Flink进阶系列--FLIP-27新的Source架构
Source 旧架构
在 Flink 1.12之前,开发一个新的 source connector 是通过实现 SourceFunction 接口来完成的。
@Public
public interface SourceFunction extends Function, Serializable {
// 当 source 开始发送数据时,run 方法被调用,其参数 SourceContext 用于发送数据。run 方法是一个无限循环,通过一个标识 isRunning 来跳出循环结束 source。
void run(SourceContext ctx) throws Exception;
// 放弃发送数据,一般实现逻辑是修改 isRunning 标识
void cancel();
// Source 上下文
interface SourceContext {
// 从数据源中发送1条不含时间戳的数据
void collect(T element);
// 从数据源中发送1条含时间戳的数据
@PublicEvolving
void collectWithTimestamp(T element, long timestamp);
// 发送水印,以声明不再出现含水印之前时间戳的数据
@PublicEvolving
void emitWatermark(Watermark mark);
// 将源标记为暂时空闲
@PublicEvolving
void markAsTemporarilyIdle();
// 返回检查点锁
// 通过 checkpoint 锁来保证状态更新和数据发送的原子性
Object getCheckpointLock();
// 关闭 Source 上下文
void close();
}
}
Source 实现如果需要和 Flink 的 RuntimeContext 交互,则需要实现 RichSourceFunction 抽象类:
// 通过继承 AbstractRichFunction 抽象类对 SourceFunction 进行了增强
@Public
public abstract class RichSourceFunction extends AbstractRichFunction
implements SourceFunction {
private static final long serialVersionUID = 1L;
}
值得一提的是,Flink 在 SourceFunction 之上抽象出了 InputFormatSourceFunction,开发者只需要实现 InputFormat,批模式 source connector(如 HBase)通常基于 InputFormat 实现,当然 InputFormat 也可以用于流模式,在一定程度上体现了批流融合的思想,但整体上来看至少在接口层面上流批并没有完全一致。
SourceFunction-->ParallelSourceFunction-->RichParallelSourceFunction-->InputFormatSourceFunction
在基于 SourceFunction 的开发模式下,以 Kafka Source 为例,见下图,FlinkKafkaConsumer 为 SourceFunction 的实现类,该类中集中了 kafka partition 发现逻辑(KafkaPartitionDiscoverer)、数据读取逻辑(KafkaFetcher)、基于阻塞队列实现的生产者消费者模型(KafkaConsumerThread -> Handover -> SourceContext)等等。
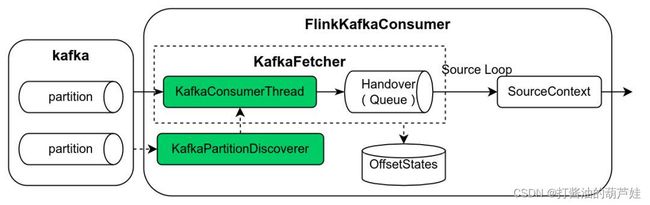
可以发现,这种开发模式存在如下不足:
- 对于批模式和流模式需要不同的处理逻辑,不符合批流融合的业界趋势。
- 数据分片(例如 kafka partition、file source 的文件 split)和实际数据读取逻辑混合在 SourceFunction 中,导致复杂的实现。
- 数据分片在接口中并不明确,这使得很难以独立于 source 的方式实现某些功能,例如事件时间对齐(event-time alignment)、分区 watermarks(per-partition watermarks)、动态数据分片分配、工作窃取(work stealing)。
