Redis数据结构
明天的你会感谢今天努力的你
举手之劳,加个关注
目录
简介
String
List
Hash
Set
SortedSet
BitMaps
HyperLogLogs
GEO
简介
Redis有5个基本数据结构,string、list、hash、set和zset,3个高级数据结构,它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这几个数据结构都吃透了,你就能应对大部分面试了,再结合对Redis底层实现的一些深入了解,应对面试轻松自如, 除此之外 redis 还有其他几个模块。

String
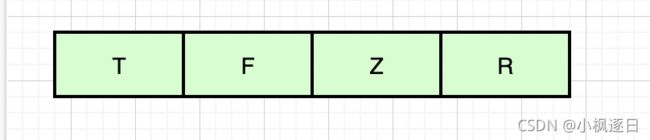
我们先来说说string。string表示一个可变的字节数组 , 我们初始化字符串的内容,可以拿到字符串的长度,通过调用不同的方法,我们可以获取string 的内容,可以覆盖 string 的内容,可以拼接内容。

Redis 的字符串是动态字符串,是可以修改的,内部结构实现上类似Java的ArrayList, 采用预分配冗余空间的方式来减少内存的频繁分配,这里在提一点NIO的buffer机制可以去看下,扩展下知识点。上面途中听(T)枫(F)逐(Z)日(R)+空白格是当前字符串实际分配的空间capacity 一般要高于实际字符串的len。 当字符串长度小于 1M时,扩容都是2倍扩容,如果超过 1M, 扩容的时候只会多扩1M的空间,特别注意的是字符串的长度为 512 M。
常用命令列表
可选参数
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:
-
EX seconds: 将键的过期时间设置为seconds秒。 执行SET key value EX seconds的效果等同于执行SETEX key seconds value。 -
PX milliseconds: 将键的过期时间设置为milliseconds毫秒。 执行SET key value PX milliseconds的效果等同于执行PSETEX key milliseconds value。 -
NX: 只在键不存在时, 才对键进行设置操作。 执行SET key value NX的效果等同于执行SETNX key value。 -
XX: 只在键已经存在时, 才对键进行设置操作。
因为
SET命令可以通过参数来实现SETNX、SETEX以及PSETEX命令的效果, 所以 Redis 将来的版本可能会移除并废弃SETNX、SETEX和PSETEX这三个命令。
返回值
在 Redis 2.6.12 版本以前, SET 命令总是返回 OK 。
从 Redis 2.6.12 版本开始, SET 命令只在设置操作成功完成时才返回 OK ; 如果命令使用了 NX 或者 XX 选项, 但是因为条件没达到而造成设置操作未执行, 那么命令将返回空批量回复(NULL Bulk Reply)
代码示例
对不存在的键进行设置:
redis> SET key "听枫逐日"
OKredis> GET key
"听枫逐日"对已存在的键进行设置:
redis> SET key "new-value"
OKredis> GET key
"new-value"使用 EX 选项:
redis> SET key-with-expire-time "hello" EX 10086
OKredis> GET key-with-expire-time
"hello"redis> TTL key-with-expire-time
(integer) 10069使用 PX 选项:
redis> SET key-with-pexpire-time "moto" PX 123321
OKredis> GET key-with-pexpire-time
"moto"redis> PTTL key-with-pexpire-time
(integer) 111939使用 NX 选项:
redis> SET not-exists-key "value" NX
OK # 键不存在,设置成功redis> GET not-exists-key
"value"redis> SET not-exists-key "new-value" NX
(nil) # 键已经存在,设置失败redis> GEt not-exists-key
"value" # 维持原值不变使用 XX 选项:
redis> EXISTS exists-key
