Nacos注册表结构和海量服务注册与并发读写原理 源码分析
文章目录
-
- 1、注册表结构
- 2、数十万服务注册压力与并发写冲突的解决
- 3、并发读写原理
nacos作为功能强大且流行的服务注册框架,具有服务动态发现、服务配置、服务管理及流量控制等功能。今天,我们一起来了解下其服务注册原理以及如何解决高并发读写问题。
1、注册表结构
首先我们回想一下Nacos的服务模型,如下图所示。从上到下分别是:命令空间->服务分组->服务->集群->实例。各个部分对应有什么作用呢。

1、命名空间起到环境隔离的作用,比如隔离生产环境和测试环境;
2、服务分组,当服务太多可对服务进行高一层的分组,默认DEFAULT_GROUP
3、服务,比如订单服务,用户服务
4、集群,服务可以在全国各地部署几百个实例,可把杭州或上海的实例放到各自的杭州集群或上海集群中
5、实例就是真正一个部署的实例
好了,那么如果用Java数据结构来表示上面的注册关系表呢,没错,可以用嵌套的Map集合,各服务模型和Map的对应关系如下
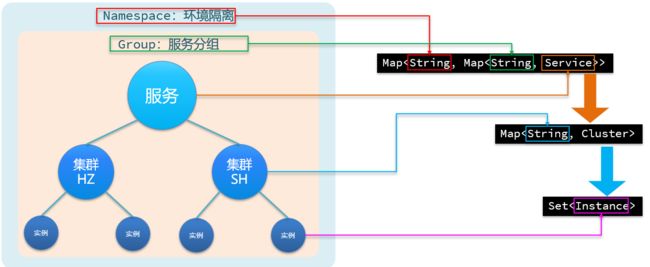
Nacos采用数据的分级存储模型,对应到Java代码用多层Map表示。最外层ServiceMap以命名空间为key,value也是一个内层Map。内层Map以group拼接serviceName作为key,value是一个服务对象。服务对象内部也是一个ClusterMap,以集群名字作为key,value是一个集群对象。集群对象内部是一个实例集合,分为持久和临时实例集合。源码中的命名如下
/**
* ServiceManager服务管理器内部
* Map(namespace, Map(group::serviceName, Service)).
*/
Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();
// service对象持有集群map
// Map // 集群对象 永久实例集合
Set<Instance> persistentInstances = new HashSet<>();
// 临时实例集合
Set<Instance> ephemeralInstances = new HashSet<>();
2、数十万服务注册压力与并发写冲突的解决
核心思想:
Nacos内部接收到服务注册请求后,不是同步写数据,而是把请求包装成任务放入阻塞队列中,然后由单线程的线程池死循环从队列中取任务,异步完成实例更新,从而提高了并发写能力。
并发写冲突通过对相同的service服务加锁解决,同时由单线程的线程池处理实例更新任务也避免了并发写问题。
接下来,我们用核心源码来验证。
首先,根据命令空间id和服务名称得到对应的service对象,对service加锁,解决添加实例的时候并发写问题。接着,调用addIpAddresses方法获取最新的实例列表(包含旧和新的),再调用consistencyService的put方法(重点)真正添加实例。
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
// 创建实例列表唯一Id,即服务唯一Id
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 获取实例对应的服务
Service service = getService(namespaceId, serviceName);
// 添加实例到服务时,对当前服务加锁,解决添加实例并发写问题
synchronized (service) {
// 更新并返回最新的服务列表,采用复制的方式避免了并发读写问题
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
// 写时复制技术:创建新的实例列表,再替换旧的实例列表
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 新的实例列表同步到nacos集群中
consistencyService.put(key, instances);
}
}
addIpAddresses方法调用updateIpAddresses方法,得到最新的实例列表(包含旧实例),当新实例的集群不存在时,还会顺便新建集群并添加到service服务中。如果新实例和旧实例相同,会拷贝旧的实例的id,并覆盖旧实例。
public List<Instance> updateIpAddresses(Service service, String action, boolean ephemeral, Instance... ips)
throws NacosException {
// 获取旧的实例Map
Datum datum = consistencyService
.get(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), ephemeral));
// 当前老服务对应的实例
List<Instance> currentIPs = service.allIPs(ephemeral);
// 写时复制,创建新的Map对象
Map<String, Instance> currentInstances = new HashMap<>(currentIPs.size());
Set<String> currentInstanceIds = Sets.newHashSet();
for (Instance instance : currentIPs) { // 旧的实例列表复制新容器中
currentInstances.put(instance.toIpAddr(), instance);
currentInstanceIds.add(instance.getInstanceId());
}
Map<String, Instance> instanceMap; // 拷贝旧的实例Map
if (datum != null && null != datum.value) {
// 拷贝旧的有效实例列表
instanceMap = setValid(((Instances) datum.value).getInstanceList(), currentInstances);
} else {
instanceMap = new HashMap<>(ips.length);
}
// 把新实例和旧实例都放到服务中,如果旧实例存在以旧实例信息为准。整个过程都是新建再替换,避免了并发读写问题
for (Instance instance : ips) {
if (!service.getClusterMap().containsKey(instance.getClusterName())) {
Cluster cluster = new Cluster(instance.getClusterName(), service); // 当前集群不存在则新建,并添加到旧集群列表中
cluster.init();
service.getClusterMap().put(instance.getClusterName(), cluster);
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
}
if (UtilsAndCommons.UPDATE_INSTANCE_ACTION_REMOVE.equals(action)) {
instanceMap.remove(instance.getDatumKey()); // action=remove则删除实例
} else {
Instance oldInstance = instanceMap.get(instance.getDatumKey());
if (oldInstance != null) { // 旧实例存在,把旧实例的id复制给新实例
instance.setInstanceId(oldInstance.getInstanceId());
} else {
instance.setInstanceId(instance.generateInstanceId(currentInstanceIds));
}
instanceMap.put(instance.getDatumKey(), instance); // 新实例再替换老的实例
}
}
...
