codebert论文实验复现_暂停(缺GPU)
省时:os用linux,python用3.6,有GPU,应该就能运行…
下一步思路:
- 方案1(GPU):在linux里,安装gpu(安装对应版本的kernel-devel;下载NVIDIA-Linux-x86_64-440.33.01.run;或许还需要cuda,使torch.cuda.is_available()为true)
- 方案2(不用GPU):修改run.py,删除与GPU相关的代码
如果没有可用的显卡资源,则检查代码,把调用显卡资源的部分全部去掉即可
codebert论文实验复现_暂停
- 省时:os用linux,python用3.6,有GPU,应该就能运行...
- 1. 资料准备
- 2.环境准备(python36+linux+torch1.4)—>需要GPU
-
- 2.0 linux环境准备
- 2.1 导包
- 2.2 下载处理好的数据集
- 2.3 微调Fine-Tune (环境:python36+linux)
- 2.4 报错,需要GPU
- 3. 接上,尝试cpu(python36+linux+torch_cpu)—>Torch与CUDA 不匹配
- 4.环境准备(python36+window)—>目前看来无法正常运行
-
- 4.1 导包
- 4.2 模型训练
- 4.3 下载相关的配置文件(roberta-basd、codebert-base等)
- 4.4 报错1:将倒数第二行的load改为loads (注意:此处直接改了torch的源码!)
- 4.5 继续报错2:
- 5. 最后
1. 资料准备
codebert论文直达
codebert的github源码
a.一篇看起来对新手很友好的codebert使用
b.一篇csdn的论文阅读
还在测试....
2.环境准备(python36+linux+torch1.4)—>需要GPU
2.0 linux环境准备
资源有限,用虚拟机centos7浅浅跑一下…
-
创建虚拟机,配置可参考
【动手学深度学习】环境配置(详细记录,从vmware虚拟机安装开始)
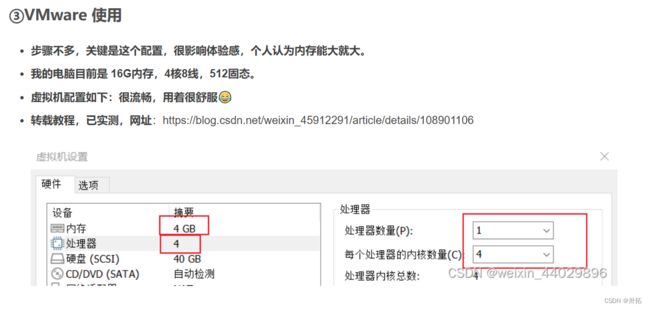
(我的机器是8G内存,也照着这个来了…) -
虚拟环境联网
-
用xshell或者共享文件夹把一部分代码放入虚拟机(不嫌慢重下代码和数据集也行~)→
-
配置python3.6环境(centos7自带python2.7,保险起见,搞了个miniconda,创建python3.6版本的虚拟环境并在这个环境里运行)
-
在指定目录里,进入虚拟环境
conda activate 创建的环境名
2.1 导包
pip install torch==1.4.0
pip install transformers==2.5.0
pip install filelock
2.2 下载处理好的数据集

需要科学一下
放弃科学,直接piao
2.3 微调Fine-Tune (环境:python36+linux)
论文作者在 4*P40 GPUs 上运行的
我的小破本,还是改改参数吧…
具体是,把batch_size改为4,参考第一部分的博客a:将batch_size=128改为batch_size=4,这是因为GPU的内存不够,太大的bs会导致OOM。
#论文作者给的参数,注:作者是在 4*P40 GPUs 上运行的
cd code2nl
lang=php #programming language
lr=5e-5
batch_size=64
beam_size=10
source_length=256
target_length=128
data_dir=../data/code2nl/CodeSearchNet
output_dir=model/$lang
train_file=$data_dir/$lang/train.jsonl
dev_file=$data_dir/$lang/valid.jsonl
eval_steps=1000 #400 for ruby, 600 for javascript, 1000 for others
train_steps=50000 #20000 for ruby, 30000 for javascript, 50000 for others
pretrained_model=microsoft/codebert-base #Roberta: roberta-base
python run.py --do_train --do_eval --model_type roberta --model_name_or_path $pretrained_model --train_filename $train_file --dev_filename $dev_file --output_dir $output_dir --max_source_length $source_length --max_target_length $target_length --beam_size $beam_size --train_batch_size $batch_size --eval_batch_size $batch_size --learning_rate $lr --train_steps $train_steps --eval_steps $eval_steps
#确认参数及路径无误后,直接复制以上代码,在终端的python环境里运行即可
运行到index 4,出现“已杀死”,程序终止,猜测遇到OOM,改改参数,体验一下运行成功的快乐…
03/27/2023 09:21:26 - INFO - __main__ - target_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
已杀死
#或者在下一步被杀死
#(ruby的参数最小,但是train_steps都从20000改到500了,还是跑不动...)
