TENER: Adapting Transformer Encoder for Name Entity Recognition
TENER: Adapting Transformer Encoder for Name Entity Recognition
来源:arxiv
链接:https://arxiv.org/pdf/1911.04474.pdf
代码:暂无
目录
预备知识
NER
Transformer
解决方法
论文改进的TENER模型
CRF layer解码
实验结果
数据集
总结
Transformer模型以其良好的并行性能力以及出色的效果,被广泛应用于nlp领域的各大任务,例如机器翻译,预训练语言模型等。博客(https://zhuanlan.zhihu.com/p/54743941)也从多个方面,实验论证Transformer模型优于CNN和RNN模型。然而,在NER任务上,Transformer的效果远不如Bilstm。
预备知识
NER
命名实体识别, 简称NER,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字,通常被看做是序列标注任务,现有主流的方法是使用神经网络来做,包括三个部分:词向量层,上下文编码层,解码层。
Transformer
Transformer layer包含两个部分:Multi-Head Attention (MHA) 和 Position-wise Feed-Forward Network (FFN)。
MHA:
单个attention head计算方式:
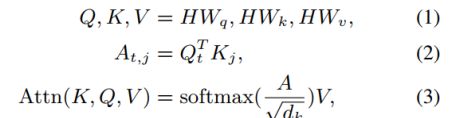
多个attention head计算方式:
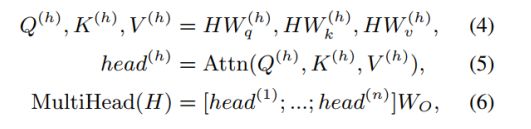
FFN:
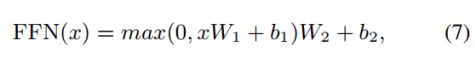
MHA层和FFN层之间,以及FFN层之后还包含一个残差连接和norm层。详细可见论文 https://arxiv.org/pdf/1706.03762.pdf
解决方法
论文分析了Transformer在NER任务上效果不好的原因,并提出了改进方法TENER (Transformer Encoder for NER)。
Transformer在NER任务上效果不好的原因

如Figure1所示,方向信息以及相对位置,对于NER任务是重要的。例如,“Inc”单词之前的词很有可能就是机构组织(ORG),“in”单词之后的词,很有可能是时间地点(TIME);并且一个实体应该是连续的单词组成,标红的“Louis Vuitton”不会和标蓝的“Inc”组成一个实体。 但是原始的Transformer无法捕获这些信息。争对上述问题,论文提出了两点改进:(1)提出带有方向与相对位置信息的atteniton机制;(2)丢弃了原有Transformer self-attention的scale factor,scale factor的引入是为了得到分布相对均匀的attention权重,但是在NER中,并不需要关注所有词。另外,除了使用Transformer来建模词级别的上下文信息,还使用Transformer来建模character级别信息。