(integer) 0redis> SET exists-key "value" XX
(nil) # 因为键不存在,设置失败redis> SET exists-key "value"
OK # 先给键设置一个值redis> SET exists-key "new-value" XX
OK # 设置新值成功redis> GET exists-key
"new-value"List

Redis将列表数据结构命名为list而不是array,是因为列表的存储结构用的是链表而不是数组,而且链表还是双向链表。因为它是链表,所以随机定位性能较弱,首尾插入删除性能较优。如果list的列表长度很长,使用时我们一定要关注链表相关操作的时间复杂度。
负下标 链表元素的位置使用自然数0,1,2,....n-1表示,还可以使用负数-1,-2,...-n来表示,-1表示「倒数第一」,-2表示「倒数第二」,那么-n就表示第一个元素,对应的下标为0。
队列/堆栈 链表可以从表头和表尾追加和移除元素,结合使用rpush/rpop/lpush/lpop四条指令,可以将链表作为队列或堆栈使用,左向右向进行都可以
常用命令列表
随机读 可以使用lindex指令访问指定位置的元素,使用lrange指令来获取链表子元素列表,提供start和end下标参数
> rpush wechat t f z r
(integer) 4
> lindex wechat 1
"t"
> lrange wechat 0 2
1) "t"
2) "f"
3) "z"
> lrange wechat 0 -1 # -1表示倒数第一
1) "t"
2) "f"
3) "z"使用lrange获取全部元素时,需要提供end_index,如果没有负下标,就需要首先通过llen指令获取长度,才可以得出end_index的值,有了负下标,使用-1代替end_index就可以达到相同的效果
修改元素 使用lset指令在指定位置修改元素
> rpush wechat t f z r
(integer) 4
> lset wechat 1 w
OK
> lrange wechat 0 -1
1) "t"
2) "w"
3) "z"插入元素 使用linsert指令在列表的中间位置插入元素,有经验的程序员都知道在插入元素时,我们经常搞不清楚是在指定位置的前面插入还是后面插入,所以antirez在linsert指令里增加了方向参数before/after来显示指示前置和后置插入。不过让人意想不到的是linsert指令并不是通过指定位置来插入,而是通过指定具体的值。这是因为在分布式环境下,列表的元素总是频繁变动的,意味着上一时刻计算的元素下标在下一时刻可能就不是你所期望的下标了。
删除元素 列表的删除操作也不是通过指定下标来确定元素的,你需要指定删除的最大个数以及元素的值
定长列表 在实际应用场景中,我们有时候会遇到「定长列表」的需求。比如要以走马灯的形式实时显示中奖用户名列表,因为中奖用户实在太多,能显示的数量一般不超过100条,那么这里就会使用到定长列表。维持定长列表的指令是ltrim,需要提供两个参数start和end,表示需要保留列表的下标范围,范围之外的所有元素都将被移除。
如果指定参数的end对应的真实下标小于start,其效果等价于del指令,因为这样的参数表示需要需要保留列表元素的下标范围为空。
快速列表(skiplist)
这块面试的时候深入考察的时候会问题,会衍生出好多问题
如果再深入一点,你会发现Redis底层存储的还不是一个简单的linkedlist,而是称之为快速链表quicklist的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
建议大家系统的看书或下载电子书阅读,加深自己的理解和体会。
Hash
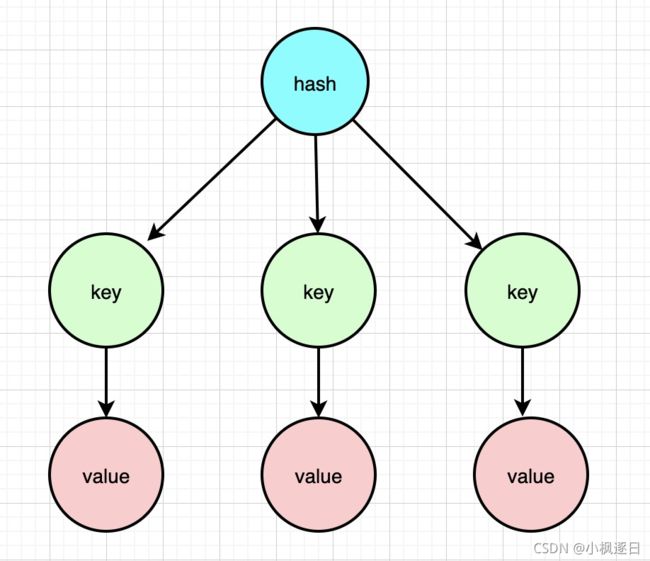
哈希等价于Java语言的HashMap或者是Python语言的dict,在实现结构上它使用二维结构(桶),第一维是数组,第二维是链表,hash的内容key和value存放在链表中,数组里存放的是链表的头指针。通过key查找元素时,先计算key的hashcode,然后用hashcode对数组的长度进行取模定位到链表的表头,再对链表进行遍历获取到相应的value值,链表的作用就是用来将产生了「hash碰撞」的元素串起来。Java语言开发者会感到非常熟悉,因为这样的结构和HashMap是没有区别的。哈希的第一维数组的长度也是2^n。
