Characterizing, exploiting, and detecting DMA code injection vulnerabilities,Eurosys2021
Characterizing, exploiting, and detecting DMA code injection vulnerabilities in the presence of an IOMMU,Eurosys2021
描述、利用和检测IOMMU存在的DMA代码注入漏洞
Abstract摘要
Direct memory access (DMA) renders a system vulnerable to DMA attacks, in which I/O devices access memory regions not intended for their use. Hardware input–output memory management units (IOMMU) can be used to provide protection. However, an IOMMU cannot prevent all DMA attacks because it only restricts DMA at page-level granularity, leading to sub-page vulnerabilities.
直接内存访问(DMA)使系统容易受到DMA攻击,在DMA攻击中,I/O设备访问的内存区域不是为它们所用的。硬件输入输出内存管理单元(IOMMU)可以用来提供保护。但是,IOMMU不能阻止所有的DMA攻击,因为它只在页级粒度上限制DMA,从而导致子页漏洞。
Current DMA attacks rely on simple situations in which write access to a kernel pointer is obtained due to sub-page vulnerabilities and all other attack ingredients are available and reside on the same page. We show that DMA vulnerabilities are a deep-rooted issue and it is often the kernel design that enables complex and multistage DMA attacks. This work presents a structured top-down approach to characterize, exploit, and detect them.
当前的DMA攻击依赖于一些简单的情况,即由于子页漏洞而获得对内核指针的写访问,并且所有其他攻击成分都可用并驻留在同一页上。我们表明,DMA漏洞是一个根深蒂固的问题,通常是内核设计导致了复杂的多阶段DMA攻击。本文提出了一种结构化的自顶向下方法来描述、利用和检测它们。
To this end, we first categorize sub-page vulnerabilities into four types, providing insight into the structure of DMA vulnerabilities. We then identify a set of three vulnerability attributes that are sufficient to execute code injection attacks. We built analysis tools that detect these sub-page vulnerabilities and analyze the Linux kernel. We found that 72% of the device drivers expose callback pointers, which may be overwritten by a device to hijack the kernel control flow.
为此,我们首先将子页面漏洞分为四种类型,以便深入了解DMA漏洞的结构。然后,我们确定了一组三个漏洞属性,它们足以执行代码注入攻击。我们构建了检测这些子页面漏洞并分析Linux内核的分析工具。我们发现72%的设备驱动程序会暴露回调指针,设备可能会覆盖这些指针来劫持内核控制流。
Aided by our tools’ output, we demonstrate novel code injection attacks on the Linux kernel; we refer to these as compound attacks. All previously reported attacks are singlestep, with the vulnerability attributes present in a single page. In compound attacks, the vulnerability attributes are initially incomplete. However, we demonstrate that they can be obtained by carefully exploiting standard OS behavior.
借助我们的工具输出,我们演示了针对Linux内核的新型代码注入攻击;我们称之为复合攻击。以前报告的所有攻击都是单步攻击,漏洞属性显示在单个页面中。在复合攻击中,脆弱性属性最初是不完整的。然而,我们证明了它们可以通过仔细地利用标准操作系统行为来获得。
1 Introduction1介绍
Direct Memory Access (DMA) is a technology that allows input-output (I/O) devices to access memory without CPU involvement, thereby improving system performance. DMAcapable devices include internal devices, such as GPUs, Network Interface Cards (NICs), storage devices (e.g., NVMe), and other peripheral devices, including external devices such as FireWire and Thunderbolt.1 However, in its basic form, DMA makes the system vulnerable to DMA attacks. These are cases where malicious DMA-capable devices, such as compromised firmware [7, 25], access sensitive memory regions not intended for their use.
直接内存访问(DMA)是一种允许输入-输出(I/O)设备在不涉及CPU的情况下访问内存的技术,从而提高系统性能。DMAcapable设备包括内部设备,如gpu、网络接口卡(nic)、存储设备(如NVMe)和其他外围设备,包括外部设备,如火线(FireWire)和thunderbolt。然而,在其基本形式中,DMA使系统容易受到DMA攻击。在这种情况下,具有dma能力的恶意设备(如受威胁的固件[7,25])访问不适合它们使用的敏感内存区域。
Numerous DMA exploits are known [6, 21, 45], ranging from stealing and manipulating sensitive data to taking over the victim machine. Widespread attacks include: opening a locked computer [42, 64], executing arbitrary code on the victim machine [5, 24, 45, 67], stealing sensitive data items such as passwords [9, 13, 40, 63], and extracting a full memory dump of a victim machine [26, 42, 64, 65]. These threats are supposed to be mitigated by the Input-Output Memory Management Unit (IOMMU), which adds a layer of virtual memory to devices. The IOMMU brokers all I/O requests, translating their target I/O virtual addresses (IOVA) to physical addresses. In the process, the IOMMU provides address space isolation, allowing a device to access only permitted pages and rendering all other memory inaccessible.
[45] Thunderclap: Exploring vulnerabilities in operating system iommu protection via dma from untrustworthy peripherals. In NDSS, 2019.
已知有许多DMA漏洞[6,21,45],从窃取和操纵敏感数据到接管受害机器。广泛的攻击包括:打开被锁定的计算机[42,64],在受害机器上执行任意代码[5,24,45,67],窃取敏感数据项,如密码[9,13,40,63],以及提取受害机器的全内存转储[26,42,64,65]。输入-输出内存管理单元(IOMMU)可以缓解这些威胁,它为设备添加了一层虚拟内存。IOMMU代理所有的I/O请求,将它们的目标I/O虚拟地址(IOVA)转换为物理地址。在此过程中,IOMMU提供了地址空间隔离,允许设备只访问允许的页面,并呈现所有其他内存不可访问。
Unlike processes that operate at page granularity, I/O buffers can be significantly smaller than a page. I/O buffers and other kernel buffers can co-reside on the same physical pages, inadvertently exposing these kernel buffers to the device. For this reason, known as the sub-page vulnerability [45, 47], the IOMMU cannot fully protect the kernel from unprivileged access. Consequently, sub-page vulnerabilities were the basis for several recent DMA exploits [7, 8, 38, 45]. Nevertheless, these previously reported vulnerabilities have an ad-hoc nature rather than a structured top-down approach.
与以页面粒度操作的进程不同,I/O缓冲区可以比页面小得多。I/O缓冲区和其他内核缓冲区可以共存于相同的物理页面上,无意中将这些内核缓冲区暴露给设备。由于这个原因,称为子页漏洞[44,47],IOMMU不能完全保护内核免受非特权访问。因此,子页面漏洞是最近几次DMA攻击的基础[7,8,38,45]。然而,以前报告的这些漏洞具有特别的性质,而不是结构化的自顶向下方法。
[44] Moshe Malka, Nadav Amit, and Dan Tsafrir. Efficient intra-operating system protection against harmful dmas. In 13th {USENIX} Conference on File and Storage Technologies ({FAST} 15), pages 29–44, 2015.
[47] Alex Markuze, Adam Morrison, and Dan Tsafrir. True IOMMU protection from DMA attacks: When copy is faster than zero copy. In
ASPLOS, pages 249–262, 2016.
1Currently, the Linux kernel (version 5.0) has as many as 700 such device drivers, of which one third are network device drivers.
目前,Linux内核(5.0版)有多达700个这样的设备驱动程序,其中三分之一是网络设备驱动程序。
Accordingly, we conducted a systematic study of sub-page vulnerabilities. To provide insight into the structure of DMA vulnerabilities, we first break down sub-page vulnerabilities into four types (Section 3.2):
因此,我们对子页面漏洞进行了系统的研究。为了深入了解DMA漏洞的结构,我们首先将子页面漏洞分解为四种类型(第3.2节):
• Exposed driver metadata • Exposed OS metadata • Mapped by multiple IOVA due to multiple co-located buffers • Randomly co-located
•暴露的驱动元数据•暴露的操作系统元数据•由于多个共处的缓冲区被多个IOVA映射•随机共置
Next, we identify the ingredients that make it possible for a malicious device to exploit these four types of sub-page vulnerabilities and execute a viable DMA attack. Focusing on code injection attacks, we introduce (Section 3.3) a set of three vulnerability attributes that can be used to execute such attacks:
接下来,我们将确定使恶意设备能够利用这四种类型的子页面漏洞并执行可行的DMA攻击的因素。针对代码注入攻击,我们将介绍(第3.3节)一组可用于执行此类攻击的漏洞属性:
• A kernel virtual address (KVA) of a buffer filled with malicious executable code (i.e., malicious buffer).
