Apache Pulsar 技术系列 - Pulsar 总览
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,数据持久化依赖 Apache BookKeeper 实现,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。本文将从以下几个方面为大家介绍 Apache Pulsar的设计原理和特性。
1、Apache Pulsar 架构
2、架构设计的优势
3、Pulsar 特性
4、总结
Apache Pulsar 架构
存储计算分离
Apache Pulsar 是 Pub/Sub 模型的消息系统,并且从设计上做了存储和计算的分离,如图一所示。
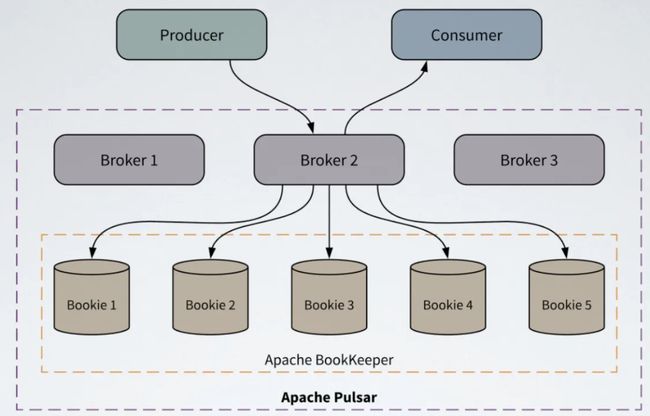
图一 Pulsar 架构
Apache Pulsar 主要包括 Broker, Apache BookKeeper, Producer, Consumer等组件。
-
Broker:无状态服务层,负责接收和传递消息,集群负载均衡等工作,Broker 不会持久化保存元数据,因此可以快速的上、下线。
-
Apache BookKeeper:有状态持久层,由一组名为 Bookie 的存储节点组成,持久化地存储消息。
-
Producer :数据生产者,负责发布数据到 Topic。
-
Consumer:数据消费者,负责从 Topic 订阅数据。
除了上述的组件之外,Apache Pulsar 还依赖 Zookeeper 作为元数据存储。与传统的消息系统相比,Apache Pulsar 在架构设计上采用了计算与存储分离的模式,Pub/Sub 相关的计算逻辑在 Broker 上完成,数据存储在 Apache BookKeeper 的 Bookie 节点上。
分片存储
除了存储、计算解耦分离的设计之外,Apache Pulsar 在存储设计上也不同于传统 MQ 的分区数据本地存储的模式,采用的是分片存储的模式,存储粒度比分区更细化、存储负载更均衡。Apache Pulsar 中的每个 Topic 分区本质上都是存储在 Apache BookKeeper 中的分布式日志。Topic 可以有多个分区,分区数据持久化时,分区是逻辑上的概念,实际存储的单位是分片(Segment)的,如图二,一个分区 Topic1-Part2 的数据由多个 Segment 组成, 每个 Segment 作为 Apache BookKeeper 中的一个 Ledger,均匀分布并存储在 Apache BookKeeper 群集中的多个 Bookie 节点中, 每个 Segment 具有 3 个副本。
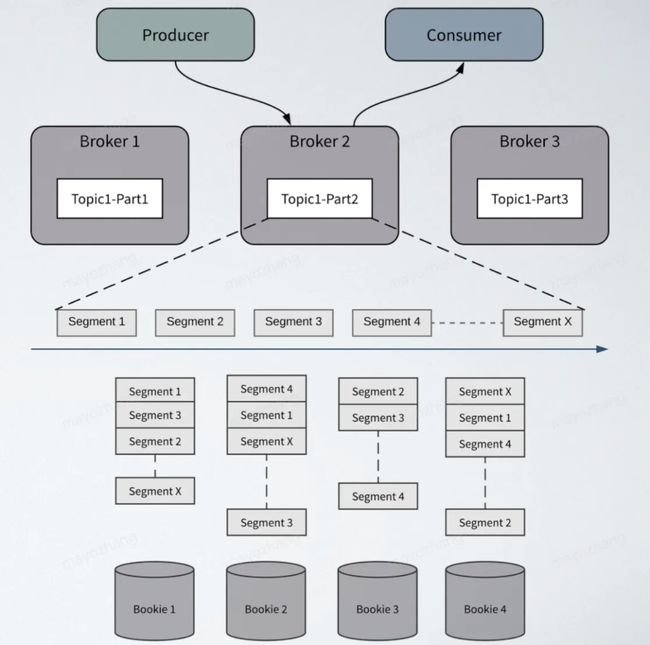
图二 Pulsar 分片存储