常用命令
增加元素 可以使用hset一次增加一个键值对,也可以使用hmset一次增加多个键值对
> hset wechat key tfzr
(integer) 1
> hmset wechat key t f z r
OK获取元素 可以通过hget定位具体key对应的value,可以通过hmget获取多个key对应的value,可以使用hgetall获取所有的键值对,可以使用hkeys和hvals分别获取所有的key列表和value列表。这些操作和Java语言的Map接口是类似的。
删除元素 可以使用hdel删除指定key,hdel支持同时删除多个key
判断元素是否存在 通常我们使用hget获得key对应的value是否为空就直到对应的元素是否存在了,不过如果value的字符串长度特别大,通过这种方式来判断元素存在与否就略显浪费,这时可以使用hexists指令
计数器 hash结构还可以当成计数器来使用,对于内部的每一个key都可以作为独立的计数器。如果value值不是整数,调用hincrby指令会出错。
扩容 当hash内部的元素比较拥挤时(hash碰撞比较频繁),就需要进行扩容。扩容需要申请新的两倍大小的数组,然后将所有的键值对重新分配到新的数组下标对应的链表中(rehash)。如果hash结构很大,比如有上百万个键值对,那么一次完整rehash的过程就会耗时很长。这对于单线程的Redis里来说有点压力山大。所以Redis采用了渐进式rehash的方案。它会同时保留两个新旧hash结构,在后续的定时任务以及hash结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象。
缩容 Redis的hash结构不但有扩容还有缩容,从这一点出发,它要比Java的HashMap要厉害一些,Java的HashMap只有扩容。缩容的原理和扩容是一致的,只不过新的数组大小要比旧数组小一倍。
Set
Java程序员都知道HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
常用命令列表
增加元素 可以一次增加多个元素
> sadd wechat t f z r
(integer) 4读取元素 使用smembers列出所有元素,使用scard获取集合长度,使用srandmember获取随机count个元素,如果不提供count参数,默认为1
删除元素 使用srem删除一到多个元素,使用spop删除随机一个元素
判断元素是否存在 使用sismember指令,只能接收单个元素
SortedSet(zset)
这一部分面试题也比较多,主侧重于在实际开发中的应用
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层实现使用了两个数据结构,第一个是hash,第二个是跳跃列表,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃列表的目的在于给元素value排序,根据score的范围获取元素列表。
常用命令列表

跳跃列表 zset内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较复杂。这一块的内容深度读者要有心理准备。
因为zset要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的链表结构。

我们需要这个链表按照score值进行排序。这意味着当有新元素需要插入时,需要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,那该怎么办?
想想一个创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安排。公司规模进一步扩展,需要再增加一个层级——部门,每个部门会从组长列表中推选出一个代表来作为部长。部长们之间还会有自己的高层会议安排。
跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构
「跳跃列表」之所以「跳跃」,是因为内部的元素可能「身兼数职」,比如上图中间的这个元素,同时处于L0、L1和L2层,可以快速在不同层次之间进行「跳跃」。
定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合适的位置,将新元素插进去。你也许会问那新插入的元素如何才有机会「身兼数职」呢?