论文改进的TENER模型
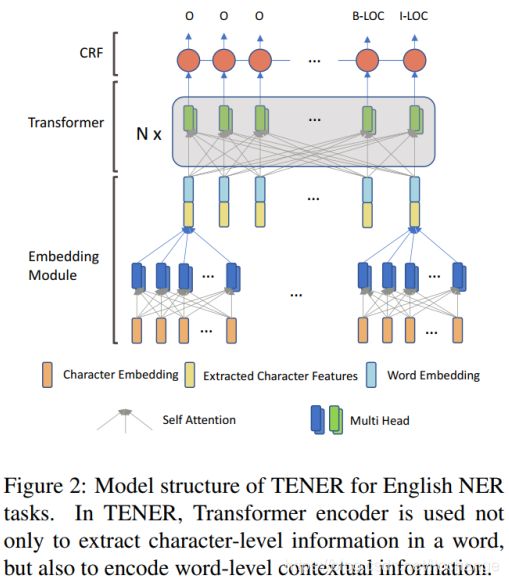
1. 词向量层
为了改善数据的稀疏性以及oov问题,NER任务通常使用CNN编码character序列来表示单词。与Bilstm相比,CNN在编码character序列上更有效,论文也探索了使用Transformer来编码character序列得到单词表征。最后的词向量表示,是character序列表征的单词与外部预训练词向量的拼接。
2. 带有方向与相对位置信息的atteniton机制
原始transformer encoder使用如下公式来获得位置向量:

t是单词在文本中的位置,d是位置向量的维度,也是词向量的维度,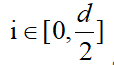 根据公式,分别计算位置向量中奇数维度和偶数维度的值。论文指出,根据公式(8)(9)得到的位置向量仅仅带有相对位置信息,而不包括方向信息,证明如下:
根据公式,分别计算位置向量中奇数维度和偶数维度的值。论文指出,根据公式(8)(9)得到的位置向量仅仅带有相对位置信息,而不包括方向信息,证明如下:
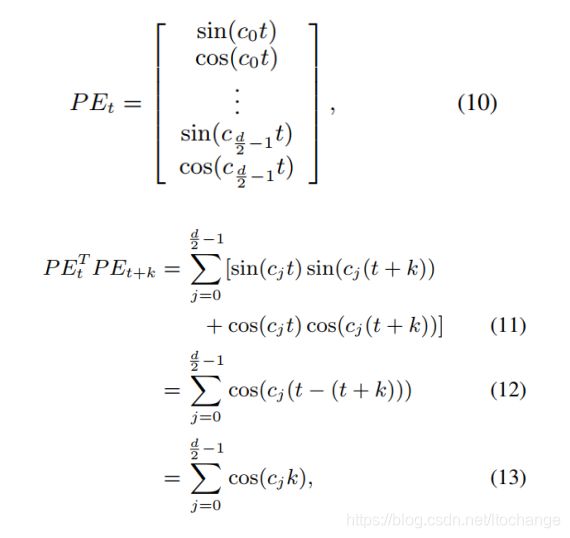
其中,![]() 是一个常量
是一个常量![]() ;公式(11)到公式(12)由公式
;公式(11)到公式(12)由公式![]() 得到。由公式(13)可知,第t个位置的位置向量
得到。由公式(13)可知,第t个位置的位置向量![]() 与第t+k个位置的位置向量
与第t+k个位置的位置向量![]() 相乘,得到的结果只与相对位置k有关。并且,令
相乘,得到的结果只与相对位置k有关。并且,令![]() ,可得:
,可得:

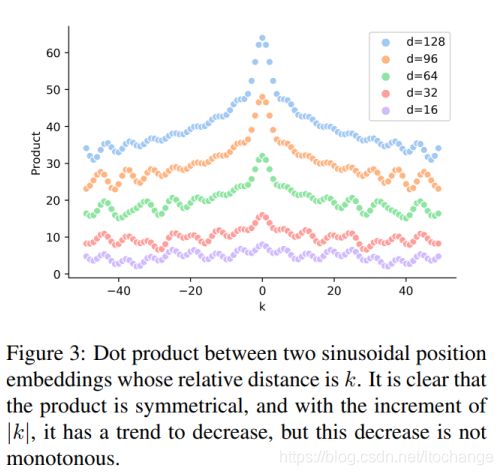
公式(14)(15)更进一步说明了,根据公式(8)(9)得到的位置向量仅仅带有相对位置信息,而不包括方向信息,fingure3也证明了这个结论。
更重要的是,在计算self-attention时,仅能捕获的相对位置信息这一特性,也会消失。由公式(1)可知,在进行self-attention时,首先需要经过矩阵![]() ,
,![]() 将H(位置向量和词向量的组合)转化到相应的空间。实际上,两个位置向量
将H(位置向量和词向量的组合)转化到相应的空间。实际上,两个位置向量![]() ,
,![]() 进行的运算为:
进行的运算为: (
(![]() 被看成一个矩阵,可得
被看成一个矩阵,可得![]() )。随机采样两个W,绘出
