elasticsearch 学习笔记3
elasticsearch的基础数据类型详细了解看: Elasticsearch数据类型及其属性 - 简书
学习过程中对于一些字段不太了解,所以查了一下
"cityCode":{
"type": "text", //text 类型:当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型
"fields":{ //fields:可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"keyword":{
"type": "keyword", //keyword类型的字段只能通过精确值搜索到。
"ignore_above": 256 //ignore_above超过256个字符的文本,将会被忽略,不被索引
}
}
"analyzer": "pinyin_analyzer" //analyzer:指定分词器,默认分词器为standard analyzer
"search_analyzer": "ik_smart" //search_analyzer:设置搜索时的分词器,默认跟analyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
}比较重要的:analyzer、search_analyzer 是实现搜索的关键
analyzer 和 search_analyzer 的区别:
1,分词器 analyzer 的作用有二:
一是 插入文档时,将 text 类型字段做分词,然后插入 倒排索引。
二是 在查询时,先对 text 类型输入做分词, 再去倒排索引搜索。
2,如果想要“索引”和“查询”, 使用不同的分词器,那么 只需要在字段上 使用 search_analyzer。这样,索引只看 analyzer,查询就看 search_analyzer。
analyzer是分词器,可以看:Elasticsearch之analysis_花&败-CSDN博客
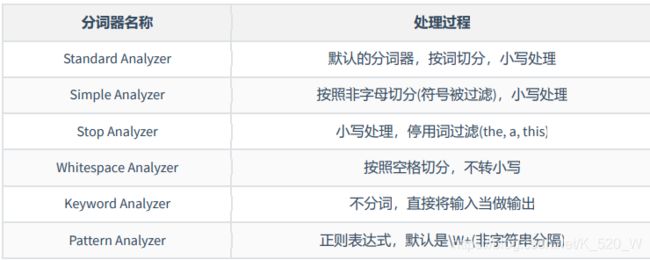
使用之前先了解一下分词的基本原理,各个分词的规则。上图是es的内置分词器(我现在没有用到英语查询,所以主要看汉语)
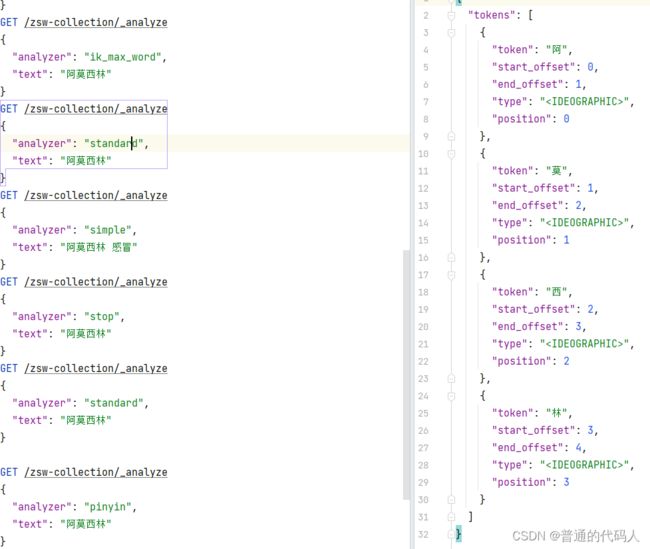 standard分词器会将每个字进行分割,即包含“阿”、“莫”、“西”、“林” 的结果都会返回。会查出来一堆感冒灵、盘尼西林之类的。 其他的就不一一展示了,基本一样
standard分词器会将每个字进行分割,即包含“阿”、“莫”、“西”、“林” 的结果都会返回。会查出来一堆感冒灵、盘尼西林之类的。 其他的就不一一展示了,基本一样