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层,首先L0层肯定是100%了,L1层只有50%的概率,L2层只有25%的概率,L3层只有12.5%的概率,一直随机到最顶层L31层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
BitMaps(位图)
BitMaps不是一个真实的数据结构。而是String类型上的一组面向bit操作的集合。由于strings是二进制安全的blob,并且它们的最大长度是512m,所以bitmaps能最大设置2^32个不同的bit。
bit操作被分为两组:
-
恒定时间的单个bit操作,例如把某个bit设置为0或者1。或者获取某bit的值。
-
对一组bit的操作。例如给定范围内bit统计(例如人口统计)。
Bitmaps的最大优点就是存储信息时可以节省大量的空间。例如在一个系统中,不同的用户被一个增长的用户ID表示。40亿(2^32=4*1024*1024*1024≈40亿)用户只需要512M内存就能记住某种信息,例如用户是否登录过。
Bits设置和获取通过SETBIT 和GETBIT 命令,用法如下:
SETBIT key offset value
GETBIT key offset使用实例:
127.0.0.1:6380> setbit dupcheck 10 1
(integer) 0
127.0.0.1:6380> getbit dupcheck 10
(integer) 1SETBIT命令第一个参数是位编号,第二个参数是这个位的值,只能是0或者1。如果bit地址超过当前string长度,会自动增大string。
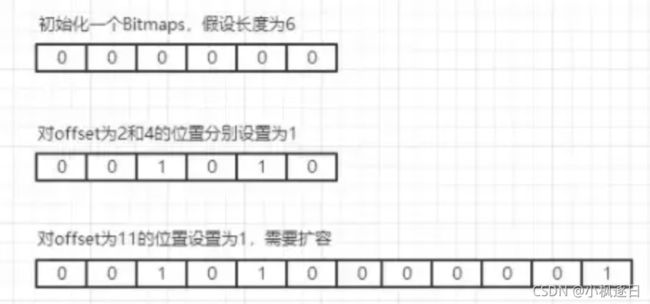
Bitmaps示意图
GETBIT命令指示返回指定位置bit的值。超过范围(寻址地址在目标key的string长度以外的位)的GETBIT总是返回0。三个操作bits组的命令如下:
-
BITOP 执行两个不同string的位操作.,包括AND,OR,XOR和NOT.
-
BITCOUNT 统计位的值为1的数量。
-
BITPOS 寻址第一个为0或者1的bit的位置(寻址第一个为1的bit的位置:bitpos dupcheck 1; 寻址第一个为0的bit的位置:bitpos dupcheck 0).
bitmaps一般的使用场景:
-
各种实时分析.
-
存储与对象ID关联的节省空间并且高性能的布尔信息.
例如,想象一下你想知道访问你的网站的用户的最长连续时间。你开始计算从0开始的天数,就是你的网站公开的那天,每次用户访问网站时通过SETBIT命令设置bit为1,可以简单的用当前时间减去初始时间并除以3600*24(结果就是你的网站公开的第几天)当做这个bit的位置。
这种方法对于每个用户,都有存储每天的访问信息的一个很小的string字符串。通过BITCOUN就能轻易统计某个用户历史访问网站的天数。另外通过调用BITPOS命令,或者客户端获取并分析这个bitmap,就能计算出最长停留时间。
这块经常会变相去面试,BloomFilter ,这个后面单独去讲,因为平常大家可能只知道BloomFilter, 其他它是一个系列,应用在不同的场景。
HyperLogLogs
HyperLogLog是用于计算唯一事物的概率数据结构(从技术上讲,这被称为估计集合的基数)。如果统计唯一项,项目越多,需要的内存就越多。因为需要记住过去已经看过的项,从而避免多次统计这些项。
然而,有一组算法可以交换内存以获得精确度:在redis的实现中,您使用标准错误小于1%的估计度量结束。这个算法的神奇在于不再需要与需要统计的项相对应的内存,取而代之,使用的内存一直恒定不变。最坏的情况下只需要12k,就可以计算接近2^64个不同元素的基数。或者如果您的HyperLogLog(我们从现在开始简称它为HLL)已经看到的元素非常少,则需要的内存要要少得多。
在redis中HLL是一个不同的数据结构,它被编码成Redis字符串。因此可以通过调用GET命令序列化一个HLL,也可以通过调用SET命令将其反序列化到redis服务器。
HLL的API类似使用SETS数据结构做相同的任务,SETS结构中,通过SADD命令把每一个观察的元素添加到一个SET集合,用SCARD命令检查SET集合中元素的数量,集合里的元素都是唯一的,已经存在的元素不会被重复添加。
而使用HLL时并不是真正添加项到HLL中(这一点和SETS结构差异很大),因为HLL的数据结构只包含一个不包含实际元素的状态,API是一样的:
-
PFADD命令用于添加一个新元素到统计中。
-
PFCOUNT命令用于获取到目前为止通过PFADD命令添加的唯一元素个数近似值。
-
PFMERGE命令执行多个HLL之间的联合操作。
127.0.0.1:6380> PFADD hll a b c d d c
(integer) 1
127.0.0.1:6380> PFCOUNT hll
(integer) 4
127.0.0.1:6380> PFADD hll e
(integer) 1
127.0.0.1:6380> PFCOUNT hll
(integer) 5
PFMERGE命令说明:bashbash
PFMERGE destkey sourcekey [sourcekey ...]