return new ArrayList<>(instanceMap.values());
}
consistencyService.put方法跳转到实现类DistroConsistencyServiceImpl(处理临时实例的一致性协议ditro)进行执行。

put方法分两步,本地更新和远程更新。
public void put(String key, Record value) throws NacosException {
// 利用阻塞队列本地更新
onPut(key, value);
// 同样采用异步的方式进行集群同步
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}
我们进去onPut方法,再用notifier对象调用addTask方法添加任务,那么Notifier是什么。
public void onPut(String key, Record value) {
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
Datum<Instances> datum = new Datum<>();
datum.value = (Instances) value;
datum.key = key;
datum.timestamp.incrementAndGet();
dataStore.put(key, datum); // 只是存到Map中,由其他线程异步获取
}
if (!listeners.containsKey(key)) {
return;
}
notifier.addTask(key, DataOperation.CHANGE);
}
Notifier原来是一个runnable对象,内部有一个阻塞队列tasks,调用addTask就是往阻塞队列添加任务。再看一下它的run方法,死循环从队列中获取任务并调用handle方法,异步更新实例列表。handle方法采用写时复制,把实例更新到clusterMap中,留到后面再说。那么Notifier线程什么时候开始提交执行的呢。
public class Notifier implements Runnable {
private ConcurrentHashMap<String, String> services = new ConcurrentHashMap<>(10 * 1024);
private BlockingQueue<Pair<String, DataOperation>> tasks = new ArrayBlockingQueue<>(1024 * 1024);
public void addTask(String datumKey, DataOperation action) {
if (services.containsKey(datumKey) && action == DataOperation.CHANGE) {
return;
}
if (action == DataOperation.CHANGE) {
services.put(datumKey, StringUtils.EMPTY);
}
// 往阻塞队列中添加任务
tasks.offer(Pair.with(datumKey, action));
}
@Override
public void run() {
Loggers.DISTRO.info("distro notifier started");
for (; ; ) {
try {
Pair<String, DataOperation> pair = tasks.take();
handle(pair);
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
...
}
在DistroConsistencyServiceImpl看到如下init方法,被PostConstruct修饰,说明在依赖注入完成后就会调用,本质是提交给一个单线程的线程池执行,即Executors.newScheduledThreadPool(1),单线程也避免了并发写问题。
@PostConstruct
public void init() {
GlobalExecutor.submitDistroNotifyTask(notifier);
}
下面distroProtocol.sync是集群数据同步的逻辑了,找到集群所有的结点,把任务放到一个ConcurrentHashMap中,然后线程池取任务再进行同步。基于Distro模式的同步是异步进行的,并且失败时会将任务重新入队并重试,因此不保证同步结果的强一致性,属于AP模式的一致性策略。
public void sync(DistroKey distroKey, DataOperation action, long delay) {
for (Member each : memberManager.allMembersWithoutSelf()) {
DistroKey distroKeyWithTarget = new DistroKey(distroKey.getResourceKey(), distroKey.getResourceType(),
each.getAddress());
DistroDelayTask distroDelayTask = new DistroDelayTask(distroKeyWithTarget, action, delay);
distroTaskEngineHolder.getDelayTaskExecuteEngine().addTask(distroKeyWithTarget, distroDelayTask);
}
}
protected void processTasks() {
Collection<Object> keys = getAllTaskKeys();
for (Object taskKey : keys) {
AbstractDelayTask task = removeTask(taskKey);
if (null == task) {
continue;
}
NacosTaskProcessor processor = getProcessor(taskKey);
if (null == processor) {
getEngineLog().error("processor not found for task, so discarded. " + task);
continue;
}
try {
// ReAdd task if process failed 失败重试
if (!processor.process(task)) {
retryFailedTask(taskKey, task);
}
} catch (Throwable e) {
getEngineLog().error("Nacos task execute error : " + e.toString(), e);
retryFailedTask(taskKey, task);
}
}
}
3、并发读写原理
nacos在更新实例列表的时候,采用CopyOnWrite技术,先拷贝旧的实例列表,然后更新拷贝的实例列表,最后再用拷贝的列表替换旧的实例列表,就避免了并发读写问题。
我们用核心源码来验证一下。
发现更新实例列表的时候,直接把引用指向一个新new的对象,而不是在原来的实例列表进行增删改,这就解决了脏读问题。更新过程中的旧实例列表不受影响,用户依然依然可以读取。
public void updateIps(List<Instance> ips, boolean ephemeral) {
...
// 上面都是日志功能,没有实际的功能
// 将实例列表应用指向新的实例列表
toUpdateInstances = new HashSet<>(ips);
if (ephemeral) {
ephemeralInstances = toUpdateInstances;
} else {
persistentInstances = toUpdateInstances;
}
}
参考:某马