下面可以通过图三来看分区和分片存储的区别。
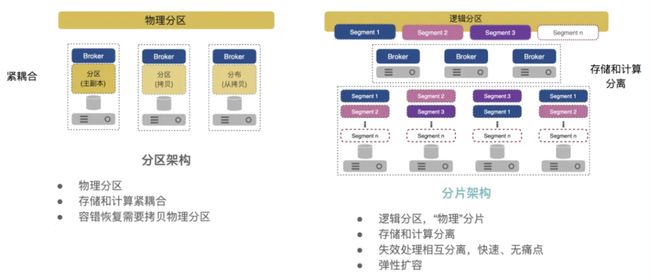
图三 分片存储和分区存储
架构设计的优势
Apache Pulsar 计算与存储分离的架构,以及分片存储的设计为 Apache Pulsar 带来了相比于传统基于分区存储 MQ 的一些优势:
-
Broker 和 Bookie 相互独立,方便实现独立的扩展以及独立的容错。
-
Broker 无状态,便于快速上、下线,更加适合于云原生场景。
-
分区存储不受限于单个节点存储容量。
-
分区数据分布均匀。
-
…
可扩展性
由于消息服务层和持久存储层是分开的,因此 Apache Pulsar 可以独立地扩展存储层和服务层。
Broker 扩展
在 Pulsar 中 Broker 是无状态的,可以通过增加节点的方式实现快速扩容。当需要支持更多的消费者或生产者时,可以简单地添加更多的 Broker 节点来满足业务需求。Pulsar 支持自动的分区负载均衡,在 Broker 节点的资源使用率达到阈值时,会将负载迁移到负载较低的 Broker 节点,这个过程中分区也将在多个 Broker 节点中做平衡迁移,一些分区的所有权会转移到新的Broker节点。
Bookie扩展
存储层的扩容,通过增加 Bookie 节点来实现。通过资源感知和数据放置策略,流量将自动切换到新的 Bookie 节点中,整个过程不会涉及到不必要的数据搬迁,即不需要将旧数据从现有存储节点重新复制到新存储节点。
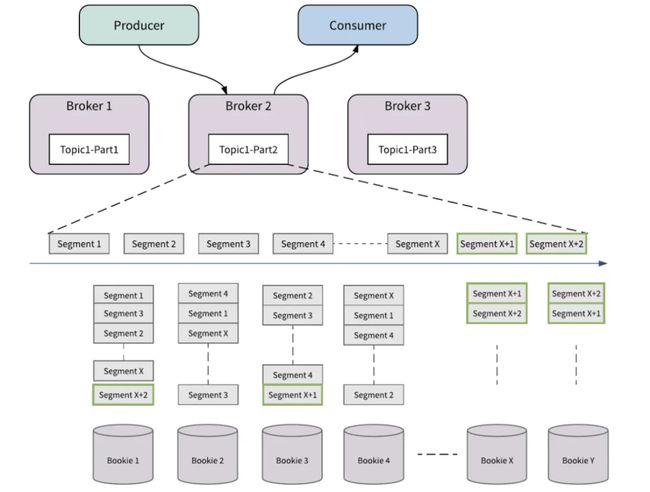
图四 Bookie 扩容
如图四所示,起始状态有四个存储节点,Bookie1, Bookie2, Bookie3, Bookie4,以 Topic1-Part2为例,当这个分区的最新的存储分片是 SegmentX 时,对存储层扩容,添加了新的 Bookie 节点,BookieX,BookieY,那么在存储分片滚动之后,新生成的存储分片, SegmentX+1,SegmentX+2,会优先选择新的 Bookie 节点(BookieX,BookieY)来保存数据。
容错
得益于计算与存储分离以及分片存储的设计,Pulsar 可以实现独立、灵活的容错。
Broker 容错
当 Broker 节点失败时, 以图五为例,当存储分片滚动到 SegmentX 时,Broker2 节点失败,此时生产者和消费者向其他的Broker发起请求,这个过程会触发分区的所有权转移,即将 Broker2 拥有的分区 Topic1-Part2 的所有权转移到其他的 Broker(Broker3)。在 Apache Pulsar 中数据存储和数据服务分离,所以新 Broker 接管分区的所有权时,它不需要复制 Partiton 的数据。新的分区 Owner(Broker3)会产生一个新的分片 SegmentX+1, 如果有新数据到来,会存储在新的分片Segment x+1上,不会影响分区的可用性。