•一个内核虚拟地址(KVA)的缓冲区充满恶意可执行代码(即恶意缓冲区)。
• Write access to a function callback pointer, exposed in a data structure via one of the four sub-page vulnerability types.
•对函数回调指针的写入访问,通过四个子页面漏洞类型之一暴露在数据结构中。
• Existence of a time window such that the device can modify the callback pointer during that time window; the CPU will subsequently jump to the pointed code before the pointer gets overwritten, if it is ever overwritten.
•存在一个时间窗口,这样设备可以在该时间窗口期间修改回调指针;如果指针被覆盖,CPU将在指针被覆盖之前跳转到指定的代码。
With the characterization of the different sub-page vulnerabilities and the vulnerability attributes, we were able to build analysis tools that can detect potentially hazardous sub-page vulnerabilities:
通过描述不同的子页面漏洞和漏洞属性,我们能够构建分析工具,可以检测潜在的危险子页面漏洞:
• We built a static code analysis tool that performs a SubPage Analysis for DMA Exposure (SPADE). SPADE scans for potentially exposed callback pointers on DMAmapped pages. We used SPADE on Linux kernel 5.0 and found that as many as 72% of device drivers are potentially vulnerable to code injection attacks (Section 4.1).
•我们构建了一个静态代码分析工具,用于执行DMA暴露(SPADE)的子页面分析。SPADE扫描dmamap页面上可能暴露的回调指针。我们在Linux内核5.0上使用了SPADE,发现多达72%的设备驱动程序可能容易受到代码注入攻击(第4.1节)。
• Some sub-page vulnerabilities can only manifest dynamically at run-time, potentially exposing callback pointers and/or kernel addresses. Static analysis may not reveal vulnerabilities where a memory buffer is exposed randomly. For example, a random exposure can occur when a memory buffer is co-located on the same page as a mapped I/O buffer. Accordingly, we developed a run-time analysis tool that reports such vulnerabilities and demonstrate its use. Termed DMA-KernelAddress-SANitizer (D-KASAN), this tool reports all cases where a kernel buffer is exposed, inadvertently or otherwise (Section 4.2).
•一些子页面漏洞只能在运行时动态显示,可能会暴露回调指针和/或内核地址。静态分析可能不会揭示随机暴露内存缓冲区的漏洞。例如,当内存缓冲区与映射的I/O缓冲区位于同一页面时,可能会发生随机暴露。因此,我们开发了一个运行时分析工具,报告此类漏洞并演示其使用。这个工具被称为DMA-KernelAddress-SANitizer (D-KASAN),它报告了所有内核缓冲区被意外或其他情况暴露的情况(第4.2节)。
We use our tools to find and demonstrate attacks on the Linux kernel. We focus on compound attacks, cases where a detected sub-page vulnerability alone is insufficient to execute a code injection attack since at least one of the three vulnerability attributes is initially missing, but can be attained via compound steps.
我们使用我们的工具来发现并演示对Linux内核的攻击。我们关注复合攻击,在这种情况下,检测到的子页面漏洞单独不足以执行代码注入攻击,因为三个漏洞属性中至少有一个最初缺失,但可以通过复合步骤实现。
We observe that unlike compound attacks, previous work has explored single-step attacks, i.e., attacks in which the three vulnerability attributes are trivially provided. Namely, a mapped I/O buffer resides on a mapped page which, due to sub-page vulnerability, also exposes a callback pointer and a kernel virtual address, and the timing is such that the CPU will not overwrite the modifications.
我们注意到,与复合攻击不同,以前的工作探索了单步攻击,即简单地提供了三个漏洞属性的攻击。也就是说,一个映射I/O缓冲区驻留在一个映射页上,由于子页的漏洞,这个映射页也暴露了一个回调指针和一个内核虚拟地址,而且这个时间是这样的,CPU不会覆盖修改。
Analysis of such single-step attacks, that can typically be blocked with localized fixes, may lead to a dangerous misconception. In particular, one may assume that buggy device drivers or poor but isolated design choices are to blame for DMA vulnerabilities [43, 44]. However, by introducing compound attacks, we demonstrate that it is often the kernel itself that supplements the missing pieces, showing that this is a deep-rooted issue rather than a collection of disjoint incidents. We identify multiple kernel APIs and data structure designs that facilitate the acquisition of the vulnerability attributes by a malicious device.
对这种单步骤攻击的分析可能会导致一个危险的误解,这种攻击通常可以被本地化的修复程序阻止。特别是,人们可能认为有缺陷的设备驱动程序或糟糕但孤立的设计选择是DMA漏洞的原因[43,44]。然而,通过引入复合攻击,我们证明了通常是内核本身补充了缺失的部分,这表明这是一个根深蒂固的问题,而不是不相交事件的集合。我们识别了多个内核api和数据结构设计,这些设计有助于恶意设备获取漏洞属性。
To summarize, we make the following contributions:
综上所述,我们做出了以下贡献:
• Provide a categorization of the four sub-page vulnerability types.
•提供四个子页面漏洞类型的分类。
• Introduce a set of three vulnerability attributes that are sufficient to execute code injection attacks.
•引入三个漏洞属性,这些属性足以执行代码注入攻击。
• Develop a static code analysis tool (SPADE) to flag code paths that may expose callback pointers.
•开发一个静态代码分析工具(SPADE)来标记可能暴露回调指针的代码路径。
• Develop a run-time tool (D-KASAN) to identify subpage vulnerabilities at run-time, including vulnerabilities caused by random exposure.
•开发一个运行时工具(D-KASAN)来识别运行时的子页面漏洞,包括随机暴露造成的漏洞。
• Demonstrate novel DMA attacks on the Linux kernel, termed compound attacks.
•演示对Linux内核的DMA攻击,称为复合攻击。
• Make our tools publicly available [46, 48].
•公开我们的工具[46,48]。
2 Background 背景
In this section, we provide background on DMA-related attacks. First, we describe classic DMA attacks and the IOMMU protection against them. Then, we discuss well-established protection practices to prevent privilege escalation (i.e., code injection) attacks and methods for their circumvention.
在本节中,我们将提供与dma相关的攻击的背景知识。首先,我们描述了典型的DMA攻击和针对它们的IOMMU保护。然后,我们将讨论防止特权升级(即代码注入)攻击的成熟保护实践和规避这些攻击的方法。
2.1 DMA Attacks
2.1 DMA攻击
DMA allows I/O devices direct access to memory [57] without CPU involvement. While DMA is essential for fast I/O, it also provides ample opportunity for unmonitored and malicious activity by DMA-capable devices, resulting in DMA attacks.
DMA允许I/O设备在没有CPU参与的情况下直接访问内存[57]。虽然DMA对于快速I/O至关重要,但它也为具有DMA能力的设备提供了大量不受监控和恶意活动的机会,从而导致DMA攻击。
An attacker can access sensitive data, overwrite the OS code and data structures, and even gain full control of the victim system. DMA attacks can be carried out using an external or internal DMA-capable device.
攻击者可以访问敏感数据,覆盖操作系统代码和数据结构,甚至完全控制受害者的系统。DMA攻击可以使用外部或内部具有DMA能力的设备进行。
Table 1. Linux kernel memory layout
表1。Linux内核内存布局

Accessible expansion ports, e.g., FireWire or Thunderbolt, allow external devices to initiate DMA transactions merely by connecting a programmable accessory [21, 42, 45, 65]. Exploiting internal devices is more challenging, but enables persistent and stealthy attacks.
