dropout(X, 0.5)) print(X) print(dropout(X, 1.0)) -
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7], [ 8, 9, 10, 11, 12, 13, 14, 15]]) tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.], [ 8., 9., 10., 11., 12., 13., 14., 15.]]) tensor([[ 0, 1, 2, 3, 4, 5, 6, 7], [ 8, 9, 10, 11, 12, 13, 14, 15]]) tensor([[ 0., 0., 4., 0., 0., 0., 12., 0.], [16., 18., 0., 22., 0., 0., 0., 0.]]) tensor([[ 0, 1, 2, 3, 4, 5, 6, 7], [ 8, 9, 10, 11, 12, 13, 14, 15]]) tensor([[0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0.]])0.]])
-
定义模型参数
-
实验中,我们依然使用oftmax回归的从零开始实现中介绍的Fashion-MNIST数据集。将定义一个包含两个隐藏层的多层感知机,其中两个隐藏层的输出个数都是256。
-
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256 W1 = torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens1)), dtype=torch.float, requires_grad=True) b1 = torch.zeros(num_hiddens1, requires_grad=True) W2 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens1, num_hiddens2)), dtype=torch.float, requires_grad=True) b2 = torch.zeros(num_hiddens2, requires_grad=True) W3 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens2, num_outputs)), dtype=torch.float, requires_grad=True) b3 = torch.zeros(num_outputs, requires_grad=True) params = [W1, b1, W2, b2, W3, b3] print(params) -
[tensor([[-0.0042, 0.0016, 0.0024, ..., 0.0026, 0.0105, 0.0017], [-0.0113, 0.0023, -0.0144, ..., -0.0174, -0.0008, 0.0055], [ 0.0047, 0.0011, -0.0046, ..., -0.0238, 0.0035, -0.0063], ..., [-0.0028, -0.0002, -0.0076, ..., -0.0077, -0.0009, -0.0114], [ 0.0021, -0.0045, 0.0017, ..., -0.0055, 0.0109, -0.0059], [-0.0021, 0.0059, -0.0033, ..., -0.0065, -0.0038, 0.0185]], requires_grad=True), tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True), tensor([[ 1.0939e-02, -1.8516e-02, 3.8669e-03, ..., -1.4012e-03, 4.9610e-05, -6.4754e-04], [-1.5593e-03, -2.6165e-03, 1.1370e-02, ..., -8.5307e-03, -5.3400e-03, 5.9022e-03], [ 3.0634e-03, -1.2666e-02, -3.4220e-05, ..., -5.6553e-03, -2.2074e-03, -1.1789e-04], ..., [-1.3904e-02, 1.0967e-02, -1.0648e-02, ..., 1.7149e-03, -3.6021e-03, 8.9331e-03], [-9.0771e-03, -1.1149e-03, 8.7311e-03, ..., -1.0729e-02, 6.7715e-03, 3.3234e-03], [ 5.8998e-04, 6.2236e-03, 1.8792e-02, ..., -1.9477e-02, -4.5627e-03, -3.6379e-03]], requires_grad=True), tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True), tensor([[-1.1877e-02, -1.3345e-03, 1.4353e-02, ..., -2.5003e-03, -8.5341e-03, -1.6275e-02], [-1.0287e-02, -1.4917e-03, 1.1750e-02, ..., 6.2379e-03, -6.4722e-03, 9.2133e-04], [ 5.6600e-03, -2.2251e-03, 7.6478e-03, ..., -1.3022e-03, -9.7004e-03, 5.7069e-03], ..., [ 1.0432e-02, -4.2755e-03, 4.0952e-05, ..., 5.2253e-03, 1.2151e-02, 9.1634e-03], [-2.3306e-03, 1.1782e-02, 1.1487e-02, ..., 1.1665e-02, -1.0554e-02, -1.0907e-02], [ 3.4083e-03, 1.8301e-02, 1.4351e-02, ..., -6.9886e-04, 2.9492e-03, -4.1226e-03]], requires_grad=True), tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)]
定义模型
-
模型将全连接层和激活函数ReLU串起来,并对每个激活函数的输出使用丢弃法。可以分别设置各个层的丢弃概率。通常的建议是把靠近输入层的丢弃概率设得小一点。在这个实验中,把第一个隐藏层的丢弃概率设为0.2,把第二个隐藏层的丢弃概率设为0.5。可以通过参数
is_training来判断运行模式为训练还是测试,并只需在训练模式下使用丢弃法。 -
drop_prob1, drop_prob2 = 0.2, 0.5 def net(X, is_training=True): X = X.view(-1, num_inputs) H1 = (torch.matmul(X, W1) + b1).relu() if is_training: # 只在训练模型时使用丢弃法 H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层 H2 = (torch.matmul(H1, W2) + b2).relu() if is_training: H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层 return torch.matmul(H2, W3) + b3 def evaluate_accuracy(data_iter, net): acc_sum, n = 0.0, 0 for X, y in data_iter: if isinstance(net, torch.nn.Module): net.eval() # 评估模式, 这会关闭dropout acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() net.train() # 改回训练模式 else: # 自定义的模型 if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数 # 将is_training设置成False acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item() else: acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() n += y.shape[0] return acc_sum / n