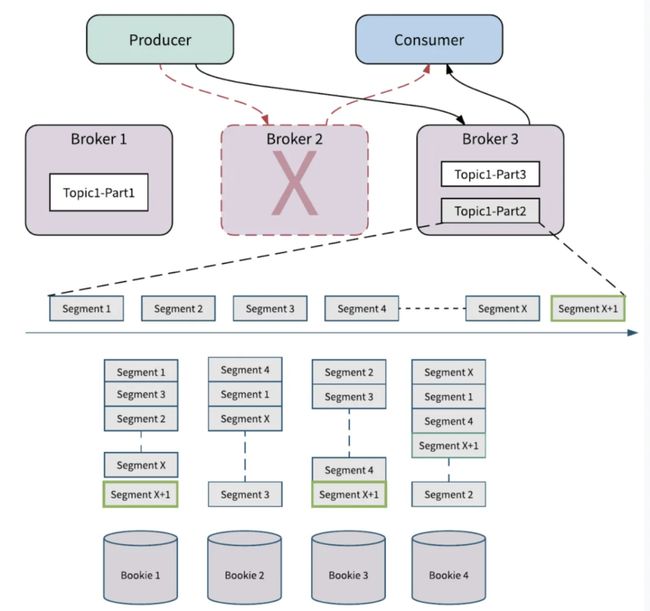
图五 Broker 容错
Bookie容错
当 Bookie 节点失败时,如图六所示, 假设 Bookie 2 上的 Segment 4 损坏。Apache BookKeeper Auditor 会检测到这个错误并进行复制修复。Apache BookKeeper 中的副本修复是 Segment 级别的多对多快速修复,BookKeeper 可以从 Bookie 3 和 Bookie 4 读取 Segment 4 中的消息,并在 Bookie 1 处修复 Segment 4。如果是 Bookie 节点故障,这个 Bookie 节点上所有的 Segment 会按照上述方式复制到其他的Bookie节点。所有的副本修复都在后台进行,对Broker和应用透明,Broker 会产生新的Segment 来处理写入请求,不会影响分区的可用性。
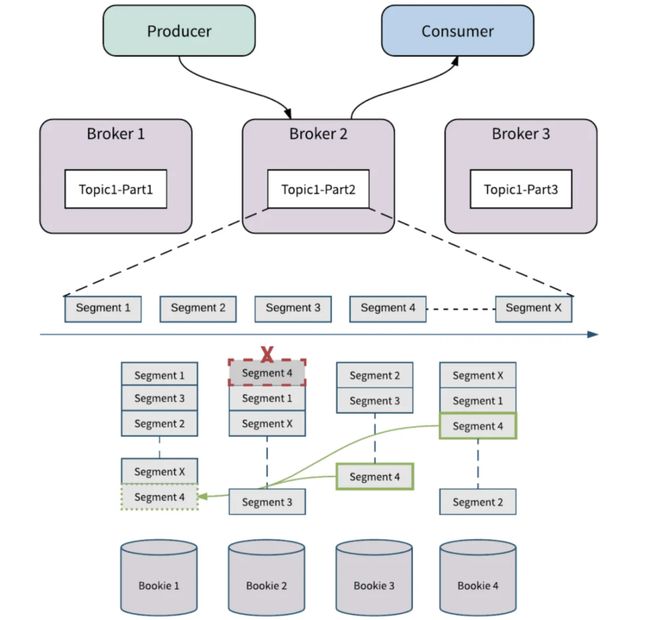
图六 Bookie 容错
无限制的分区存储
分片存储解决了分区容量受单节点存储空间限制的问题,当容量不够时,可以通过扩容 Bookie 节点的方式支撑更多的分区数据,也解决了分区数据倾斜问题,数据可以均匀的分配在 Bookie 节点上。Broker 和 Bookie 灵活的容错以及无缝的扩容能力让 Apache Pulsar 具备非常高的可用性。
Pulsar 特性
基于上述的设计特点,Pulsar 提供了很多特性,以下做简要的介绍。
读写分离
Pulsar另外一个有吸引力的特性是提供了读写分离的能力,读写分离保证了在有大量滞后消费(磁盘IO会增加)时,不会影响服务的正常运行,尤其是不会影响到数据的写入。读写分离的能力由 Apache BookKeeper 提供,简单说一下 Bookie 存储涉及到的概念:
-
Journals:Journal 文件包含了 BookKeeper事务日志,在 Ledger 更新之前,Journal 保证描述更新的事务写入到 Non-volatile 的存储介质上。
-
Entry logs:Entry 日志文件管理写入的 Entry,来自不同 ledger 的 entry 会被聚合然后顺序写入。
-
Index files:每个 Ledger都有一个对应的索引文件,记录数据在 Entry 日志文件中的 Offset 信息。
Entry 的读写入过程如图七所示,数据的写入流程:
-
数据首先会写入 Journal,写入 Journal 的数据会实时落到磁盘。
-
然后,数据写入到 Memtable ,Memtable 是读写缓存。
-
写入 Memtable 之后,对写入请求进行响应。
-