Merge N different HyperLogLogs into a single one.
用法(把hll1和hll2合并到hlls中):bashbash
127.0.0.1:6380> PFADD hll1 1 2 3
(integer) 1
127.0.0.1:6380> PFADD hll2 3 4 5
(integer) 1
127.0.0.1:6380> PFMERGE hlls hll1 hll2
OK
127.0.0.1:6380> PFCOUNT hlls
HLL数据结构的一个使用场景就是计算用户每天在搜索框中执行的唯一查询,即搜索页面UV统计。而Bitmaps则用于判断某个用户是否访问过搜索页面。这是它们用法的不同。
这块的面试点也是主要会考察实际应用,如果你知道基本知识,就简单回单,如果没有实际应用过,只是看了网上人家说怎么用的,千万不要去和面试官聊,不然很容易暴露了。
GEO
Redis的GEO特性在 Redis3.2版本中推出,这个功能可以将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作。GEO相关命令只有6个:
-
GEOADD:GEOADD key longitude latitude member [longitude latitude member …],将指定的地理空间位置(纬度、经度、名称)添加到指定的key中。例如:
GEOADD city 113.501389 22.405556 shenzhen;
经纬度具体的限制,由EPSG:900913/EPSG:3785/OSGEO:41001规定如下:
有效的经度从-180度到180度。
有效的纬度从-85.05112878度到85.05112878度。
当坐标位置超出上述指定范围时,该命令将会返回一个错误。
-
GEOHASH:GEOHASH key member [member …],返回一个或多个位置元素的标准Geohash值,它可以在http://geohash.org/使用。查询例子:
http://geohash.org/sqdtr74hyu0.。 -
GEOPOS:GEOPOS key member [member …],从key里返回所有给定位置元素的位置(经度和纬度)。
-
GEODIST:GEODIST key member1 member2 [unit],返回两个给定位置之间的距离。GEODIST命令在计算距离时会假设地球为完美的球形。在极限情况下,这一假设最大会造成0.5%的误差。
指定单位的参数unit必须是以下单位的其中一个:
m 表示单位为米(默认)。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
-
GEORADIUS:GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD][WITHDIST] [WITHHASH][COUNT count],以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。这个命令可以查询某城市的周边城市群。
-
GEORADIUSBYMEMBER:GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD][WITHDIST] [WITHHASH][COUNT count],这个命令和GEORADIUS命令一样,都可以找出位于指定范围内的元素,但是GEORADIUSBYMEMBER的中心点是由给定的位置元素决定的,而不是像 GEORADIUS那样,使用输入的经度和纬度来决定中心点。
指定成员的位置被用作查询的中心。
GEO的6个命令用法示例如下:
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEOHASH Sicily Palermo Catania
1) "sqc8b49rny0"
2) "sqdtr74hyu0"
redis> GEOPOS Sicily Palermo Catania NonExisting
1) 1) "13.361389338970184"
2) "38.115556395496299"
2) 1) "15.087267458438873"
2) "37.50266842333162"
3) (nil)
redis> GEODIST Sicily Palermo Catania
"166274.15156960039"
redis> GEORADIUS Sicily 15 37 100 km
1) "Catania"
redis> GEORADIUS Sicily 15 37 200 km
1) "Palermo"
2) "Catania"
redis> GEORADIUSBYMEMBER Sicily Agrigento 100 km
1) "Agrigento"
2) "Palermo"这块的经典面试题 附近的人
关注下我的公众号吧,无偿指导面试,只为开源精神