scrapy爬虫框架
目录
Scrapy的介绍
Scarpy开发第一个爬虫
Scrapy项目的启动介绍
Scrapy启动-命令启动
Scrapy启动-脚本启动
Scrapy 数据的提取
Scrapy 保存数据到文件
Item Pipeline的使用
Scrapy 使用ImagePipeline 保存图片
Scrapy 自定义ImagePipeline
Scrapy 中settings配置 的使用
Scrapy 中 Request 的使用
Scrapy的介绍

Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,可 用于各种有用的应用程序,如数据挖掘、信息处理或历史存档。 尽管 Scrapy 最初是为网络抓取而设计的,但它也可用于使用 API提取数据或用作通用网络爬虫。
Scrapy的优势
- 可以容易构建大规模的爬虫项目
- 内置re、xpath、css选择器
- 可以自动调整爬行速度
- 开源和免费的网络爬虫框架
- 可以快速导出数据文件: JSON,CSV和XML
- 可以自动方式从网页中提取数据(自己编写规则)
- Scrapy很容易扩展,快速和功能强大
- 这是一个跨平台应用程序框架(在Windows,Linux,Mac OS)
- Scrapy请求调度和异步处理
Scrapy的架构
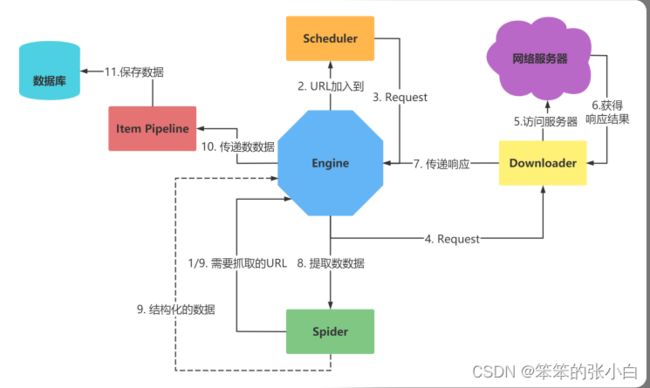
最简单的单个网页爬取流程是 spiders > scheduler > downloader > spiders > item pipeline 省略了engine环节!
- 引擎(engine)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL (抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时 去除重复的网址
- 下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步 模型上的) 爬虫(Spiders) 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可 以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需 要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
- 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应
- 爬虫中间件(Spider Middlewares)
- 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出
- 调度中间件(Scheduler Middewares)
- 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
安装
pip install scrapyScarpy开发第一个爬虫

创建第一个项目
scrapy startproject myfrist(project_name)
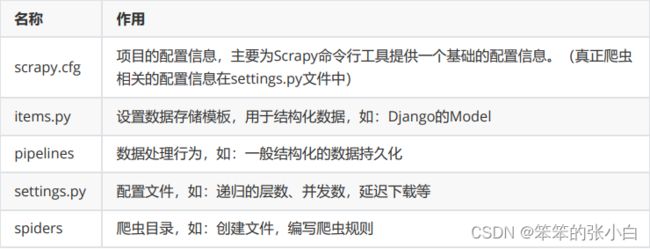
文件说明
创建第一个爬虫
scrapy genspider 爬虫名 爬虫的地址注意:一般创建爬虫文件时,以网站域名命名
爬虫包含的内容
- name: 它定义了蜘蛛的唯一名称
- allowed_domains: 它包含了蜘蛛抓取的基本URL;
- start-urls: 蜘蛛开始爬行的URL列表;
- parse(): 这是提取并解析刮下数据的方法;
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = 'douban.com'
start_urls = ['https://movie.douban.com/top250/']
def parse(self, response):
movie_name = response.xpath("//div[@class='item']//a/span[1]/text()").extract()
movie_core = response.xpath("//div[@class='star']/span[2]/text()").extract()
yield {
'movie_name':movie_name,
'movie_core':movie_core
}Scrapy项目的启动介绍