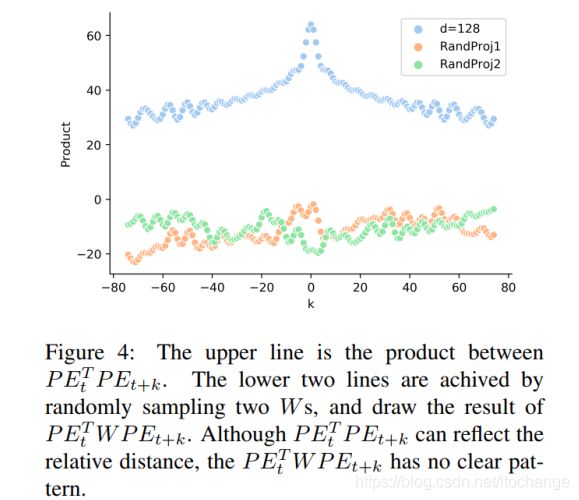
)。随机采样两个W,绘出![]() 结果图,如fingure4所示,在没有进行矩阵转换时,位置向量可以捕获相对位置信息,经过矩阵转换后,即进行self-attention时,相对位置信息被破坏。
结果图,如fingure4所示,在没有进行矩阵转换时,位置向量可以捕获相对位置信息,经过矩阵转换后,即进行self-attention时,相对位置信息被破坏。
论文使用如下公式代替公式(1)-(3)以及公式(8)(9),来计算self-attention,同时捕获相对位置信息和方向信息:公式(16)与公式(1)相比,K不再经过![]() 映射的;t是目标token的索引,j是上下文token的索引,公式(17)在进行位置编码时,引入了相对位置以及方向信息,距离为t(j=0)与距离为-t(j=2t)的两个位置的位置向量在奇数维度上是不同的,偶数维度上是相同的,如公式(20)所示。公式(18)在计算attention权值时,将词向量与位置向量分开计算(位置对NER任务来说时及其重要的),并且加了偏置项。公式(19)相比公式(3)去掉了
映射的;t是目标token的索引,j是上下文token的索引,公式(17)在进行位置编码时,引入了相对位置以及方向信息,距离为t(j=0)与距离为-t(j=2t)的两个位置的位置向量在奇数维度上是不同的,偶数维度上是相同的,如公式(20)所示。公式(18)在计算attention权值时,将词向量与位置向量分开计算(位置对NER任务来说时及其重要的),并且加了偏置项。公式(19)相比公式(3)去掉了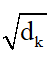 。
。
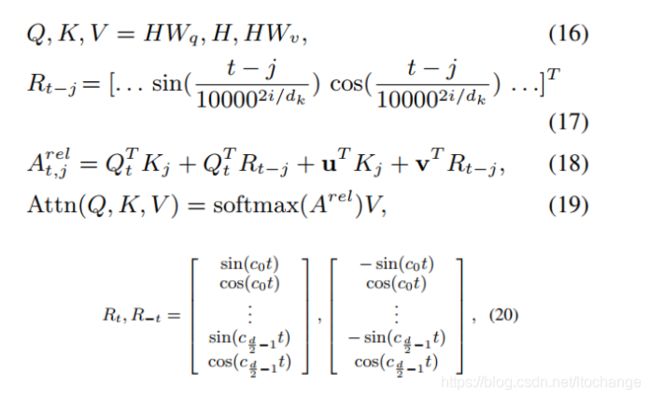
问题是,K不再是经过![]() 映射的,所以K的维度是和词向量维度一样为d,是无法与
映射的,所以K的维度是和词向量维度一样为d,是无法与![]() (维度为
(维度为![]() )进行矩a阵相乘的运算的。论文作者也表示,这里存在一些笔误,想要表达的意思是,计算每一个attention head从K(也就是H)依次选取0到
)进行矩a阵相乘的运算的。论文作者也表示,这里存在一些笔误,想要表达的意思是,计算每一个attention head从K(也就是H)依次选取0到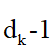 维度,
维度, ![]() 到
到![]() 维度,依此类推。
维度,依此类推。
CRF layer解码
同先前Bilstm+CRF,主要是为了将不同tag之间的依赖信息引入。给定输入序列:![]() ,以及标注
,以及标注![]() 。
。![]() 代表所有可能的标注序列。标注y的概率计算如下公式:
代表所有可能的标注序列。标注y的概率计算如下公式:
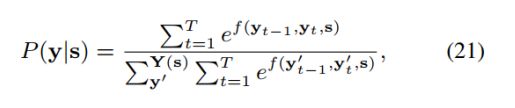