可访问的扩展端口,例如FireWire或Thunderbolt,允许外部设备仅仅通过连接可编程附件来启动DMA交易[21,42,45,65]。利用内部设备更具挑战性,但可以实现持续和隐形的攻击。
Many options are available to gain control of an internal device. For example, a resourceful attacker can exploit firmware bugs [63]. These can be well-known exploits, since end-users are often slow in deploying firmware updates [22]; they may even be newly discovered zero-day vulnerabilities [8]. Alternatively, certain attackers may be able to replace the device firmware altogether with a malicious one [55, 71]. It is also possible to manufacture devices that appear to be legitimate but are, in fact, malicious at the circuitry level [69].
有许多选项可用于控制内部设备。例如,一个足智多谋的攻击者可以利用固件漏洞[63]。这些都是众所周知的漏洞,因为终端用户部署固件更新[22]的速度通常很慢;它们甚至可能是新发现的零日漏洞[8]。或者,某些攻击者可能会使用恶意的固件来替换设备固件[55,71]。也有可能制造看似合法但实际上在电路级别上是恶意的设备[69]。
Once an attacker gains control over a DMA device connected to a victim machine, various attacks are possible. These attacks can range from keyloggers [40, 63] to full control over commodity OS and hypervisor, including Windows [5, 45], Linux, OSX [24, 45], Android [8], and Xen [67]. Several software tools exist for perpetrating DMA attacks, with some of them being open source. Tools such as Volatility [65], Inception [42], GoldFish [26], and FinFireWire [64] can extract target machine memory and unlock victim machines by patching the OS code. These tools are reportedly used by government agencies, such as the NSA.
一旦攻击者获得了对连接到受害机器的DMA设备的控制,各种攻击就可能发生。这些攻击可以从键盘记录程序[40,63]到完全控制普通操作系统和hypervisor,包括Windows[5,45]、Linux、OSX[24,45]、Android[8]和Xen[67]。有一些软件工具可以进行DMA攻击,其中一些是开源的。像Volatility[65]、Inception[42]、金鱼[26]和FinFireWire[64]这样的工具可以提取目标机器内存并通过修补操作系统代码来解锁受害机器。据报道,这些工具被美国国家安全局(NSA)等政府机构使用。
2.2 IOMMU
With the lack of software protection against DMA attacks, the common practice is to restrict DMA accesses through hardware protection. The most common mechanism for this purpose is the I/O memory management unit (IOMMU). The IOMMU adds a level of indirection for DMA addresses [54, 63, 66, 70], effectively providing peripheral devices with I/O virtual addresses (IOVA). This way, the device can access only those pages explicitly allowed by the OS. Inspired by the x86 MMU, the IOMMU uses a page table for address translation and an IOTLB for caching recent accesses. The page tables are managed by the OS, and as with the MMU, have a page granularity. The common page size is 4 KB, although there exist larger page sizes, up to GBs.
由于缺乏防止DMA攻击的软件保护,常见的做法是通过硬件保护来限制DMA访问。为此目的最常见的机制是I/O内存管理单元(IOMMU)。IOMMU为DMA地址增加了一个间接级别[54,63,66,70],有效地为外围设备提供了I/O虚拟地址(IOVA)。这样,设备只能访问OS明确允许的页面。受x86 MMU的启发,IOMMU使用页表进行地址转换,使用IOTLB缓存最近的访问。页面表由操作系统管理,并且与MMU一样,具有页面粒度。公共页面大小为4 KB,但也有更大的页面大小,最大可达gb。
The IOMMU page table also holds page access rights for each IOVA. An access right can be either READ, WRITE, or BIDIRECTIONAL. Note that WRITE access does not grant a DMA device READ access, whereas BIDIRECTIONAL access is needed to both read and write from/to the page. It is also important to note that a single physical page can be mapped by multiple IOVAs, each with possibly different access rights.
IOMMU页表还包含每个IOVA的页访问权限。访问权限可以是读、写或双向。注意,写访问不授予DMA设备读访问权,而双向访问需要从/到页面读和写。还需要注意的是,单个物理页可以由多个iova映射,每个iova可能具有不同的访问权限。
IOMMUs were not designed primarily to provide security [19]. Instead, IOMMUs were used to allow devices that did not support vectored I/O, to access contiguous virtual memory that may map non-contiguous physical memory [12, 68]. IOMMUs also enabled legacy devices that only supported a limited address width (32-bit) to access high memory (64-bit). More recently, IOMMUs were used to assign I/O devices directly to virtual machines, while maintaining their isolation properties [1, 32].
IOMMUs的设计主要不是为了提供安全[19]。相反,IOMMUs被用于允许不支持向量I/O的设备访问可能映射非连续物理内存的连续虚拟内存[12,68]。IOMMUs还启用了只支持有限地址宽度(32位)的遗留设备来访问高内存(64位)。最近,IOMMUs被用于将I/O设备直接分配给虚拟机,同时保持它们的隔离属性[1,32]。
2.3 DMA API
Device drivers must use the DMA API to manage the DMA buffers. Drivers a buffer before initiating a DMA to that buffer, thereby passing ownership of the buffer to the device. Drivers the buffer upon DMA completion, thereby regaining ownership of the buffer. The call returns an IOVA. The driver must configure the device to DMA for that specific IOVA; later takes this IOVA as its parameter. There are analogous methods to map and unmap for non-contiguous scatter/gather lists.
设备驱动程序必须使用DMA API来管理DMA缓冲区。驱动程序在对该缓冲区发起DMA之前将其装入缓冲区,从而将缓冲区的所有权传递给该设备。驱动在DMA完成时对缓冲区进行,从而重新获得缓冲区的所有权。调用返回一个IOVA。驱动程序必须为特定的IOVA将设备配置为DMA;稍后将此IOVA作为其参数。对于非连续的散/集列表,也有类似的映射和取消映射方法。
2.4 OS Defenses 防御
Other than DMA attacks, OS developers have to worry about code injection originating from unprivileged users, such as buffer overflow attacks [23, 35]. We discuss the common mechanisms used to mitigate such attacks in the kernel. Subverting these countermeasures is essential to executing a successful DMA attack.
除了DMA攻击,操作系统开发人员还必须担心来自非特权用户的代码注入,例如缓冲区溢出攻击[23,35]。我们将讨论用于减轻内核中此类攻击的常见机制。破坏这些对策对于成功执行DMA攻击至关重要。
NX-BIT. A malicious device can gain write access to a function pointer and consequently gain the ability to inject malicious code. To protect against such threats, modern OSs make use of hardware support, namely the No-eXecute bit, to prevent code execution from data pages. This bit is defined for each page in the MMU’s page tables. Whenever the CPU tries to fetch code from memory, this bit is validated. When set, the CPU raises an exception to the OS instead of executing the code. The NX-bit method is also known as the W ⊕ X (Write ⊕ eXecute) or DEP (Data Execution Prevention). A DMAcapable device rarely has access to kernel text regions. Thus, the NX-bit is effective in preventing simple code injection attacks.
NX-BIT。恶意设备可以获得对函数指针的写访问权,从而获得注入恶意代码的能力。为了防止这种威胁,现代操作系统利用硬件支持,即No-eXecute位,来阻止数据页上的代码执行。这个位是为MMU的页表中的每个页定义的。当CPU尝试从内存中获取代码时,这个位将被验证。当设置时,CPU会向操作系统引发异常,而不是执行代码。nx位方法也被称为W⊕X(写⊕eXecute)或DEP(数据执行预防)。DMAcapable设备很少能够访问内核文本区域。因此,NX-bit可以有效地防止简单的代码注入攻击。
Subverting NX-BIT. Return Oriented Programming (ROP) is a common method used by malware to bypass DEP (i.e., NX-bit) defenses [60]. ROP exploits the fact that the CPU stack pointer may point to any data page. To set up an attack from a data page, the attacker builds a poisoned stack filled with required data and pointers to specific locations in the code section (a.k.a., ROP gadgets). Each gadget is a short piece of code, usually one or two instructions, and a return instruction. When the CPU executes a return instruction, the return address and thus the address of the next instruction to execute is taken from the stack. In the poisoned stack, each return address points to the next gadget, and so on.