训练和测试模型
-
这部分与之前多层感知机的训练和测试类似。pytorch-多层感知机,最简单的深度学习模型,将非线性激活函数引入到模型中。_羞儿的博客-CSDN博客
-
import torch import torchvision import numpy as np import sys def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'): """Download the fashion mnist dataset and then load into memory.""" trans = [] if resize: trans.append(torchvision.transforms.Resize(size=resize)) trans.append(torchvision.transforms.ToTensor()) transform = torchvision.transforms.Compose(trans) mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform) mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform) if sys.platform.startswith('win'): num_workers = 0 # 0表示不用额外的进程来加速读取数据 else: num_workers = 4 train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers) return train_iter, test_iter def sgd(params, lr, batch_size): for param in params: param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, optimizer=None): for epoch in range(num_epochs): train_l_sum, train_acc_sum, n = 0.0, 0.0, 0 for X, y in train_iter: y_hat = net(X) l = loss(y_hat, y).sum() # 梯度清零 if optimizer is not None: optimizer.zero_grad() elif params is not None and params[0].grad is not None: for param in params: param.grad.data.zero_() l.backward() if optimizer is None: sgd(params, lr, batch_size) else: optimizer.step() # “softmax回归的简洁实现”一节将用到 train_l_sum += l.item() train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item() n += y.shape[0] test_acc = evaluate_accuracy(test_iter, net) print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc)) num_epochs, lr, batch_size = 5, 100.0, 256 loss = torch.nn.CrossEntropyLoss() train_iter, test_iter = load_data_fashion_mnist(batch_size) train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr) -
epoch 1, loss 0.0023, train acc 0.782, test acc 0.772 epoch 2, loss 0.0019, train acc 0.820, test acc 0.831 epoch 3, loss 0.0018, train acc 0.838, test acc 0.817 epoch 4, loss 0.0017, train acc 0.846, test acc 0.850 epoch 5, loss 0.0016, train acc 0.854, test acc 0.838 -
from IPython import display from matplotlib import pyplot as plt def get_fashion_mnist_labels(labels): text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'] return [text_labels[int(i)] for i in labels] def use_svg_display(): # 用矢量图显示 display.display_svg() def show_fashion_mnist(images, labels): use_svg_display() # 这里的_表示我们忽略(不使用)的变量 _, figs = plt.subplots(1, len(images), figsize=(12, 12)) for f, img, lbl in zip(figs, images, labels): f.imshow(img.view((28, 28)).numpy()) f.set_title(lbl) f.axes.get_xaxis().set_visible(False) f.axes.get_yaxis().set_visible(False) plt.show() print(net) X, y = next(iter(test_iter)) true_labels = get_fashion_mnist_labels(y.numpy()) pred_labels = get_fashion_mnist_labels(net(X).argmax(dim=1).numpy()) titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)] show_fashion_mnist(X[0:9], titles[0:9]) -

pytorch上简洁实现
-
在PyTorch中,我们只需要在全连接层后添加
Dropout层并指定丢弃概率。在训练模型时,Dropout层将以指定的丢弃概率随机丢弃上一层的输出元素;在测试模型时(即model.eval()后),Dropout层并不发挥作用。 -
class FlattenLayer(nn.Module): def __init__(self): super(FlattenLayer, self).__init__() def forward(self, x): # x shape: (batch, *, *, ...) return x.view(x.shape[0], -1) net = nn.Sequential( FlattenLayer(), nn.Linear(num_inputs, num_hiddens1), nn.ReLU(), nn.Dropout(drop_prob1), nn.Linear(num_hiddens1, num_hiddens2), nn.ReLU(), nn.Dropout(drop_prob2), nn.Linear(num_hiddens2, 10) ) for param in net.parameters(): nn.init.normal_(param, mean=0, std=0.01) optimizer = torch.optim.SGD(net.parameters(), lr=0.5) train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer) -
epoch 1, loss 0.0044, train acc 0.556, test acc 0.702 epoch 2, loss 0.0023, train acc 0.787, test acc 0.810 epoch 3, loss 0.0019, train acc 0.824, test acc 0.832 epoch 4, loss 0.0017, train acc 0.839, test acc 0.759 epoch 5, loss 0.0016, train acc 0.849, test acc 0.849 -
可以通过使用丢弃法应对过拟合。丢弃法只在训练模型时使用。