向量检索算法综述
目录
1. 基于树的搜索
2. 基于哈希的空间划分
3. 基于图的搜索
3.1 朴素想法
3.2 NSW
3.3 HNSW
3.4 小结
4. 基于量化的编码
4.1 SQ和PQ
4.2 IVFPQ
4.3 小结
5 总结
Reference
大数据时代的到来,海量数据的迸发,使得向量检索应用日益广泛,诸如图文推荐,视频推荐,音乐推荐,文章去重,以图搜图等等。而这些应用的普遍特征是数据量大,维度高。因此精确的线性的暴力搜索无法满足速度,甚至存储要求。而近邻搜索(Approximately Nearest Neighbor Search)由此登上历史舞台,展现其光辉的一面。
近邻搜索,用一句话概括其原则:尽可能减小查询向量的搜索范围,从而提高查询速度。目前业界的近邻搜索算法主要分为四类,本文对每个类别选取典型的算法予以介绍。
- 基于树的搜索(Annoy, KD-Tree)
- 基于哈希的空间划分(LSH)
- 基于图的搜索(NSW,HNSW)
- 基于量化的编码(SQ,PQ)
1. 基于树的搜索
基于树的方法采用树的结构来表示对空间的划分,KD-Tree和Annoy是比较有代表性的两种算法。KD-Tree每一次分割选取方差最大的维度,在该维度上进行分割。
本文以Annoy为例对基于树的搜索进行详细阐述。
Annoy 是Spotify用于音乐推荐的向量检索算法库,在github上开源。
Annoy不断地用超平面分割向量空间,直到每个子空间的向量数量低于指定数量。而这个不断地分割过程就像二叉树的父节点到左右子节点的过程。而这个超平面,使用KMeans(k=2)对需要分类的向量进行聚类,得到两个质心,质心连线的法平面即为该超平面。



如此...直到:

整个过程类似如下的二叉树:

而对于向量的查询,则是从根节点开始遍历,当遍历到某个节点,其子节点小于指定查找数目时停止搜索。
这样的查找有几个问题。第一,走到某一个节点,其包含的向量数少于我们要查询的近邻数。第二,可能有的相邻较近的节点被分到了不同的子节点,从而影响搜索精度。
对于第一点,可以通过配置,当我们走到某一节点时,把相邻的子节点放到队列里面,最后也需要遍历这些子节点包含的向量。
对于第二点,可以构造多棵树,从而避免一棵树造成的随机性。
总结一下,Annoy的优缺点
优点:
- 支持距离种类:欧式距离,曼哈顿距离,余弦距离,海明距离
- 建立索引与向量检索是独立的,索引可以在多进程之间共享
缺点:
- 适合维度低, 数据量小的向量检索
- 为了提高准确率,需要构造多棵树
- 目前只支持非负整数的id,如果有别的类型id,需自行维护一份映射
2. 基于哈希的空间划分
LSH:利用哈希的碰撞,选取一组合适的哈希函数,将距离相近的向量映射到相同的cell里面。距离越近,越有可能在同一个桶里面。那么检索向量的时候,先对查询向量做哈希运算得到相应的桶,在对应的桶里面查找相近的向量,则大大缩小的查找范围。
3. 基于图的搜索
3.1 朴素想法
图,由于其本身保存近邻关系,在向量检索中拥有较高的效率。首先我们来看一张简单的图