- Scrapy启动的方式有多种方式:
- Scrapy命令运行
- 运行环境
- 命令行:cmd/powershell/等等
- 运行环境
- 运行Python脚本
- 运行环境
- 命令行:cmd/powershell/等等
- 编辑器:VSCode/PyCharm等等
- 运行环境
- Scrapy命令运行
注意 运行程序之前,要确认网站是否允许爬取 robots.txt 文件
Scrapy启动-命令启动
scrapy命令 scrapy框架提供了对项目的命令scrapy ,具体启动项目命令格式如 下:
方法1:
scrapy crawl 爬虫名注意 这的爬虫名是爬虫文件中name属性的值
方法2:
scrapy runspider spider_file.py注意 这是爬虫文件的名字 要指定到spider文件夹
Scrapy启动-脚本启动
Scrapy为开发者设置好了启动好的对象。因此,我们通过脚本即可 启动Scrapy项目
运行脚本
在项目的目录下,创建脚本,比如项目名为:scrapy01,创建脚本 的路径为 scrapy01\scrapy01\脚本.py
脚本
使用cmdline
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', '爬虫名字'])使用CrawlerProcess
from scrapy.crawler import CrawlerProcess
from spiders.baidu import BaiduSpider
process = CrawlerProcess()
process.crawl(BaiduSpider)
process.start()运行
命令行运行
python 脚本.pyScrapy 数据的提取

Scrapy有自己的数据提取机制。它们被称为选择器。我们可以通过 使用的选择器re、xpath、css提取数据。
提示 不用再安装与引入Xpath,BS4
获得选择器
Response对象获取
正常使用
response.selector.xpath('//span/text()').get()
response.selector.css('span::text').get()
response.selector.re('')快捷使用
response.xpath('//span/text').get()
response.css('span::text').get()创建对象
from scrapy.selector import Selector
通过text参数 初始化
body = 'good'
Selector(text=body).xpath('//span/text()').get()通过response参数 初始化
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
response = HtmlResponse(url='http://example.com',body=body)
Selector(response=response).xpath('//span/text()').get()
'good'选择器的方法

Scrapy 保存数据到文件

1.用Python原生方式保存
with open("movie.txt", 'wb') as f:
for n, c in zip(movie_name,movie_core):
str = n+":"+c+"\n"
f.write(str.encode())2.使用Scrapy内置方式
scrapy 内置主要有四种:JSON,JSON lines,CSV,XML 最常用的导出结果格为JSON,命令如下:
scrapy crawl dmoz -o douban.json -t json 参数设置:
- -o 后面导出文件名
- -t 后面导出的类型 可以省略,但要保存的文件名后缀,写清楚类型
注意
将数据解析完,返回数据,才可以用命令保存,代码如下,格 式为dict或item类型
- return data
- yield data
Item Pipeline的使用

当数据在Spider中被收集之后,可以传递到Item Pipeline中统一进 行处理
特点
每个item pipeline就是一个普通的python类,包含的方法名如下:

功能
- 1.接收item
- 在 process_item 方法中保存
- 2 是否要保存数据
- 取决于是否编写代码用于保存数据
- 3 决定此Item是否进入下一个pipeline
- return item 数据进入下一个pipeline
- drop item 抛弃数据
案例代码
class SaveFilePipeline:
def open_spider(self,spider):
self.file = open('douban5.txt','w')
def process_item(self, item, spider):
self.file.write(f'name:{item.get("name")} score:{item.get("score")}\n')
def close_spider(self,spider):
self.file.close()from scrapy.exceptions import DropItem
class XSPipeline:
def open_spider(self,spider):
self.file = open('xs.txt','w',encoding='utf-8')
def process_item(self, item, spider):
if item.get('title'):
self.file.write(item.get('title'))
self.file.write('\n')
return item
else:
raise DropItem(f"Missing title in {item}")
def close_spider(self,spider):
self.file.close()Scrapy 使用ImagePipeline 保存图片

Scrapy提供了一个 ImagePipeline,用来下载图片这条管道,图片管 道 ImagesPipeline 提供了方便并具有额外特性的功能,比如:
- 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
- 避免重新下载最近已经下载过的图片
- 缩略图生成
- 检测图像的宽/高,确保它们满足最小限制
使用图片管道
scrapy.pipelines.images.ImagesPipeline使用 ImagesPipeline ,典型的工作流程如下所示:
- 1 在一个爬虫中,把图片的URL放入 image_urls 组内(image_urls是个列表)
- 2 URL从爬虫内返回,进入图片管道
- 3 当图片对象进入 ImagesPipeline,image_urls 组内的URLs将被Scrapy的调度器和下载器安排下载
- 4 settings.py文件中配置保存图片路径参数 IMAGES_STORE
- 5 开启管道
注意 需要安装pillow4.0.0以上版本 pip install pillow==9.2.0
Scrapy 自定义ImagePipeline