颠覆NX-BIT。面向返回编程(ROP)是恶意软件绕过DEP(即NX-bit)防御[60]的常用方法。ROP利用了CPU堆栈指针可以指向任何数据页这一事实。为了从数据页设置攻击,攻击者构建一个有毒的堆栈,其中填充了必需的数据和指向代码部分中特定位置的指针(也称为ROP小工具)。每个小工具是一小段代码,通常是一条或两条指令和一条返回指令。当CPU执行一个返回指令时,返回地址,也就是下一个要执行的指令的地址会从堆栈中取出。在中毒堆栈中,每个返回地址指向下一个gadget,以此类推。
By carefully selecting these gadgets, an attacker can execute any payload. To bootstrap a ROP attack, an attacker must modify the stack pointer register to the address of the poisoned stack. This is often achieved with another DEP circumventing technique, known as Jump Oriented Programming (JOP) [10]. JOP uses, jump instructions instead of return instructions and, thus, does not require a poisoned stack.
通过仔细选择这些小工具,攻击者可以执行任何有效负载。要启动ROP攻击,攻击者必须将堆栈指针寄存器修改为中毒堆栈的地址。这通常是通过另一种绕过DEP的技术来实现的,称为面向跳跃的编程(JOP)[10]。JOP使用跳转指令而不是返回指令,因此不需要有毒堆栈。
KASLR. Address Space Layout Randomization (ASLR) is a common mechanism for mitigating code injection attacks in the context of user-level processes. Systems that support ASLR, randomize the memory layout for each process on every execution. This way, ROP attacks built for a specific layout fail. Similar to ASLR, KASLR [23] randomizes the kernel memory layout.
KASLR。地址空间布局随机化(ASLR)是一种常见的机制,用于在用户级进程的上下文中减少代码注入攻击。支持ASLR的系统在每次执行时为每个进程随机分配内存布局。这样,针对特定布局构建的ROP攻击就会失败。与ASLR类似,KASLR[23]对内核内存布局进行随机化。
Specifically, the Linux kernel has predetermined ranges for its virtual memory layout [36]. This layout defines the location of the kernel text mapping, and the direct mapping of physical memory and the virtual memory, as depicted in Table 1. At each boot, KASLR randomizes the offset of these segments in the corresponding range.
具体来说,Linux内核已经为其虚拟内存布局[36]预定了范围。这个布局定义了内核文本映射的位置,以及物理内存和虚拟内存的直接映射,如表1所示。在每次启动时,KASLR将这些分段在相应范围内的偏移量随机化。
Subverting KASLR. To successfully execute a code injection attack, the attacker must know the memory layout. Specifically, the address of the code section is required for finding ROP gadgets (Section 2.4). Since KASLR randomizes only the base address of the kernel text mapping, text addresses always appear in the kernel text mapping range (Figure 1) and are therefore easy to detect. KASLR kernel text is aligned to 2 MB borders. This is the result of page table restrictions and is unlikely to change. This means that the lowest 21 bits are not modified by the KASLR randomization procedure. Hence, knowing even a single address of a known element is sufficient to deduce the base address and compromise KASLR. Once the base address is known, the attacker can use it to create a ROP stack.
颠覆KASLR。要成功执行代码注入攻击,攻击者必须知道内存布局。具体来说,代码部分的地址是寻找ROP小工具所必需的(第2.4节)。因为KASLR只随机化内核文本映射的基址,所以文本地址总是出现在内核文本映射范围内(图1),因此很容易检测。KASLR内核文本对齐到2 MB的边界。这是页表限制的结果,不太可能改变。这意味着最低的21位不会被KASLR随机化过程修改。因此,即使知道一个已知元素的单个地址也足以推断出基址并危及KASLR。一旦知道了基地地址,攻击者就可以使用它来创建ROP堆栈。

To identify this first pointer, malicious devices can scan the pages mapped for reading, looking for kernel pointers leaked due to sub-page vulnerability. Once such a pointer is identified, all that remains is to infer the offset of the symbol in the binary from the pointer to get the base address.
为了识别第一个指针,恶意设备可以扫描用于读取的映射页,寻找由于子页漏洞而泄漏的内核指针。一旦标识了这样的指针,剩下的就是从指针推断二进制文件中符号的偏移量以获得基址。
In fact, during our investigation, we found that there is a symbol visible to both FireWire and NICs in Linux 5.0, that compromises KASLR. Specifically, as of version 2.6.24, Linux supports network namespaces and every network object, especially sockets, have a pointer to their namespace object. One such global namespace object, , is always defined. By scanning leaked pages during I/O and utilizing the fact that the lower 21 bits of the text region are never modified, we can identify with a high probability. The direct mapping base ( ) and virtual memory map ( ) are also randomized (Figure 1), where each region’s base pointer is randomized with respect to a 1 GB alignment. This means the lower 30 bits are unmodified and can leak both the Page Frame Number (PFN) and the randomized offset. This alignment is also due to page table considerations. That is, the page upper table (PUD) has a 30-bit shift. Once the random offsets PAGE_OFFSET and vmemmap for direct mapping base and virtual memory map are known, it becomes possible to translate between a KVA (kernel virtual addresses within the direct mapping region), its PFN, and its struct page address (virtual memory map region).
事实上,在我们的调查中,我们发现在Linux 5.0中有一个对FireWire和nic都可见的符号,它损害了KASLR。具体来说,从版本2.6.24开始,Linux支持网络名称空间,并且每个网络对象,特别是套接字,都有一个指向它们的名称空间对象的指针。总会定义这样一个全局命名空间对象。通过在I/O期间扫描泄漏的页面,并利用文本区域的低21位从未被修改这一事实,我们可以以很高的概率识别。直接映射基()和虚拟内存映射()也是随机的(图1),其中每个区域的基指针相对于1gb对齐是随机的。这意味着较低的30位是未修改的,可能会泄漏页帧数(PFN)和随机偏移量。这种对齐也是由于页表的考虑。也就是说,页上表(PUD)有30位的移位。一旦已知直接映射基和虚拟内存映射的随机偏移PAGE_OFFSET和vmemmap,就可以在KVA(直接映射区域内的内核虚拟地址)、PFN和它的结构页地址(虚拟内存映射区域)之间进行转换。
3 Categorizing DMA Risks 对DMA风险进行分类
This section organizes and categorizes the risks associated with DMA operations, providing the building blocks for reasoning about code injection attacks. We first present our threat model and then organize the different sub-page vulnerabilities into four categories. Finally, we identify a set of three vulnerability attributes that make it possible for a malicious device to exploit a sub-page vulnerability and execute a viable code injection attack.
本节组织并分类了与DMA操作相关的风险,提供了用于推理代码注入攻击的构建块。我们首先提出我们的威胁模型,然后将不同的子页面漏洞组织成四类。最后,我们确定了一组三个漏洞属性,这些属性使恶意设备能够利用子页面漏洞并执行可行的代码注入攻击。
3.1 Threat Model 威胁模型
By organizing the DMA risks, we reveal that the Linux kernel is vulnerable to various high impact attacks. For example, a full memory dump is possible when an attacker can modify data pointers before they are mapped, causing the driver to map arbitrary kernel addresses. Alternatively, a malicious device can corrupt random memory regions [47], resulting in a denial of service attack (DOS).
