深度学习--猫狗大战pytorch实战
文章目录
-
- 数据准备&处理
- 模型构建
- 训练
kaggle上的一个经典项目,拿来做做算是当CNN入门了,做的比较粗糙简单
我把整个项目分成了四块

config用来配置一些参数,Dataset用来构建数据集
Main用来训练和保存数据等,Module用来放构建的模型
config的配置如下
TRAIN_PATH = r'D:\temp\train'
PRE_PATH = r'D:\temp\test1'
BATCH_SIZE = 200 # batch_size
PIC_SIZE = 100 # 图片的大小
数据准备&处理
这里我都写在了Dataset文件里。
数据来源于kaggle官网https://www.kaggle.com/c/dogs-vs-cats去下载即可。
一共有三个文件,一个csv文件用于提交,剩下两个是一个用于训练的,一个用于预测的。
瞅一眼训练集,就会发现其label是直接贴在图片名字上的,那这里在处理时就需要匹配一下字符串。
再者就是,kaggle没有划分出训练集和测试集,这里应该手动划分一下。(其实应该划分成训练集,验证集,测试集,不过当时忘了)
首先导入必要的包
import os
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
import torch
import random
import config
pytorch的数据集都是继承自Dataset的,所以我们要定义一个类
class Cat_Vs_DogDatasets(Dataset):
pass
然后构建的思路大致就是,给出一个图片名字的列表,然后根据路径合成图片路径,然后挨个导入。
class Cat_Vs_DogDatasets(Dataset):
def __init__(self, path: str, imglist: list, s: int=config.PIC_SIZE):
self.path = path # 图片文件夹路径
self.compose = transforms.Compose([ # 图片processing
transforms.Resize(size=s), # 按照比例,把最小的边缩放成s大小
transforms.CenterCrop(size=s), # 裁剪为s乘s的图片
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
self.imglist = imglist # 图片名词列表
self.len = len(imglist)
def __getitem__(self, idx: int):
name = self.imglist[idx]
label = 0
if name[:3] == 'cat': # 获取label
label = 1
return self.compose(Image.open(os.path.join(self.path, name) ,mode='r')), torch.tensor(label, dtype=torch.int64)
def __len__(self):
return self.len
然后,我们就构建出了一个数据集的结构,接下来需要对数据进行划分。我们对数据的划分可以直接通过对图片名称的列表的划分来实现。
def train_test_split(path, test_size=0.15, random_state:int=666, s: int=config.PIC_SIZE):
imglist = os.listdir(path) # 把所有图片的名词导入
random.seed(random_state)
random.shuffle(imglist) #打乱顺序
train_size = int((1 - test_size) * len(imglist)) # 计算训练集代销
train = imglist[:train_size] # 训练集
test = imglist[train_size:] # 测试集
return Cat_Vs_DogDatasets(path, imglist=train, s=s), Cat_Vs_DogDatasets(path, imglist=test, s=s) # 生成
到此为止,数据准备完毕。
模型构建
这里随便做了个模型,有两个卷积层,池化层,然后接上一个双层全连接网络。
import torch
from torch import nn
import config
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cv1 = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5, stride=1, padding=0)
self.cv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5, stride=1, padding=0)
self.maxpooling = nn.MaxPool2d(kernel_size=2)
self.acFun = nn.functional.relu
self.liner1 = nn.Linear(9680, 80)
self.liner2 = nn.Linear(80, 2)
def forward(self, x):
x = self.acFun(self.cv1(x))
x = self.maxpooling(x)
x = self.acFun(self.cv2(x))
x = self.maxpooling(x)
x = x.view(x.shape[0], -1)
x = self.acFun(self.liner1(x))
x = self.acFun(self.liner2(x))
return x
模型这里,我图片的大小是100 × 100的,之所以搞得这么小是因为显卡内存有限,不过100×100辨析度也不是差。
训练
训练这里,使用的优化器是SGD,损失函数是交叉熵函数。
import Dataset
import Module
import config
import torch
device = torch.device('cuda:0')
train, test = Dataset.train_test_split(config.TRAIN_PATH)
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=config.BATCH_SIZE, num_workers=4, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=config.BATCH_SIZE)
moudle = Module.CNN().to(device)
sgd = torch.optim.SGD(params=moudle.parameters(), lr=0.01, momentum=0.15)
loss_fun = torch.nn.functional.cross_entropy
这里有一个问题,在使用SGD时我发现当lr过大时,loss出现了不下降也不上升的的情况,我有点迷现在也没搞清楚怎么解释,于是我把lr调的小了一点,然后适当的调大一点Momentum的大小。
然后写了一个计算ACC的函数
def OutPutACC():
with torch.no_grad():
A = 0
for batch in test_loader:
X, y = batch
X = X.to(device)
y = y.to(device)
pre = torch.argmax(moudle(X), dim=1)
A += (pre == y).sum().item()
print(A / len(test))
最后进行训练
if __name__ == '__main__':
for epoch in range(40):
for i, batch in enumerate(train_loader):
X, y = batch
X = X.to(device)
y = y.to(device)
pre = moudle(X)
loss = loss_fun(pre, y)
sgd.zero_grad()
loss.backward()
sgd.step()
if i % 10 == 0:
print(loss)
OutPutACC()
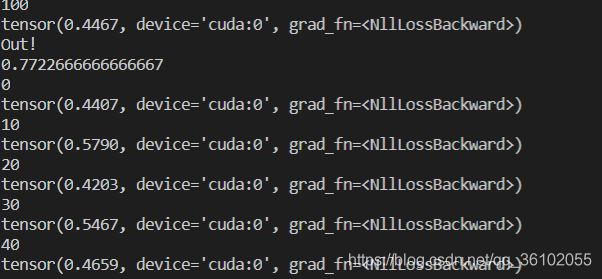
训练了40轮,大概用了20分钟,最终得到的模型在测试集上的ACC有77.2%。模型显然还是欠拟合,训练轮数还可以继续增加。
最后附上整个项目链接
https://github.com/zipper112/CatvsDog