我用到了拼音分词器和ik分词器,这两个需要下载
ik分词器算是一种进阶版,会进行智能一点的分词,同样是 阿莫西林,用ik分词会获取这样的数据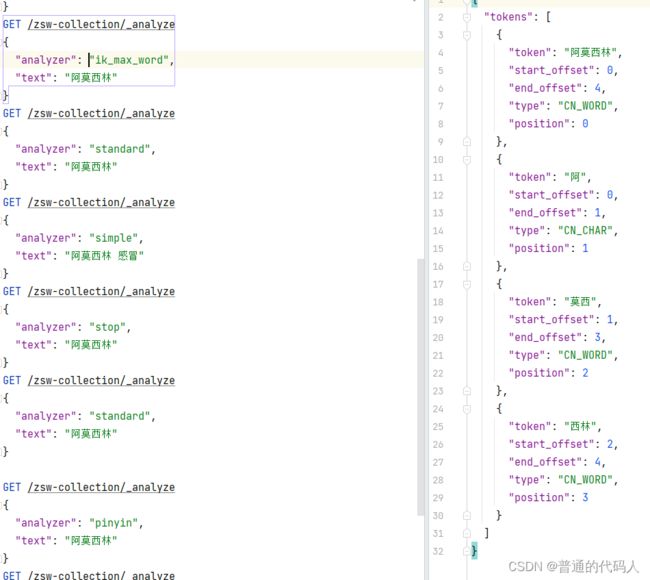
它会将“阿莫西林”分成“阿”、“莫西”、“西林”、“阿莫西林”,算是关键字的关键字。再搜索阿莫西林时就不会出现感冒灵、盘尼西林这种东西了。
拼音分词器可以实现用简拼搜索,或者不用汉字,用拼音搜索,例如搜索 “阿莫西林” ,可以用 “amxl” 、“a mo xi lin”或者 “amoxilin”
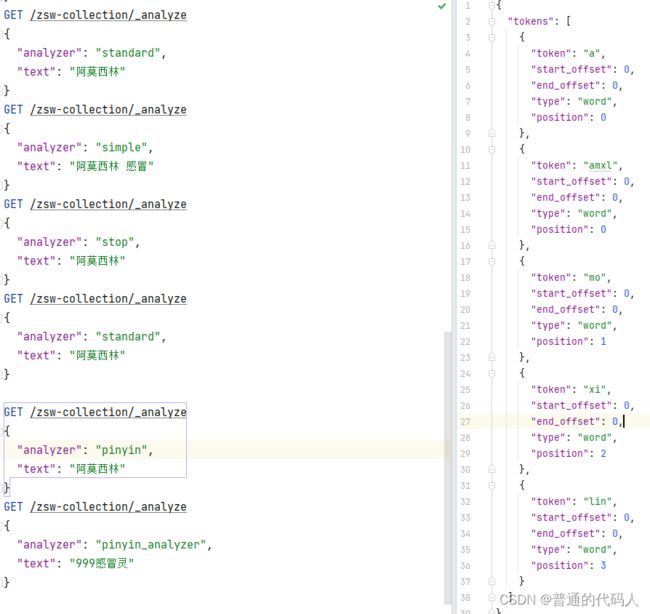
拼音分词器的源代码:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin. https://github.com/medcl/elasticsearch-analysis-pinyin
https://github.com/medcl/elasticsearch-analysis-pinyin
里面有设置的参数和示例
**可选参数**
keep_first_letter当此选项启用时,例如:刘德华>ldh,默认值:真keep_separate_first_letter当此选项启用时,将保持首字母分开,例如:刘德华>l,d,h,默认值:false,注意:由于术语过于频繁,查询结果可能过于模糊limit_first_letter_length设置first_letter结果的最大长度,默认值:16keep_full_pinyin当此选项启用时,例如:刘德华> [liu,de,hua],默认值:真keep_joined_full_pinyin当此选项启用时,例如:刘德华> [liudehua],默认值:falsekeep_none_chinese在结果中保留非中文字母或数字,默认值:truekeep_none_chinese_together将非中文字母放在一起,默认:true,例如:DJ音乐家->DJ,yin,yue,jia,当设置为时false,例如:DJ音乐家->D,J,yin,yue,jia,注意:keep_none_chinese应首先启用keep_none_chinese_in_first_letter将非中文字母放在第一个字母中,例如:刘德华AT2016->ldhat2016,默认值:真keep_none_chinese_in_joined_full_pinyin保持非中文字母的完整拼音,例如:刘德华2016->liudehua2016,默认值:falsenone_chinese_pinyin_tokenize如果是拼音,将非中文字母拆分成单独的拼音项,默认:true,例如:liudehuaalibaba13zhuanghan->liu,de,hua,a,li,ba,ba,13,zhuang,han,注意:keep_none_chinese和keep_none_chinese_together应首先启用keep_original启用此选项时,也将保留原始输入,默认值:falselowercase小写非中文字母,默认:truetrim_whitespace默认值:真remove_duplicated_term启用此选项后,重复的术语将被删除以保存索引,例如:de的>de,默认值:false,注意:职位相关查询可能会受到影响ignore_pinyin_offset在6.0之后,偏移被严格约束,不允许重叠标记,使用该参数,通过忽略偏移将允许重叠标记,请注意,所有与位置相关的查询或突出显示将变得不正确,您应该使用多个字段并为不同的查询目的指定不同的设置。如果需要偏移,请将其设置为false。默认值:true。
然后就是将他们两个组合起来使用,我参考了Elasticsearch之analysis_花&败-CSDN博客 和Elasticsearch拼音分词插件安装和使用_Sunny Feng的博客-CSDN博客 这两位的方法,最后就像这样:
"settings": {
"index": {
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "ik_max_word",
"filter": "my_pinyin",
},
},
"filter": {
"my_pinyin": {
"type": "pinyin",
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_joined_full_pinyin": false,
"keep_original": true,
"limit_first_letter_length": 20,
"lowercase": true,
"remove_duplicated_term": true,
},
},
},
},
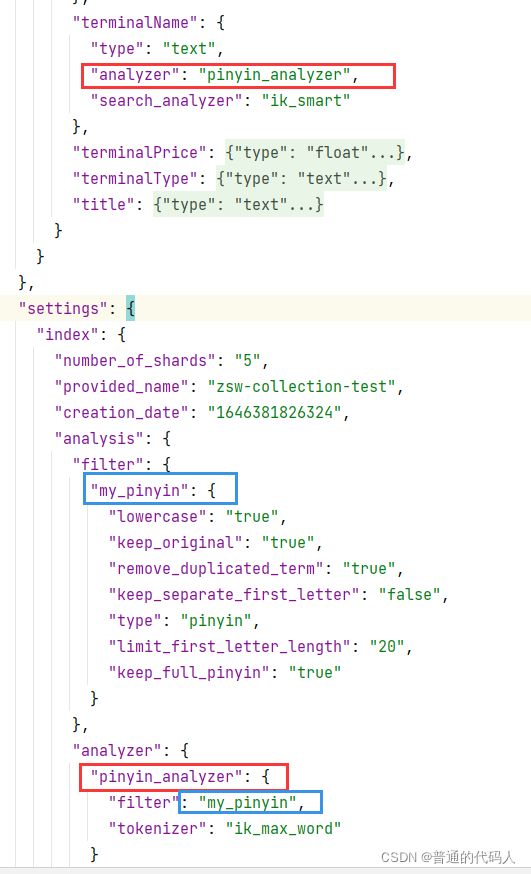
}在建表的时候把这一串加进去,同时在要执行搜索的字段下面加:
"productName":{
"type": "text",
"analyzer": "pinyin_analyzer",
},
然后查看:
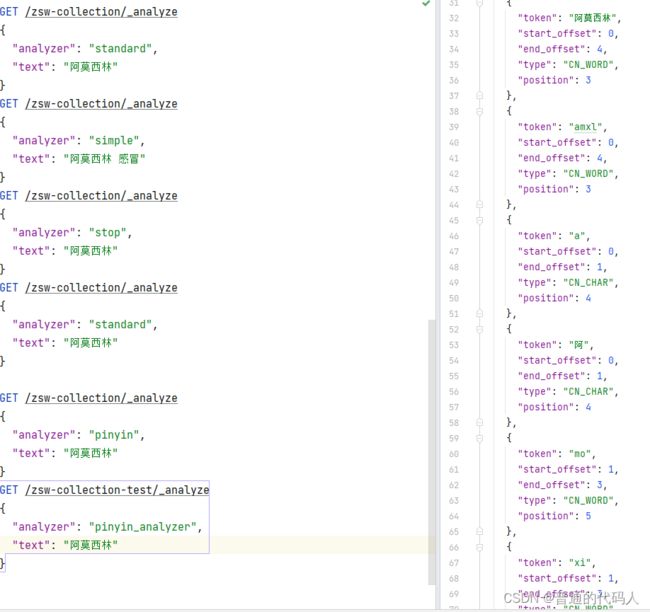 然后就可以用拼音和汉字同时查了
然后就可以用拼音和汉字同时查了