通过组织DMA风险,我们揭示了Linux内核容易受到各种高影响攻击。例如,当攻击者可以在数据指针映射之前修改它们,导致驱动程序映射任意内核地址时,就可能发生全内存转储。或者,恶意设备可以破坏随机内存区域[47],导致拒绝服务攻击(DOS)。
The most significant potential consequence of these attacks is privilege escalation via code injection, allowing attackers to execute arbitrary code with kernel privileges. Indeed, this is the focus of our paper. Our attacks are designed with the following assumptions:
这些攻击的最重要的潜在后果是通过代码注入的特权升级,允许攻击者使用内核特权执行任意代码。事实上,这是我们论文的重点。我们的攻击是根据以下假设设计的:
- A malicious DMA-capable device is attached to the system.
- 一个恶意的dma设备被附加到系统上。
- The actual attack is performed solely by the DMAcapable malicious device.
- 实际攻击仅由DMAcapable恶意设备执行。
- Any hardware aside from the specific malicious device is working as expected.
3.除了特定的恶意设备外,任何硬件都按照预期工作。
3.2 Sub-Page Vulnerabilities 子页漏洞
Anytime an I/O buffer smaller than a page is DMA-mapped, all additional information that resides on the same physical page becomes accessible to the device. Any such situation where a memory-region is exposed due to the IOMMU page granularity is called a sub-page vulnerability.
当小于一个页面的I/O缓冲区被dma映射时,驻留在同一物理页面上的所有附加信息都可以被设备访问。由于IOMMU页面粒度而暴露内存区域的任何这种情况都称为子页面漏洞。
We classify the different types of sub-page vulnerabilities into four categories, as illustrated in Figure 1:
我们将不同类型的子页面漏洞分为四类,如图1所示:

Figure 1. DMA sub-page vulnerabilities when the I/O buffer shares a page with other data: (a) I/O buffer metadata; (b) OS metadata; © a page mapped by multiple IOVA; (d) randomly co-located sensitive buffers.
图1所示。当I/O缓冲区与其他数据共享一个页面时,DMA子页面漏洞:(a) I/O缓冲区元数据;(b)操作系统元数据;©由多个IOVA映射的页面;(d)随机共置敏感缓冲器。
(a) The I/O buffer is part of a bigger data structure. This data structure may include function pointers, often caused by poor DMA hygiene in the driver. An isolated driver fix is usually sufficient to repair such vulnerabilities.
I/O缓冲区是一个更大的数据结构的一部分。这个数据结构可能包括函数指针,通常是由于驱动程序的DMA卫生状况不佳造成的。一个独立的驱动程序修复通常足以修复此类漏洞。
(b) The OS (e.g., memory allocator)—rather than the driver— saves metadata such as free-lists, on the same page as the I/O buffer [15]. Manipulating these data structures may also compromise the system [4]. Similar to (a), sensitive metadata is unwittingly shared. However, in this case, it is an OS subsystem that is at fault rather than the device driver.
(b)操作系统(例如内存分配器)-而不是驱动程序-保存元数据,如自由列表,在相同的页面上的I/O缓冲区[15]。操纵这些数据结构也可能危及系统[4]。与(a)类似,敏感元数据在不知情的情况下被共享。然而,在这种情况下,出错的是一个OS子系统,而不是设备驱动程序。
© The same page is mapped multiple times due to colocated device driver buffers, resulting in multiple IOVAs indicating the same page. In this case, unmapping one IOVA will not prevent the device from accessing the page through a different IOVA. The device will retain access to the physical page as long as a single valid IOVA exists. This means that the device can tamper with memory regions that should no longer be accessible. We discuss the practical implications of multiple IOVAs indicating the same page in Section 5.2.
©由于设备驱动程序缓存的位置,同一个页面被映射多次,导致多个IOVAs指示同一个页面。在这种情况下,解除一个IOVA的映射并不会阻止设备通过不同的IOVA访问页面。只要存在一个有效的IOVA,设备就会保留对物理页的访问。这意味着设备可以篡改不应该再被访问的内存区域。我们在第5.2节讨论了多个iova表示同一页的实际含义。
(d) The I/O buffer and a different, dynamically allocated memory buffer may coincidentally share a page. This common situation results in data leakage (e.g., kernel pointers). Currently, the Linux kernel uses the same memory allocation mechanism (e.g., kmalloc) for both I/O buffers and regular kernel buffers. Consequently, I/O buffers often share pages with other, potentially sensitive, kernel buffers. Since IOMMU works at page granularity, the respective I/O devices gain access to these kernel buffers. Such vulnerability is a subclass of (b), as it is caused by an OS subsystem; the main difference is that the exposed data structures are leaked randomly.
(d) I/O缓冲区和一个不同的、动态分配的内存缓冲区可能同时共享一个页面。这种常见的情况会导致数据泄漏(例如,内核指针)。目前,Linux内核对I/O缓冲区和常规内核缓冲区使用相同的内存分配机制(例如kmalloc)。因此,I/O缓冲区经常与其他可能敏感的内核缓冲区共享页面。因为IOMMU是在页面粒度上工作的,所以相应的I/O设备可以访问这些内核缓冲区。这种漏洞是(b)的一个子类,因为它是由OS子系统引起的;主要的区别是公开的数据结构是随机泄漏的。
3.3 Vulnerability Attributes for Code Injection 代码注入漏洞属性
We introduce a schema that allows for a systematic analysis of code injection attacks by DMA-capable devices. For a successful privilege escalation attack (i.e., code injection), a malicious device needs the following set of three vulnerability attributes:
我们引入了一个模式,该模式允许对dma设备的代码注入攻击进行系统分析。对于成功的特权升级攻击(即代码注入),恶意设备需要以下三种漏洞属性:
-
The KVA of a kernel buffer filled with malicious code (e.g., ROP attack). Given that the device is using an IOVA, the attacker needs to obtain the buffer’s KVA, for example, by observing leaked pointers.
-
内核缓冲区中充满恶意代码的KVA(例如,ROP攻击)。假设设备正在使用IOVA,攻击者需要获取缓冲区的KVA,例如,通过观察泄漏的指针。
-
Write access to a function callback pointer, which can alter the CPU control flow and cause it to execute the malicious code. For example, this might be write access to a data structure that holds a function callback pointer at a known offset.2 The location on the page of the callback pointer must be known to the device.
-
对函数回调指针的写访问,可以改变CPU控制流并导致它执行恶意代码。例如,这可能是对数据结构的写访问,该结构在一个已知的偏移量处保存一个函数回调指针设备必须知道回调指针在页面上的位置。
-
A time window exists such that the device can modify the callback pointer during that window and the CPU will subsequently jump to the pointed code; this occurs before the pointer gets overwritten, if it is ever overwritten.
-
存在一个时间窗口,设备可以在该窗口期间修改回调指针,CPU随后将跳转到指定的代码;这发生在指针被覆盖之前,如果它曾经被覆盖。
To further emphasize the significance of these attributes, we present a hypothetical scenario. Assume a NIC has write access to a page containing a received (RX) packet. Due to a sub-page vulnerability and a random allocation coincidence (Figure 1, type (d)), a structure with a callback pointer is write-accessible to a malicious device. Also, the device can create a valid malicious buffer in the aforementioned page. It may seem that the device has a valid attack, whereas it actually lacks the following:
为了进一步强调这些属性的重要性,我们提出一个假设场景。假设网卡对包含接收(RX)数据包的页面具有写访问权限。由于子页面漏洞和随机分配巧合(图1,类型(d)),带有回调指针的结构被恶意设备写可访问。此外,设备可以在上述页面创建一个有效的恶意缓冲区。似乎该设备具有有效的攻击,但实际上它缺乏以下几点:
• Without a valid KVA of the writable page, the device cannot modify the callback function pointer to indicate the malicious buffer.
•没有可写页的有效KVA,设备不能修改回调函数指针来指示恶意缓冲区。
• Although a callback function pointer is available for modifications, the device has no way of knowing that a callback function pointer is available for sabotage nor the correct offset of the callback function pointer.