其中,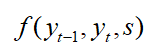 计算从标注
计算从标注![]() 到标注
到标注![]() 的转移分数以及
的转移分数以及![]() 的分数,优化的目标是最大化
的分数,优化的目标是最大化![]() 。解码时,使用维特比算法,选择概率最大的y。
。解码时,使用维特比算法,选择概率最大的y。
实验结果
数据集
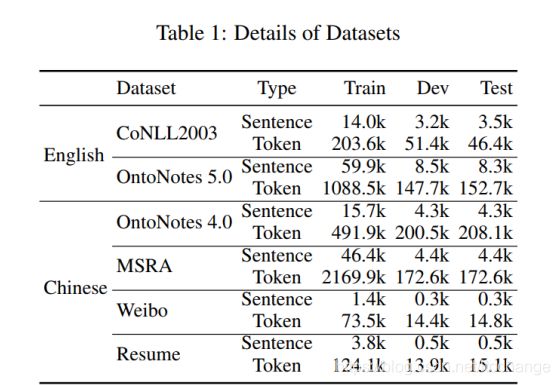
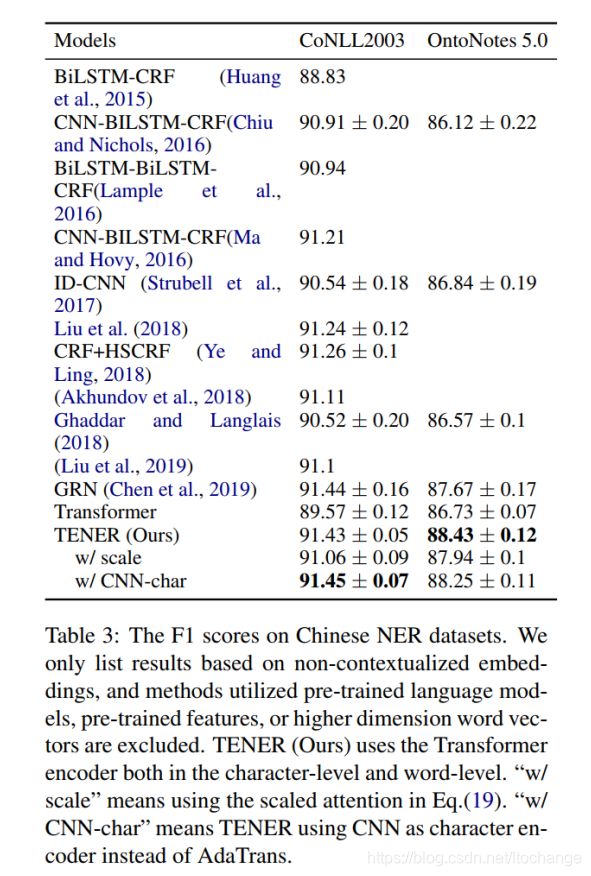
在中文数据集上的结果(table1),中文的NER是直接基于字的:

- TENER的效果不仅优于原有的Transformer模型,而且优于基于CNN的模型和基于Bilstm的模型. 其中因为CAN_NER使用了100维的预训练的字向量和bigram向量,所以效果较好。
- Weibo数据集相对较小,因此不同的模型在这个数据集上的表现效果都比较差。TENER模型相比其他模型也提高了效果,这也表明,本论文提出的改进方法,对数据集的大小具有一定的鲁棒性
- 带scale factor的self-attention会使得结果变差。
在英文数据集上的效果(table2):
- TENER在英文数据集上的效果不仅优于原有的Transformer模型,而且优于基于Bilstm的模型,并取得了当前最好的结果。
- 同样带scale factor的self-attention会使得结果变差。
不同的character编码器和word上下文编码器的组合结果(table4):
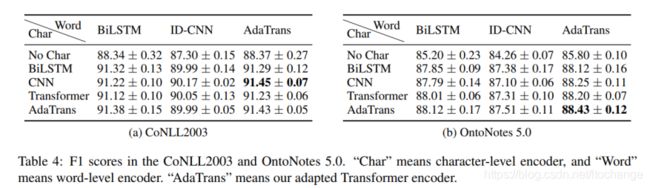
在两个英文数据集上,比较了不同的character编码器和word上下文编码器的组合结果,由table4可看出,在conll2013数据集上,基于CNN的character编码器+基于TENER的word上下文编码器取得了最好的效果;然而在OntoNote 5.0上,全部使用TENER模型取得了最好的效果。但是无论使用什么样的character编码器甚至不使用character编码,换用TENER模型建模word上下文都可以提升效果。
收敛速度的比较(figure5):
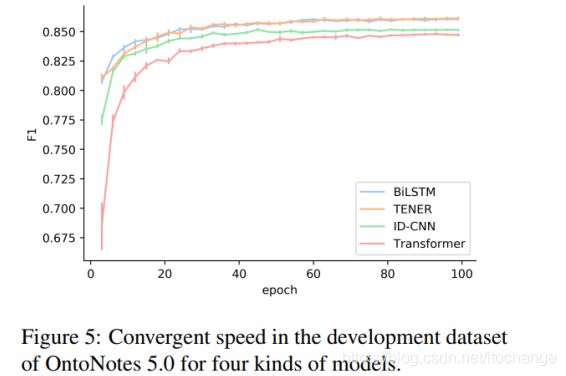
NER模型的收敛速度与Bilstm相等,比transformer和ID-CNN要快。
总结
- 分析了Transformer 在NER任务上效果不好的原因
- 改进了Transformer的位置编码及self-attention部分(TENER模型),用于NER,取得了较好的效果,在两个英文数据集上,达到了当前最好的效果。
- 论文比较出彩的地方在于对Transformer 在NER任务上效果不好原因的分析。对self-attention的改进有点类似Transformer XL。