如果要找到粉红色的点最近的点,我们从任一个点开始,比如A,从A的相邻的点中(B,C,D)找到离目标最近的点D,接下来从D相邻的点(F,J,E)中找到离目标最近的点E,而在E的相邻的点中(B,D,G,J)中,E是离目标最近,那搜索停止,E就是我们要找的点。
朴素想法很简单,但是有如下几个问题:
- 有些点无法查询, 比如K
- 如果两个相近的点无连线,则影响效率,比如E和L
- 需要多少个友点,多的话则耗存储,少的话可能影响效率
3.2 NSW
针对朴素想法的几个问题,我们采取如下措施:
有些点无法查询 ===> 要求构图时所有的点必须有相邻的点
如果两个相近的点无连线,则影响效率 ===>构图时相邻的点必须有连线
需要多少个友点 ===> 作为参数由用户指定
解决了以上问题,我们查询的效率还是没有得到提升。试想一下,如果我们从离目标很远的点开始查找,而每个点只跟相近的点有连线,那搜索的路径要经过很多点。如果我们能够增加一个"高速公路"机制,那么可以使得查找跳过一些相近的点从而提升搜索速度。
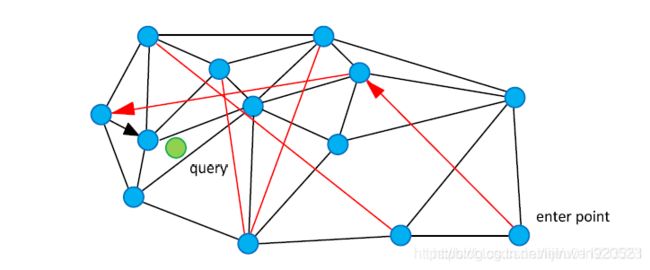
图中红色的就是高速公路,那么从entry point查找时,可以跳过一些较近的点。
NSW在上述前提下应运而生:构图的过程中,插图一个全新点时,查找到与这个全新点最近的m个点(m由用户设置),连接全新点到m个点的连线。那么越先被插入的点,越有可能有高速公路,因为插入某一个点时,链接与它相近的点。但是在后面的构图过程中可能会有更近的点插入,那么这些原先的连线就成了高速公路了。
3.3 HNSW
NSW对图的查找采用高速公路的机制提升了效率。但是这样的高速公路有一定的随机性,而且,越往后插入的点,拥有高速公路的可能性越低。那么这里可以模仿跳表的机制。跳表在Redis里面作为有序列表的底层数据结构,优化了链表的查询速度。通过给每一个节点随机构建层数,而同一层也是一个链表,从而构建了高速公路。查找时从高层查找开始。

HNSW的思路类似:

构建类似上图一样的结构,插入新节点的时候,先插入最底层,然后随机取一个层数作为该新节点的层数,从底层依次向上每一层都增加该节点,而在每一层构图都采用NSW的思路。这样,高层的连线相对于低层就是高速公路。查找时,从高层开始查找。
3.4 小结
优点:
- 召回率高,检索快(在ANN Benchmark中HNSW的查询最快)
缺点:
- 训练时间长(构图)
- 存储成本较高(图的关系)
4. 基于量化的编码
4.1 SQ和PQ
量化分为SQ和PQ,SQ是将每一个维度量化成指定位数的一个数,比如将32位的int量化成8位的int,通过损失一定的精度,缩减存储成本。而PQ是将整个向量划分为M段,每一段量化成一个指定位数的数,比如下图将128维(每个维度32位)的向量分成4段,每段量化成一个8位的数,则相当于每段含有256个聚类中心,那么一个128维的向量可以用4维(每个维度8位)的向量表示。
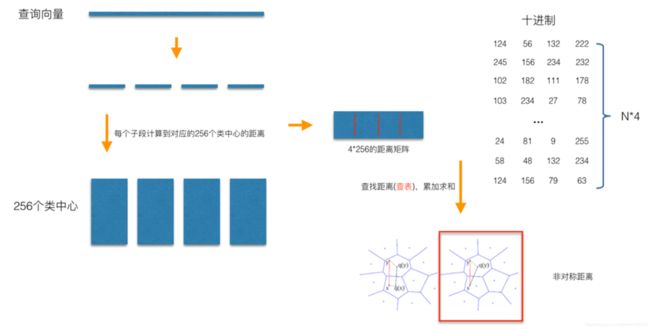
当一个查询向量到来时,先对该向量采取相同的措施,先分段,再量化。然后计算每一段到256个聚类中心的距离,存为码本(256*4)。当我们计算该向量和某个样本向量的距离时,只需拿到样本向量各段的聚类中心,查询改码本即可得到距离该段的距离,无需计算。最后将各段距离相加即可得到总的距离。这样就将原先的计算复杂度简化为计算码本的复杂度。
4.2 IVFPQ