Memtable 写满之后,会 Flush 到 Entry Logger 和 Index cache,Entry Logger 中保存了数据,Index cache 保存了数据的索引信息,然后由后台线程将 Entry Logger 和 Index cache 数据落到磁盘。
数据的读取流程:
-
如果是 Tailing read 请求,直接从 Memtable 中读取 Entry。
-
如果是 Catch-up read(滞后消费)请求,先读取 Index信息,然后索引从 Entry Logger 文件读取 Entry。

图七 Bookie的数据写入和读取
一般在进行 Bookie 的配置时,会将 Journal 和Ledger 存储磁盘进行隔离,减少 Ledger 对于 Journal写入的影响,并且推荐 Journal 使用性能较好的 SSD 磁盘,读写分离主要体现在:
-
写入 Entry 时,Journal 中的数据需要实时写到磁盘,Ledger的数据不需要实时落盘,通过后台线程批量落盘,因此写入的性能主要受到 Journal 磁盘的影响。
-
读取 Entry 时,首先从 Memtable 读取,命中则返回;如果不命中,再从 Ledger 磁盘中读取,所以对于 Catch-up read 的场景,读取数据会影响 Ledger 磁盘的 IO,对 Journal 磁盘没有影响,也就不会影响到数据的写入。
所以,数据写入是主要是受 Journal 磁盘的负载影响,不会受Ledger 磁盘的影响。另外,Segment 存储的多个副本都可以提供读取服务,相比于主从副本的设计,Apache Pulsar 可以提供更好的数据读取能力。通过以上分析,Apache Pulsar 使用 Apache BookKeeper 作为数据存储,可以带来下列的收益:
-
支持将多个 Ledger 的数据写入到同一个 Entry logger 文件,可以避免分区膨胀带来的性能下降问题。
-
支持读写分离,可以在滞后消费场景导致磁盘IO上升时,保证数据写入的不受影响。
-
支持全副本读取,可以充分利用存储副本的数据读取能力。
多种消费模型
Apache Pulsar 提供了多种订阅方式来消费消息,分为三种类型:独占(Exclusive),故障切换(Failover)或共享(Share)。
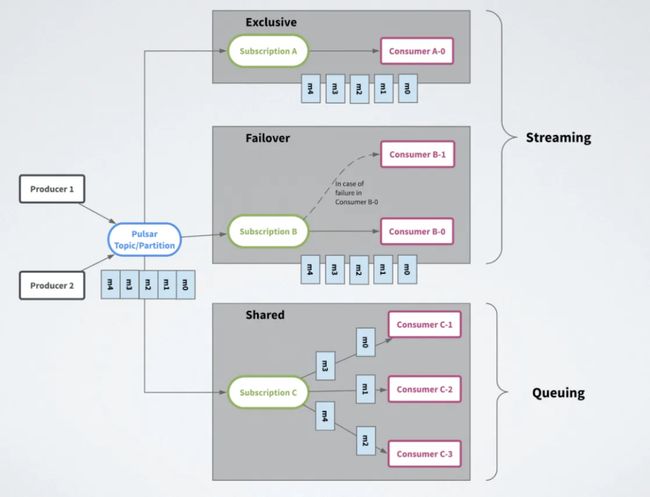
图八 消费模型
-
Exclusive 独占订阅 :在任何时间,一个消费者组(订阅)中有且只有一个消费者来消费 Topic 中的消息。
-
Failover 故障切换 :多个消费者(Consumer)可以附加到同一订阅。但是,一个订阅中的所有消费者,只会有一个消费者被选为该订阅的主消费者。其他消费者将被指定为故障转移消费者。当主消费者断开连接时,分区将被重新分配给其中一个故障转移消费者,而新分配的消费者将成为新的主消费者。发生这种情况时,所有未确认(ack)的消息都将传递给新的主消费者。