•虽然回调函数指针可用于修改,但设备无法知道回调函数指针可用于破坏,也无法知道回调函数指针的正确偏移量。
• It is not known whether the modified callback pointer will be executed.
不知道修改后的回调指针是否会被执行。
Under the hypothesized circumstance, and without additional information, a malicious device has no viable attack options. All three attributes are required for a code injection attack. While corrupting the random kernel memory is still a possibility and may even cause a kernel panic [47], it does not achieve the goal of privilege escalation.
在假设的情况下,如果没有额外的信息,恶意设备就没有可行的攻击选项。这三个属性都是代码注入攻击所必需的。虽然破坏随机内核内存仍然是可能的,甚至可能导致内核panic[47],但它并没有实现特权升级的目标。
4 Detecting Sub-Page Vulnerabilities 检测子页面漏洞
We now present the tools we developed to identify the subpage vulnerabilities described in the previous section.
现在,我们将介绍我们开发的用于识别上一节中描述的子页面漏洞的工具。
4.1 Sub-Page Analysis for DMA Exposure
4.1 DMA暴露的子页分析
We devised a static code analysis tool that performs SubPage Analysis for DMA Exposure (SPADE). With well over 1000 function calls (i.e., the set of functions implementing the DMA API) in the Linux kernel, a manual process would be arduous. SPADE performs the following operations to detect the different sub-page vulnerability types (Figure 1) where a callback pointer may be exposed:
我们设计了一个静态代码分析工具,用于对DMA暴露(SPADE)执行子页面分析。由于在Linux内核中有超过1000个函数调用(即实现DMA API的一组函数),手动处理将非常困难。SPADE执行以下操作来检测可能暴露回调指针的不同子页面漏洞类型(图1):
- Type A: Looks for dma_map* functions and traces back the call stack to identify whether the mapped buffer is embedded inside a data structure.
- 类型A:查找dma_map函数并回溯调用堆栈,以确定映射的缓冲区是否嵌入到数据结构中。
- Type B: Looks for kernel APIs that create a data structure inside a mapped buffer (e.g., build_skb).
- 类型B:查找在映射缓冲区中创建数据结构的内核API (例如,build_skb)。
- Type C: Looks for functions that are used for fast allocation by slicing a contiguous memory buffer into segments (e.g., netdev_alloc_skb, napi_alloc_skb). These may result in multiple IOVA mapping the same page. These functions utilize the API, which we discuss in greater detail in Section 5.1.
3.类型C:通过将连续内存缓冲区切片成段(例如netdev_alloc_skb, napi_alloc_skb)来查找用于快速分配的函数。这可能导致多个IOVA映射同一个页面。这些函数利用 API,我们将在第5.1节详细讨论。
4.1.1 High-Level Design Overview.
4.1.1高级设计概述
SPADE operates recursively starting from calls to the dma_map* functions. From this initial set of calls, SPADE identifies the mapped variables and backtracks their declarations and assignments. When a data structure is identified as exposed, SPADE identifies the exposed callback pointers or mapped heap pointers.
SPADE从调用dma_map*函数开始递归操作。从这组初始调用中,SPADE标识映射的变量,并回溯它们的声明和赋值。当数据结构标识为公开时,SPADE标识公开的回调指针或映射的堆指针。
SPADE is implemented in approximately 2000 lines of Perl 5 code. It uses pahole [17] to explore the compiled binaries for the layout of the exposed data structures. Pahole is a tool that uses the DWARF [28] standardized debugging data format to examine data structure layout. To navigate the kernel code, SPADE uses Cscope [37, 39] which is an open source tool for browsing C source code.
用大约2000行Perl 5代码实现了SPADE。它使用pahole[17]来探索已编译的二进制文件,以便对暴露的数据结构进行布局。Pahole是一个使用DWARF[28]标准化调试数据格式来检查数据结构布局的工具。为了浏览内核代码,SPADE使用了Cscope[37,39],这是一个浏览C源代码的开源工具。
SPADE is applicable to any kernel code written in C. We intend to make the SPADE publicly available for the benefit of the research community.
SPADE适用于任何用C编写的内核代码。我们打算公开使用SPADE,使研究界受益。
4.1.2 Output 输出
For each DMA-mapping call, SPADE outputs the line numbers of relevant declarations, function calls, and assignments, allowing human experts to trace back and validate the vulnerability. Figure 2 presents an example of output for a vulnerability found in the NVMe host driver.
对于每个dma映射调用,SPADE输出相关声明、函数调用和赋值的行号,允许人工专家追溯和验证漏洞。
图2给出了NVMe主机驱动程序中发现的漏洞的输出示例。

Figure 2. SPADE output example showing a path in the nvme_fc driver where a callback pointer is exposed with write access.
图2。SPADE输出示例,显示nvme_fc驱动程序中的路径,其中公开了一个带写访问权限的回调指针。
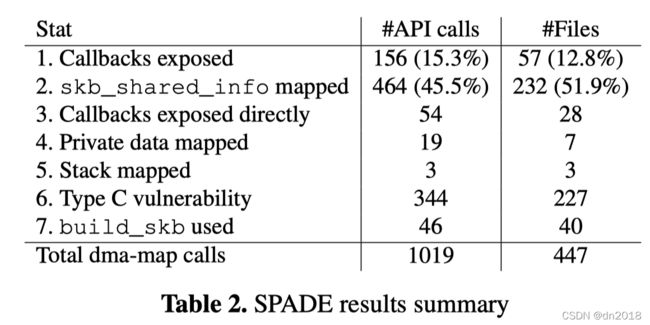
The output starts from the impact evaluation, such as detected exposed callback pointers, and continues with pertinent code lines. Line 7 reveals that a single callback pointer is mapped in the mapped data structure (i.e., fcp_req.done) and line 8 reveals that it is possible to spoof another 931 callback pointers.3 After finding the variable declaration in line 5, and looking at the mapped pointer in line 4, SPADE concludes in line 6 that the entire is exposed to the device. Lines 1 through 3 repeat the same analysis process for the call that exposes the data structure to the device.
输出从影响评估开始,比如检测到的公开回调指针,然后继续输出相关的代码行。第7行显示一个回调指针映射到映射的数据结构中(即,fcp_req.done),第8行显示可以欺骗另一个931回调指针在第5行找到变量声明后,在第4行中查看映射指针, SPADE在第6行中得出结论,整个都暴露给设备。第1行到第3行对向设备公开数据结构的调用重复相同的分析过程。
This example demonstrates the recursive nature of the analysis. SPADE first identifies the suspect function call, finds the mapped pointer’s declaration, and then prints its type. This pattern repeats itself in lines 1 through 3 and 4 through 6 until a vulnerability is discovered. The findings are then displayed: line 7 counts the number of directly exposed callback pointers, and line 8 displays the number of callback pointers that may be potentially spoofed.
这个例子演示了分析的递归性质。SPADE首先识别可疑的函数调用,找到映射指针的声明,然后打印其类型。该模式在第1行到第3行和第4行到第6行中重复,直到发现漏洞。然后显示结果:第7行计算直接公开的回调指针的数量,第8行显示可能被欺骗的回调指针的数量。
4.1.3 Analysis and Results 分析与结果
We used SPADE over Linux kernel 5.0 code, analyzing 1019 dma_map_single calls over 447 files. We present the results in Table 2. We found 156 cases in which device drivers expose callback pointers. Of these, 54 are cases in which the pointers are exposed directly, and the rest are cases in which callback pointers can be spoofed. We found that 13% (line 1 in Fig. 2) of the drivers expose data structures via type (a) vulnerabilities, whereas 60% (lines 2,7 in Fig. 2) expose data structures via type (b) vulnerabilities. Namely, 13% are vulnerable due to driver bugs and 60% of drivers are vulnerable due to OS design choices. In the case of the Linux kernel, the most common source of vulnerability caused by the OS design is struct , which is used ubiquitously in Linux networking. This data structure is always located on the same page as the , and it also contains a callback pointer. We discuss the vulnerabilities related to in Section 5. We found that more than 50% of the dma-map calls either directly map the or use the API (lines 2 and 7 in Table 2), which exposes . The OS provides this data structure layout and API rather than it being an isolated driver bug. Additionally, we found 19 data structures that are exposed via APIs that store private data structures on the same page as vulnerable metadata, e.g., netdev_priv, aead_request_ctx, and scsi_cmd_priv.