03/27/2023 10:00:47 - INFO - __main__ - ***** Running training *****
03/27/2023 10:00:47 - INFO - __main__ - Num examples = 24927
03/27/2023 10:00:47 - INFO - __main__ - Batch size = 4
03/27/2023 10:00:47 - INFO - __main__ - Num epoch = 0
loss 12.933: 0%| | 0/500 [00:22<?, ?it/s]已杀死
减小参数,修改之后:
cd code2nl
lang=ruby #programming language
lr=0.001
batch_size=1 #改之前:64
beam_size=1 #改之前:10
source_length=256
target_length=128
data_dir=./CodeSearchNet #改之前:../data/code2nl/CodeSearchNet
output_dir=model/$lang
train_file=$data_dir/$lang/train.jsonl
dev_file=$data_dir/$lang/valid.jsonl
eval_steps=1 #浅浅运行一下,图一乐呵
train_steps=1 #浅浅运行一下,图一乐呵
pretrained_model=microsoft/codebert-base #用的是预训练模型是codebert
python run.py --do_train --do_eval --model_type roberta --model_name_or_path $pretrained_model --train_filename $train_file --dev_filename $dev_file --output_dir $output_dir --max_source_length $source_length --max_target_length $target_length --beam_size $beam_size --train_batch_size $batch_size --eval_batch_size $batch_size --learning_rate $lr --train_steps $train_steps --eval_steps $eval_steps
2.4 报错,需要GPU
Traceback (most recent call last):
File "run.py", line 524, in <module>
main()
File "run.py", line 440, in main
preds = model(source_ids=source_ids,source_mask=source_mask)
File "/root/miniconda3/envs/codebert/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/root/桌面/codebert/code2nl/model.py", line 77, in forward
zero=torch.cuda.LongTensor(1).fill_(0)
File "/root/miniconda3/envs/codebert/lib/python3.6/site-packages/torch/cuda/__init__.py", line 196, in _lazy_init
_check_driver()
File "/root/miniconda3/envs/codebert/lib/python3.6/site-packages/torch/cuda/__init__.py", line 101, in _check_driver
http://www.nvidia.com/Download/index.aspx""")
AssertionError:
Found no NVIDIA driver on your system. Please check that you
have an NVIDIA GPU and installed a driver from
http://www.nvidia.com/Download/index.aspx
3. 接上,尝试cpu(python36+linux+torch_cpu)—>Torch与CUDA 不匹配
重建虚拟环境 codebert_cpu
cpu版本的torch安装:
遇到报错:type torch.cuda.LongTensor not available. Torch not compiled with CUDA enabled.
参考:报错:Torch not compiled with CUDA enabled看这一篇就足够了
参考CentOS下的CUDA安装和使用指南
4.环境准备(python36+window)—>目前看来无法正常运行
4.1 导包
pip3 install torch==1.4.0
# 如果上边不行,py36可以试一下:pip3 install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
pip3 install transformers==2.5.0
pip3 install filelock
4.2 模型训练
将最后一行的参数改为具体值,在控制台运行(否则我也想不到什么好办法…)
ps:此处建议把batch_size=64改为batch_size=4,在第一部分的a博客里提到:这是因为GPU的内存不够,太大的bs会导致OOM
cd code2nl
lang=php #programming language
lr=5e-5
batch_size=64 #建议改一下
beam_size=10
source_length=256
target_length=128
data_dir=../data/code2nl/CodeSearchNet
output_dir=model/$lang
train_file=$data_dir/$lang/train.jsonl
dev_file=$data_dir/$lang/valid.jsonl
eval_steps=1000 #400 for ruby, 600 for javascript, 1000 for others
train_steps=50000 #20000 for ruby, 30000 for javascript, 50000 for others
pretrained_model=microsoft/codebert-base #Roberta: roberta-base
python run.py --do_train --do_eval --model_type roberta --model_name_or_path $pretrained_model --train_filename $train_file --dev_filename $dev_file --output_dir $output_dir --max_source_length $source_length --max_target_length $target_length --beam_size $beam_size --train_batch_size $batch_size --eval_batch_size $batch_size --learning_rate $lr --train_steps $train_steps --eval_steps $eval_steps
#需要手动把上方$参数名 改为实际参数~
4.3 下载相关的配置文件(roberta-basd、codebert-base等)
如果(国内)遇到如下报错,就是被墙了,可以把资源下到本地,如果没遇到,无视掉
torch
huggingface
- microsoft/codebert-base
- roberta-base
OSError: Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-config.json' to download pretrained model configuration file.
roberta-base资源在这,具体过程参考:Transformers(Huggingface)包调用Roberta需要修改预训练文件名称
可以学习一下:hugging face 模型库的使用及加载 Bert 预训练模型
4.4 报错1:将倒数第二行的load改为loads (注意:此处直接改了torch的源码!)
Traceback (most recent call last):
File "run_csdn.py", line 548, in <module>
main()
File "run_csdn.py", line 290, in main
model.load_state_dict(torch.load(args.load_model_path))
File "E:\Anaconda\envs\codebert\lib\site-packages\torch\serialization.py", line 529, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "E:\Anaconda\envs\codebert\lib\site-packages\torch\serialization.py", line 693, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: invalid load key, '{'.
4.5 继续报错2:
Traceback (most recent call last):
File "E:\Anaconda\envs\codebert\lib\site-packages\transformers\modeling_utils.py", line 467, in from_pretrained
state_dict = torch.load(resolved_archive_file, map_location="cpu")
File "E:\Anaconda\envs\codebert\lib\site-packages\torch\serialization.py", line 529, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "E:\Anaconda\envs\codebert\lib\site-packages\torch\serialization.py", line 693, in _legacy_load
magic_number = pickle_module.loads(f, **pickle_load_args) #2023.03.25为了codebert修改成本行,报错byteb编码
TypeError: a bytes-like object is required, not '_io.BufferedReader'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_csdn.py", line 548, in <module>
main()
File "run_csdn.py", line 282, in main
encoder = model_class.from_pretrained(args.model_name_or_path,config=config)
File "E:\Anaconda\envs\codebert\lib\site-packages\transformers\modeling_utils.py", line 470, in from_pretrained
"Unable to load weights from pytorch checkpoint file. "
OSError: Unable to load weights from pytorch checkpoint file. If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
暂时还不知道咋改…
5. 最后
有没有佬运行成功了,分享一下哇,想白嫖
