hadoop系列二 ——HDFS概念
hdfs简述
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
HDFS(Hadoop Distributed File System),作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
重点概念
文件切块,副本存放,元数据
hdfs整体运行机制
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs特点
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
HDFS架构
HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
HDFS客户端:就是客户端。
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
NameNode:即Master,是整个文件系统的管理节点。他维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
1、负责客户端请求(读写数据 请求 )的响应
2、维护目录树结构( 元数据的管理: 查询,修改 )
3、配置和应用副本存放策略
4、管理集群数据块负载均衡问题
补充:
元数据:
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
fstime:保存最近一次checkpoint的时间。
namenode内存中存储的是=fsimage+edits。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
提供真实文件数据的存储服务。
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间;
Replication:多复本。默认是三个。
1、存储实际的数据块。
2、执行数据块的读/写操作。
补充:文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
dfs.block.size
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
默认在安装在NameNode节点上,但这样…不安全
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
hdfs总体分析
通过上面的描述我们知道,hdfs很多特点:
保存多个副本,且提供容错机制,副本丢失或宕机自动恢复(默认存3份)。
运行在廉价的机器上
适合大数据的处理。HDFS默认会将文件分割成block,。
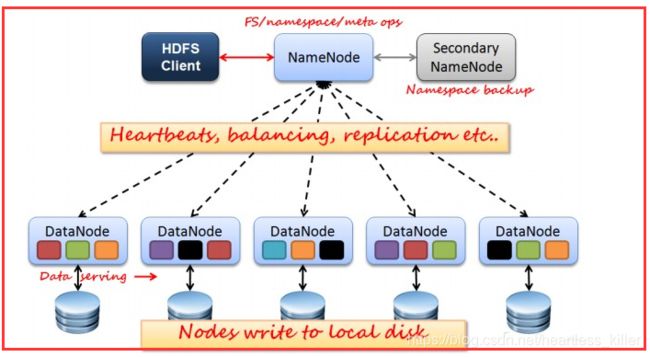 如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
HDFS的局限性
1)低延时数据访问。在用户交互性的应用中,应用需要在ms或者几个s的时间内得到响应。由于HDFS为高吞吐率做了设计,也因此牺牲了快速响应。对于低延时的应用,可以考虑使用HBase或者Cassandra。
2)大量的小文件。标准的HDFS数据块的大小是64M,然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。存储小文件并不会浪费实际的存储空间,但是无疑会增加了在NameNode上的元数据,大量的小文件会影响整个集群的性能。
前面我们知道,Btrfs为小文件做了优化-inline file,对于小文件有很好的空间优化和访问时间优化。
3)多用户写入,修改文件。HDFS的文件只能有一个写入者,而且写操作只能在文件结尾以追加的方式进行。它不支持多个写入者,也不支持在文件写入后,对文件的任意位置的修改。但是在大数据领域,分析的是已经存在的数据,这些数据一旦产生就不会修改,因此,HDFS的这些特性和设计局限也就很容易理解了。HDFS为大数据领域的数据分析,提供了非常重要而且十分基础的文件存储功能。
HDFS保证可靠性的措施
1)冗余备份
每个文件存储成一系列数据块(Block)。为了容错,文件的所有数据块都会有副本(副本数量即复制因子,课配置)(dfs.replication)
2)副本存放
采用机架感知(Rak-aware)的策略来改进数据的可靠性、高可用和网络带宽的利用率
3)心跳检测
NameNode周期性地从集群中的每一个DataNode接受心跳包和块报告,收到心跳包说明该DataNode工作正常
4)安全模式
系统启动时,NameNode会进入一个安全模式。此时不会出现数据块的写操作。
5)数据完整性检测
HDFS客户端软件实现了对HDFS文件内容的校验和(Checksum)检查(dfs.bytes-per-checksum)
namenode元数据工作机制
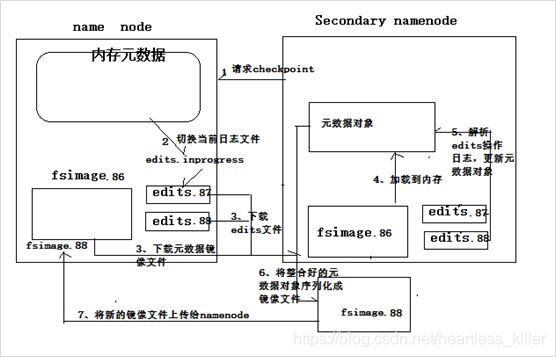
namenode部分
1.namenode的实时的完整的元数据存储在内存中;
2.namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件,fsimage:元数据镜像文件(文件系统的目录树。);
3.namenode会把引起元数据变化的客户端操作记录在edits日志文件中,并且存入磁盘;
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合)
整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给Secondary namenode部分
1.secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志
2然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合)
3整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传回给namenode,(fsimage存在硬盘)。
上述过程叫做:checkpoint操作
每隔一段时间,会由 secondary namenode 将 namenode 上积累的所有 edits 和一个最新的 fsimage 下载到本地,并加载到内存进行 merge(这个过程称为 checkpoint) CheckPoint 详细过程图解:

提示:secondary namenode每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗?
第一次checkpoint需要下载,以后就不用下载了,因为自己的机器上就已经有了。
HDFS的写操作

1、客户端发起请求:hadoop fs -put hadoop.tar.gz /
客户端怎么知道请求发给那个节点的哪个进程?
因为客户端会提供一些工具来解析出来你所指定的HDFS集群的主节点是谁,以及端口号等信息,主要是通过URI来确定,
url:hdfs://hadoop1:9000
当前请求会包含一个非常重要的信息: 上传的数据的总大小
2、namenode会响应客户端的这个请求
namenode的职责:
1 管理元数据(抽象目录树结构)
用户上传的那个文件在对应的目录如果存在。那么HDFS集群应该作何处理,不会处理
用户上传的那个文件要存储的目录不存在的话,如果不存在不会创建
2、响应请求
真正的操作:做一系列的校验,
1、校验客户端的请求是否合理
2、校验客户端是否有权限进行上传
3、如果namenode返回给客户端的结果是 通过, 那就是允许上传
namenode会给客户端返回对应的所有的数据块的多个副本的存放节点列表,即每个block的存放位置,如:
file1_blk1 hadoop02,hadoop03,hadoop04
file1_blk2 hadoop03,hadoop04,hadoop05
4、客户端在获取到了namenode返回回来的所有数据块的多个副本的存放地的数据之后,就可以按照顺序逐一进行数据块的上传操作
5、对要上传的数据块进行逻辑切片
切片分成两个阶段:
1、规划怎么切
2、真正的切
物理切片: 1 和 2
逻辑切片: 1
file1_blk1 : file1:0:128
file1_blk2 : file1:128:256
逻辑切片只是规划了怎么切

6、开始上传第一个数据块
7、客户端会做一系列准备操作
1、依次发送请求去连接对应的datnaode
pipline : client - node1 - node2 - node3
按照一个个的数据包的形式进行发送的。
每次传输完一个数据包,每个副本节点都会进行校验,依次原路给客户端
2、在客户端会启动一个服务:
用户就是用来等到将来要在这个pipline数据管道上进行传输的数据包的校验信息
客户端就能知道当前从clinet到写node1,2,3三个节点上去的数据是否都写入正确和成功
8、clinet会正式的把这个快中的所有packet都写入到对应的副本节点
1、block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,2.x版本默认是128M;注:这个参数由客户端配置决定;如:System.out.println(conf.get(“dfs.blocksize”));//结果是134217728
2、packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
如:System.out.println(conf.get(“dfs.write.packet.size”));//结果是65536
3、chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
如:System.out.println(conf.get(“io.bytes.per.checksum”));//结果是512
9、clinet进行校验,如果校验通过,表示该数据块写入成功
10、重复7 8 9 三个操作,来继续上传其他的数据块
11、客户端在意识到所有的数据块都写入成功之后,会给namenode发送一个反馈,就是告诉namenode当前客户端上传的数据已经成功。
HDFS的读操作

1客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream。
2、通过RPC 远程调用NameNode ,获得NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置( 主要是各DataNode的地址) 。
3、获得输入流之后,客户端调用read 方法读取数据。选择最近的DataNode 建立连接并读取数据。
4、如果客户端和其中一个DataNode 位于同一机器(比如MapReduce 过程中的mapper 和reducer),那么就会直接从本地读取数据。
5、到达数据块末端,关闭与这个DataNode 的连接,然后重新查找下一个数据块。
6、不断执行第2 - 5 步直到数据全部读完。
7、客户端调用close ,关闭输入流DF S InputStream。