- 没有更好的方式来优化 Checkpoint 锁,在锁争用下,一些线程(例如 checkpoint 线程)可能无法获得锁。
- 没有通用的构建模式,每个源都需要实现自行实现复杂的线程模型,这使得开发和测试一个新的 source 变得困难,也提高了开发者对现有 source 的作出贡献的门槛。
有鉴于此,Flink 社区提出了 FLIP-27 的改进计划,并在 Flink 1.12 实现了基础框架,在 Flink 1.13 中 kafka、hive 和 file source 已移植到新架构,开源社区的 Flink CDC connector 2.0 也基于新架构实现。
Source 新架构
特性
Source 新架构主要有如下特性:
数据分片和数据读取分离
新 Source 有2个关键组件:
- SplitEnumerator: 负责将数据拆解成多个分片 (如files, partitions等)。
- Reader: 负责从各个分片中读取数据。
SplitEnumerator 类似于旧的批处理 Source 接口的创建分片和分配分片的功能。 它只运行一次,而不是并行运行(社区在规划未来如有需要,将分片的切分也并行化)。
它可以在 JobManager 上运行,也可以在 TaskManager 上的单个任务中运行,当前社区的实现为每个 SplitEnumerator 都将封装在一个 SourceCoordinator 中。 如果有多个源,就会有多个SourceCoordinator。 SourceCoordinators 将在 JobMaster 中运行,但不作为 ExecutionGraph 的一部分。(目前社区对该问题还没有定论,倾向于将 SplitEnumerator 放在 TaskManager 上运行)。
基于 SplitEnumerator 和 Reader 将 split 分配行为和数据读取行为隔离,有助于用户将不同的分区行为和数据读取行为灵活组合起来,避免将两部分的代码耦合在一起,难以维护。

流批统一
基于新架构开发的 Source 既可以工作于批模式也可以工作于流模式,批仅仅是有界的流。大多数情况下,只有 SplitEnumerator 需要感知数据源是否有界。例如对于 FileSource,批模式下 SplitEnumerator 只需要一次性的列出目录下的所有文件,流模式下则需要周期性的列出所有文件,并为新增的文件生成数据分片。对于 KafkaSource,批模式下 SplitEnumerator 列出处有的 partition,并把每个 partition 的当前最新的数据偏移作为数据分片的结束点,流模式下 SplitEnumerator 则把无穷大作为 partition 数据分片的结束点,即会持续的读取每个 partition 的新增数据,流模式下还可以周期性的监测 partition 的变化并为新增的 partitition 生成数据分片。
双向通信
SplitEnumerator 和 SourceReader 之间可以双向通信,SourceReader 可以主动向 SplitEnumerator 请求数据分片实现 pull 模式的数据分片分配(例如 FileSource),SplitEnumerator 也可以把数据分片直接分配给 SourceReader 实现 push 模式的分配(例如 KafkaSource)。此外,根据需要还可以定制化一些消息实现 SplitEnumerator 和 SourceReader 之间的交互需求。基于双向通信的能力,比较容易实现事件时间对齐(event-time alignment)的功能,实现数据分片之间事件时间的均衡推进。
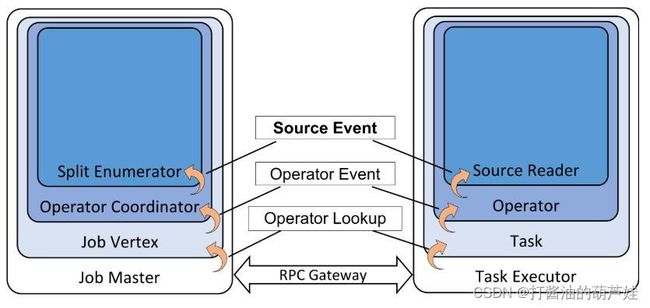
通用线程模型
考虑到外部数据源系统的客户端 API 调用方式的差异(阻塞、非阻塞、异步),SourceReader 在设计上支持单分片串行读取、多分片多路复用、多分片多线程三种模式。
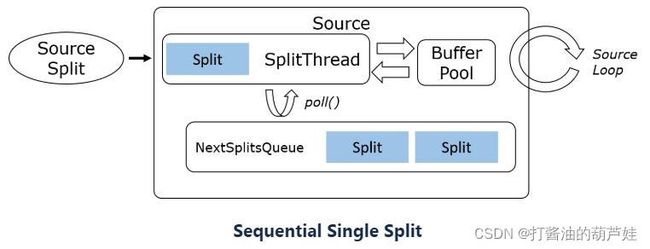
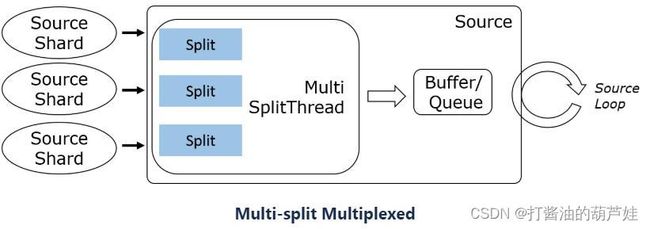
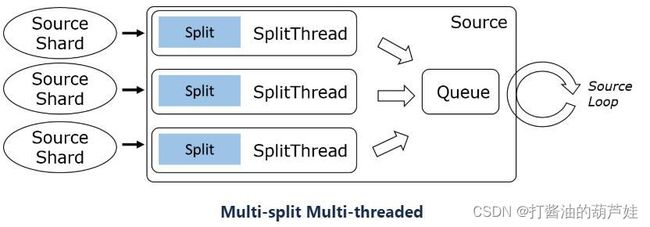
3种模型的典型示例:
- Sequential Single Split (File, database query, most bounded splits)
- Multi-split multiplexed (Kafka, Pulsar, Pravega, …)
- Multi-split multi-threaded (Kinesis, …)
Flink 1.13 内核的 SingleThreadMultiplexSourceReaderBase/SingleThreadFetcherManager 抽象出的框架支持前两种线程模型,开发者基于此开发 source connector 变得容易。例如 FileSource 采用了单分片串行读取模式,在一个数据分片读取后,再向 SplitEnumerator 请求新的数据分片。KafkaSource 采用了多分片多路复用模式,SplitEnumerator 把启动时读取的 partition 列表和定期监测时发现的新的 partition 列表批量分配给 SourceReader,SourceReader 使用 KafkaConsumer API 读取所有分配到的 partition 的数据。
容错
SplitEnumerator 和 SourceReader 通过 Flink 的分布式快照机制持久化状态,发生异常时从状态恢复。通常 SplitEnumerator 状态保存了未分配的数据分片,SourceReader 状态保存了分配的数据分片以及分片读取状态(例如 kafka offset,文件 offset)。例如流模式下 FileSource 的 SplitEnumerator 状态保存了未分配的分片以及处理过的文件列表,并定期监测文件列表的变化,为新增文件生成数据分片;SourceReader 状态保存了当前读取的分片信息和文件读取 offset。
基本实现

流程
当 SplitEnumerator 将新的 split 添加到 SourceReader 时,在将 split 分配给 SplitReader 之前,该新 split 的初始状态将放入由 SourceReaderBase 维护的状态映射中。
Record 通过 RecordsBySplitIds 集合的方式从 SplitReaders 传递到 RecordEmitter。这允许 SplitReader 以批处理方式将 Record 排入队列,从而提高性能。
大多数 SourceReader 需要实现类似于下面的接口:
public interface SplitReader {
RecordsWithSplitIds fetch() throws InterruptedException;
void handleSplitsChanges(Queue> splitsChanges);
void wakeUp();
}
上述接口中除了 wakeUp() 方法外,Flink 线程模型均保证由同一线程执行,从而进行接口实现的时候,无需考虑并发安全性问题,降低了开发的难度,
SplitReader 获取到的数据集合 RecordsWithSplitIds 将依次转递给 RecordEmitter,RecordEmitter 主要完成下述任务:
- 将原始记录类型 转换为最终记录类型 ;
- 为其处理的数据提供 event time 时间戳。
故障转移
SplitEnumerator 的状态包括以下内容:
- 未分配的 splits;
- 已分配但还未成功 checkpoint 的 splits。
SourceReader 的状态包括:
- 已分配的 splits;
- 各个 split 的状态(例如 Kafka 偏移量、HDFS 文件偏移量等)。
在该 FLIP 中,当 SplitEnumerator 失败时,将执行完整的故障转移。虽然可以进行更细粒度的故障转移以仅恢复 SplitEnumerator 的状态,但社区希望在单独的 FLIP 中解决此问题。
当 SourceReader 失败时,失败的 SourceReader 将恢复到其上一个成功的 checkpoint。 SplitEnumerator 将通过将已分配但未 checkpoint 的 split 重新添加回 SplitEnumerator 来部分重置其状态。 在这种情况下,只有失败的子任务及其连接的节点必须重置状态。
参考文献
https://blog.csdn.net/cloudbigdata/article/details/122406155