我们在Linux内核5.0代码上使用SPADE,分析447个文件上的1019个dma_map_single调用。我们将结果显示在表2中。我们发现有156个设备驱动程序暴露回调指针。其中,54种情况下指针是直接暴露的,其余情况下是回调指针可能被欺骗的。我们发现13%的驱动程序(图2中的第一行)通过类型(a)漏洞暴露了数据结构,而60%的驱动程序(图2中的第2、7行)通过类型(b)漏洞暴露了数据结构。也就是说,13%的驱动程序容易受到漏洞的影响,60%的驱动程序容易受到操作系统设计选择的影响。在Linux内核中,由操作系统设计引起的最常见的漏洞来源是结构,它在Linux网络中广泛使用。这个数据结构总是位于与相同的页面上,并且它还包含一个回调指针。我们将在第5节中讨论与相关的漏洞。我们发现,50%以上的dma-map调用要么直接映射,要么使用 API(表2中的第2行和第7行),后者公开了。操作系统提供了这种数据结构布局和API,而不是一个孤立的驱动程序bug。此外,我们还发现了19种通过api公开的数据结构,这些api将私有数据结构作为易受攻击的元数据存储在同一页面上,例如netdev_priv、aead_request_ctx和scsi_cmd_priv。
In addition to type (a) and (b) vulnerabilities, SPADE also flagged 344 cases where a type © vulnerability is present.
除了(a)和(b)类型漏洞外,SPADE还标记了344个存在©类型漏洞的情况。
3
In this case, spoofing means replacing this pointer to indicate an instance of the structure created by the device, with its own callback pointers.
在这种情况下,欺骗意味着用设备自己的回调指针替换这个指针来指示结构的一个实例。
Our analysis found three instances where the stack pointer is mapped, potentially simplifying the execution of a ROP attack.
我们的分析发现了三个映射堆栈指针的实例,这可能简化了ROP攻击的执行。
In total, we found 742 dma-map calls (i.e., 72.8% of all dma-map calls) with a potential vulnerability, of which 344 also admit a type © vulnerability.
我们总共发现742次dma-map调用(占所有dma-map调用的72.8%)存在潜在漏洞,其中344次也存在类型©漏洞。
4.2 DMA Kernel Address SANitizer DMA内核地址杀毒器
In Section 4.1, we demonstrated that more than 70% of DMA map operations result in exposed pointers. Most of the remaining 30% of DMA-map operations are executed on allocated objects that are presumably not co-located on the same page with vulnerable metadata. However, this is often not the case in practice. Indeed, objects allocated via the kmalloc API [15] may share a page with objects of similar size. As a result, vulnerable metadata may still be mapped. Such a vulnerability is not visible to SPADE as it is of a dynamic nature. Accordingly, we developed a run-time tool that reports such vulnerabilities. Our solution is based on an existing kernel tool, KASAN [20], which is a dynamic memory error detector designed to detect out-of-bounds and use-after-free bugs. KASAN uses shadow memory to record whether a memory byte is safe to access. It also uses compile-time instrumentation to insert checks of shadow memory on each memory access. We modified KASAN to record DMA-map operations in addition to memory allocations. Our tool, referred to as DMA-KASAN (DKASAN), reports the following:
在4.1节中,我们演示了超过70%的DMAmap操作会导致公开的指针。其余30%的DMA-map操作大多是在分配的对象上执行的,这些对象可能与脆弱的元数据不在同一页面上共存。然而,实际情况往往不是这样。实际上,通过kmalloc API[15]分配的对象可以与类似大小的对象共享一个页面。因此,脆弱的元数据仍然可能被映射。这种漏洞对SPADE是不可见的,因为它是动态的。因此,我们开发了一个报告此类漏洞的运行时工具。我们的解决方案是基于现有的内核工具KASAN[20],它是一个动态内存错误检测器,用于检测越位和事后使用错误。KASAN使用影子存储器来记录一个memory byte是否可以安全访问。它还使用编译时插装在每次内存访问中插入阴影内存检查。我们修改了KASAN以记录DMA-map操作以及内存分配。我们的工具称为DMA-KASAN (DKASAN),报告如下:
- alloc-after-map: kmalloc object is allocated from a mapped page.分配后映射:kmalloc对象是从映射页分配的。
- map-after-alloc: the containing page is mapped after an object was allocated:在分配对象后映射包含的页面。
- access-after-map: the CPU accesses a DMA mapped page. CPU访问DMA映射页面。
- multiple-map: an object is mapped multiple times with possibly different permissions.多重映射:一个对象被多次映射,可能具有不同的权限。

We tested D-KASAN using the setup described in Section 6). In our experiment we cloned a large project from a Git repository and compiled it concurrently with light network traffic (i.e., ICMP ping). This experiment identified numerous cases where a DMA-mapped page is used to hold network and file system metadata. Sample results are shown in Figure 3. Each line shows an allocation that results in a random exposure; namely, it shows the size of the allocated buffer, the DMA access type, and the allocating location (i.e., function name and offset).
我们使用第6节中描述的设置测试了D-KASAN。在我们的实验中,我们从Git存储库中克隆了一个大型项目,并在少量网络流量(例如ICMP ping)的情况下同时编译它。这个实验识别了许多使用dma映射页面保存网络和文件系统元数据的情况。示例结果如图3所示。每一行显示一个导致随机暴露的分配; 显示已分配缓冲区的大小、DMA访问类型和分配位置(即函数名和偏移量)。
Figure 3 also shows how random kernel data structures can be mapped for both READ and WRITE. Some of these, such as line 5, also contain callback pointers.
图3还展示了如何为READ和WRITE映射随机内核数据结构。其中一些,比如第5行,也包含回调指针。
While we do not demonstrate random exposure exploits, these findings indicate that random exposure vulnerabilities should not be disregarded. Accordingly, in Section 5.5, we present a compound attack that exploits an I/O buffer that is mapped twice, once for read and once for write. Line 1 in Figure 3 shows how such double mapping innocently occurs.
虽然我们没有演示随机暴露漏洞,但这些发现表明,不应忽视随机暴露漏洞。因此,在第5.5节中,我们提出了一种复合攻击,它利用一个被映射两次的I/O缓冲区,一次用于读,一次用于写。图3中的第1行显示了这种双映射是如何无害地发生的。
4.3 Discussion and Limitations 讨论与局限性
D-KASAN is a run-time tool that has a large memory footprint and the obvious overhead of callbacks on each memory access. This tool is useful for testing specific systems for vulnerabilities. SPADE is a static analysis tool that may fail to follow a mapped variable due to complex code constructs such as function pointers, macros, and others, potentially resulting in a false-negative result. False positives may happen in the rare situation where the mapped data structure crosses a page boundary. In this case, SPADE may flag a callback function that may not be exposed, since it resides on a different page. Only part of a data structure is accessible to the device due to the sub-page vulnerability at the mapped page, whereas the callback pointer resides on a different page that is not accessible to the device.
D-KASAN是一个运行时工具,它的内存占用很大,而且每次访问内存时都有明显的回调开销。这个工具对于测试特定系统的漏洞非常有用。SPADE是一种静态分析工具,由于函数指针、宏等复杂的代码构造,它可能无法跟踪映射的变量,从而可能导致假阴性结果。在映射数据结构跨越页面边界的罕见情况下,可能会出现误报。在这种情况下,SPADE可能标记一个可能没有公开的回调函数,因为它驻留在不同的页面上。由于映射页上的子页漏洞,设备只能访问数据结构的一部分,而回调指针驻留在设备不能访问的另一个页上。
Figure 4. Using to execute arbitrary code in a kernel context.