IVFPQ,通过先粗量化,获取里查询向量较近的几个聚类,再在这几个聚类中做PQ计算。具体过程如下:
先将样本空间进行粗量化,一般量化成1024个聚类中心,然后通过计算每个向量到各个聚类中心的残差可以得到离每个样本最近的聚类中心,则可以得到每个每个聚类中心下的样本。然后对每个样本空间,计算其与聚类中心的残差,再进行PQ操作得到图中右下的编码。查询向量到来时,先进行量化获取查询向量所属聚类,并获取需要进一步操作的聚类,后续查询操作与PQ类似,只是计算的公式发生改变。这里为什么用残差做PQ,目的是使得分段聚类使用统一聚类,减少聚类次数。具体证明可以参阅这里。
4.3 小结
SQ,PQ通过量化压缩向量存储,并以到聚类中心的距离优化真实距离,减少计算次数。同时结合IVF,限定PQ的范围,进一步缩小查询范围,从而提升查询速度。
5 总结
以上四种算法中,基于图的算法性能较优,在ANN Benchmark中具有最好的性能。但是由于构图比较耗时,而且需要存储节点之间的连线,所以存储方面的要求较高。而SQ,PQ对向量进行了压缩从而节省了存储空间。
Annoy的作者开发了一个ANN Benchmark,上面提供了很多向量检索算法的Benchmark,以及一些数据集,用户可以参考或者拿来运行自己的Benchmark。
以下选取两个欧氏距离的数据集Benchmark结果图:
fashion-mnist-784-euclidean(k=10):
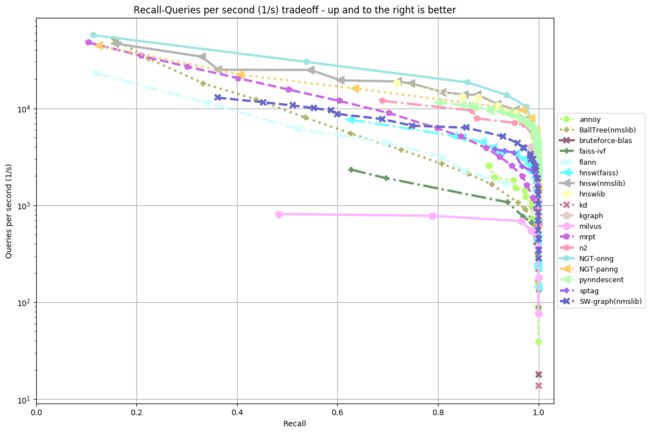
sift-128-euclidean(k=10):
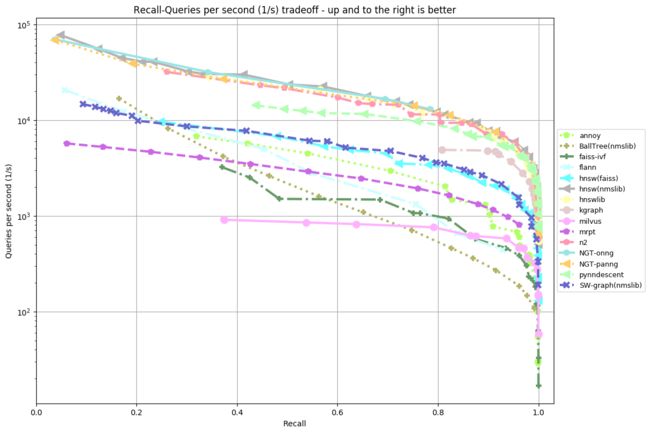
从以上两图可以看出:
- hnsw,NGT等基于图的算法性能较优
- 相同的算法,不同的实现性能有所差异,比如hnsw(faiss) 和hnsw(nmslib)
Reference
- Nearest neighbors and vector models – part 2 – algorithms and data structures
-
一文看懂HNSW算法理论的来龙去脉