问题
使用官方默认图片管道,有如下几个问题:
- 文件名不友好
- 存储图片URL的参数名称与类型太固定
解决方案 自定义ImagePipeline,扩展
- 自定义图片管道
- 继承 scrapy.pipelines.images import ImagesPipeline
- 实现 get_media_requests(self, item, info) 方法
- 发送请求,下载图片
- 转发文件名
- 实现 file_path(self,request,response=None,info=None,*,item=None)
- 修改文件名与保存路径
Scrapy 中settings配置 的使用

Scrapy允许自定义设置所有Scrapy组件的行为,包括核心、扩展、 管道和spider本身。
官网-参考配置
设置 — Scrapy 2.5.0 文档 (osgeo.cn)https://www.osgeo.cn/scrap y/topics/settings.html
配置文档
BOT_NAME 默认: 'scrapybot' Scrapy项目实现的bot的名字。用来构造默认 User-Agent,同时 也用来log。 当你使用 startproject 命令创建项目时其也被自动赋值。
CONCURRENT_ITEMS 默认: 100 Item Processor(即 Item Pipeline) 同时处理(每个response 的)item的最大值
CONCURRENT_REQUESTS 默认: 16 Scrapy downloader 并发请求(concurrent requests)的最大 值。
CONCURRENT_REQUESTS_PER_DOMAIN 默认: 8 对单个网站进行并发请求的最大值。 CONCURRENT_REQUESTS_PER_IP 默认: 0 对单个IP进行并发请求的最大值。如果非0,则忽略 CONCURRENT_REQUESTS_PER_DOMAIN 设定, 使用该设 定。 也就是说,并发限制将针对IP,而不是网站。 该设定也影响 DOWNLOAD_DELAY: 如果 CONCURRENT_REQUESTS_PER_IP 非0,下载延迟应用在IP而 不是网站上。 FEED_EXPORT_ENCODING ='utf-8' 设置导出时文件的编码
Scrapy 中 Request 的使用

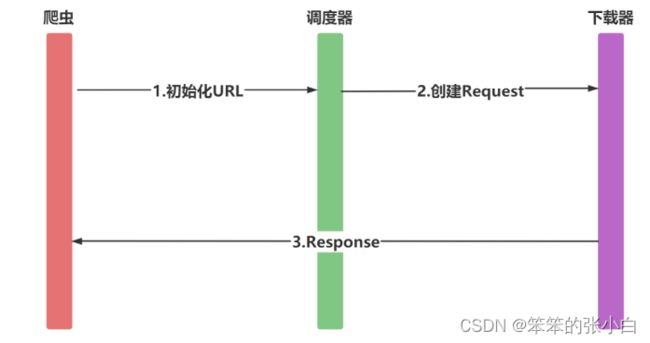
爬虫中请求与响应是最常见的操作,Request对象在爬虫程序中生 成并传递到下载器中,后者执行请求并返回一个Response对象
Request对象
class scrapy.http.Request(url[, callback,method='GET', headers, body, cookies, meta,encoding='utf-8', priority=0,dont_filter=False, errback])一个Request对象表示一个HTTP请求,它通常是在爬虫生成,并由 下载执行,从而生成Response 参数
- url(string) - 此请求的网址
- callback(callable) - 将使用此请求的响应(一旦下载)作 为其第一个参数调用的函数。有关更多信息,请参阅下面的 将附加数据传递给回调函数。如果请求没有指定回调, parse()将使用spider的 方法。请注意,如果在处理期间引发 异常,则会调用errback。
- method(string) - 此请求的HTTP方法。默认为'GET'。可 设置为"GET", "POST", "PUT"等,且保证字符串大写
- meta(dict) - 属性的初始值Request.meta,在不同的请求之 间传递数据使用
- body(str或unicode) - 请求体。如果unicode传递了,那 么它被编码为 str使用传递的编码(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的类 型,存储的最终值将是一个str(不会是unicode或None)。
- headers(dict) - 这个请求的头。dict值可以是字符串(对 于单值标头)或列表(对于多值标头)。如果 None作为值 传递,则不会发送HTTP头.一般不需要 encoding: 使用默认的 'utf-8' 就行 dont_filter:是否过滤重复的URL地址,默认为 False 过滤
- cookie(dict或list) - 请求cookie。这些可以以两种形式发 送。
将附加数据传递给回调函数
请求的回调是当下载该请求的响应时将被调用的函数。将使用下载 的Response对象作为其第一个参数来调用回调函数
def parse_page1(self, response):
item = MyItem()
item['main_url'] = response.url
request = scrapy.Request("http://www.example.com/some_page.html",
callback=self.parse_page2)
request.meta['item'] = item
return request
def parse_page2(self, response):
item = response.meta['item']
item['other_url'] = response.url
return item