-
Share 共享订阅 :使用共享订阅,在同一个订阅背后,用户按照应用的需求挂载任意多的消费者。订阅中的所有消息以循环分发形式发送给订阅背后的多个消费者,并且一个消息仅传递给一个消费者。当消费者断开连接时,所有传递给它但是未被确认(ack)的消息将被重新分配和组织,以便发送给该订阅上剩余的剩余消费者。
多种ACK模型
消息确认(ACK)的目的就是保证当发生故障后,消费者能够从上一次停止的地方恢复消费,保证既不会丢失消息,也不会重复处理已经确认(ACK)的消息。在 Pulsar 中,每个订阅中都使用一个专门的数据结构–游标(Cursor)来跟踪订阅中的每条消息的确认(ACK)状态。每当消费者在分区上确认消息时,游标都会更新。Pulsar 提供两种消息确认方法:
-
单条确认(Individual Ack),单独确认一条消息。被确认后的消息将不会被重新传递。
-
和累积确认(Cumulative Ack),通过累积确认,消费者只需要确认它收到的最后一条消息。
图九说明了单条确认和累积确认的差异(灰色框中的消息被确认并且不会被重新传递)。对于累计确认,M12 之前的消息被标记为 Acked。对于单独进行 ACK,仅确认消息 M7 和 M12, 在消费者失败的情况下,除了 M7 和 M12 之外,其他所有消息将被重新传送。

图九 ACK模型
跨地域复制
Apache Pulsar 的跨地域复制机制(Geo-Replication)提供了一种全连接的异步复制,可以满足多个数据中心数据同步的使用场景。
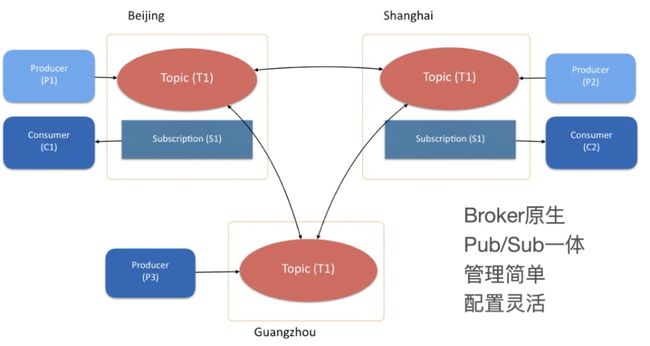
图十 Geo-replication
如图十所示,有三个 Apache Pulsar 集群,分布于北京、上海和广州,用户创建的一个 Topic T1 设置了跨越三个数据中心做互备。在三个数据中心中,分别有三个生产者:P1、P2、P3,它们往主题 T1 中发布消息;有两个消费者:C1、C2,订阅了这个主题,接收主题中的消息。当消息由本数据中心的生产者发布成功后,会立即复制到其他两个数据中心。消息复制完成后,消费者不仅可以收到本数据中心产生的消息,也可以收到从其他数据中心复制过来的消息。
总结
Pulsar 采用了计算、存储分离的设计,并且存储在逻辑上分区,物理上分片,具有一些传统类 kafka 的 MQ 所不具备的优势,也解决了一些业界的痛点,Pulsar 目前社区比较活跃,还处于快速发展的阶段,除了以上的特性之外,Pulsar还可以支持事务、SQL查询、Function等功能,另外 Pulsar 支持 protocol handler,比如 KoP(Kafka on Pulsar), 可以原生支持 Kafka 协议的数据,对于这些特性,我们会在后续的文章中做介绍。