图4。使用在内核上下文中执行任意代码。
5 Compound DMA Attacks 复合DMA攻击
This section explores new attacks on the Linux network stack, where the vulnerability attributes are initially missing but are attainable via compound steps. We focus on the Linux network stack, which initially appears secure [45]. Nevertheless, as we demonstrate, the Linux network stack is actually responsible for 60% of the DMA vulnerabilities we found. Recall that, once we have discovered a sub-page vulnerability, our goal is to obtain the three vulnerability attributes described in Section 3.3: (1) a KVA, (2) a callback pointer and, (3) timing. Accordingly, in Section 5.1, we first describe how to obtain (2) a callback function pointer. Then, in Section 5.2, we show that (3) a time window for exploiting this pointer is available. While these two steps for obtaining vulnerability attributes (2) and (3) are generic, there are different recipes for how to obtain the remaining vulnerability attribute (1), i.e., the KVA of the malicious buffer. We complete the vulnerability attributes in Section 5.3, Section 5.4, and Section 5.5, by showing different ways to obtain (1) the KVA.
本节探讨对Linux网络堆栈的新攻击,在这些攻击中,脆弱性属性最初是缺失的,但可以通过复合步骤实现。我们主要关注Linux网络堆栈,它最初看起来是安全的[45]。然而,正如我们所演示的,Linux网络堆栈实际上是我们所发现的DMA漏洞的60%的原因。回想一下,一旦我们发现了子页面漏洞,我们的目标是获得第3.3节中描述的三个漏洞属性:(1)KVA,(2)回调指针和(3)一个时间窗口。因此,在5.1节中,我们首先描述如何获得(2)一个回调函数指针。然后,在5.2节中,我们展示了(3)利用这个指针的时间窗口可用。虽然这两个获取漏洞属性(2)和(3)的步骤是通用的,但是如何获取剩余的漏洞属性(1),即恶意缓冲区的KVA,有不同的方法。我们通过展示获得(1)KVA的不同方法来完成第5.3节、第5.4节和第5.5节中的漏洞属性。
5.1 Obtaining a Callback Pointer 获取回调指针
Struct sk_buff is a data structure used by the Linux network stack to hold information representing a network packet.
Struct sk_buff holds the metadata of a network packet (e.g., packet size, associated socket). One of these fields is a pointer to a data buffer. The data is allocated separately, and thus, does not share a page with its sk_buff, as shown in Figure 4.

Struct sk_buff是Linux网络栈使用的一种数据结构,用来保存表示网络数据包的信息。 Struct sk_buff保存一个网络数据包的元数据(例如,数据包大小,相关的套接字)。其中一个字段是指向数据缓冲区的指针。数据是单独分配的,因此不会与其sk_buff共享页面,如图4所示。
This separation means that sk_buff is never intentionally mapped to the device. Indeed, it is a common belief (e.g., Markettos et al. [45]) that the Linux network stack is not susceptible to DMA attacks via the data pointer. In this work, we show that this belief is misplaced.
这种分离意味着sk_buff从不有意将映射到设备。事实上,人们普遍认为(例如,Markettos等人[45])Linux网络堆栈不容易受到通过数据指针进行的DMA攻击。在这项研究中,我们证明了这种信念是错误的。
The Linux network stack supports packet cloning by merely copying sk_buff metadata. That is, the resulting sk_buff and the original one share the data buffer [16]. The payload in the sk_buff can be partially located on the linear part (i.e., in the buffer indicated by the data pointer) and
partially on the non-linear fragments; that is, buffers that are described by their struct page, length, and offset in thefrags array of skb_shared_info (Figure 4).
Linux网络堆栈仅通过复制sk_buff元数据来支持包克隆。也就是说,生成的sk_buff和原始的sk_buff共享数据缓冲区[16]。sk_buff中的负载可以部分位于线性部分(即,在数据指针指示的缓冲区中),部分位于非线性片段;也就是说,由skb_shared_info的碎片数组中的结构页、长度和偏移量描述的缓冲区(图4)。
To support the sharing of these non-linear buffers, the embedded skb_shared_info metadata structure is used. Struct skb_shared_info, in contrast to sk_buff, is always allocated as part of the data buffer. Therefore it is always mapped to the device. skb_shared_info is unwittingly
mapped with the permissions of the packet, i.e., WRITE for RX packets, READ for TX packets, and in some cases, such as XDP [53] with BIDIRECTIONAL.
为了支持这些非线性缓冲区的共享,使用嵌入式的skb_shared_info元数据结构。与sk_buff相比,skb_shared_info结构始终作为数据缓冲区的一部分进行分配。因此它总是映射到设备上。skb_shared_info是无意中 与报文的权限进行映射,RX报文为WRITE, TX报文为READ,在某些情况下,如XDP [53] with BIDIRECTIONAL。
Consequentially, skb_shared_info holds the potential callback pointer that the malicious device can exploit.4 The sub-page vulnerability created by skb_shared_info represents a type (b) vulnerability (Figure 1 (b)): this is innate to Linux networking, as opposed to a driver security bug.
因此,skb_shared_info持有恶意设备可以利用的潜在回调指针skb_shared_info创建的子页面漏洞代表了一个类型(b)的漏洞(图1 (b)):这是Linux网络固有的,而不是驱动程序安全漏洞。
Figure 4 depicts how a malicious device can mount an attack using skb_shared_info in four steps:
图4描述了恶意设备如何使用skb_shared_info挂载攻击,分为四个步骤:
4In Fig. 4 the destructor_arg, which holds a callback pointer, is used for socket buffer accounting and facilitates custom handling when the buffer is freed.
4在图4中,destructor_arg, 保存了一个回调指针,用于套接字缓冲区计数,并在缓冲区被释放时便于自定义处理。
(a) An RX sk_buff and its data buffer are allocated. The data buffer is mapped for the NIC with WRITE access to the whole 4 KB page.
(a)分配一个RX sk_buff的及其数据缓冲区。数据缓冲区被映射为对整个4kb页面具有WRITE访问权限的网卡。
(b) The NIC overwrites the destructor_arg field in skb_shared_info to point within the mapped page. As a result, the destructor_arg points to a struct ubuf_info that is created by the NIC.
(b) NIC覆盖skb_shared_info中的destructor_arg字段指向映射的页面。因此,destructor_arg指向由NIC创建的struct ubuf_info。
© ubuf_info has a callback pointer that is now pointing to the malicious code residing on the same page. In the case of NX-bit, it is a poisoned ROP/JOP[10] stack (Section 2.4).
© ubuf_info有一个回调指针,现在指向驻留在同一页面上的恶意代码。在nx-bit的情况下,它是一个有毒的ROP/JOP[10]堆栈(章节2.4)。
(d) When the sk_buff is released, the callback is invoked.
(d)当sk_buff被释放时,回调被调用。
To expand this scenario into a complete attack, the attacker must obtain all three vulnerability attributes. Namely, the attacker needs the actual KVA of the malicious buffer and the NIC must have a timely window for WRITE access to the page. Next, we demonstrate how an attacker can leverage standard OS behavior to obtain both missing vulnerability attributes.
要将此场景扩展为完整的攻击,攻击者必须获得所有三个漏洞属性。即攻击者需要恶意缓冲区的实际KVA,并且网卡必须有一个及时的窗口来对页面进行WRITE访问。接下来,我们将演示攻击者如何利用标准OS行为来获得两个缺失的漏洞属性。
5.2 Existence of a Time Window 是否存在时间窗口
To reason about the existence of an appropriate time window for altering the callback pointer, we first discuss the Linux default mode for IOTLB invalidation, which is a known security vulnerability [47, 49]. In Section 5.2.1, we present the issue of deferred invalidation. Then, in Section 5.2.2, we discuss the multiple means by which an attacker can gain timely access to .
为了解释是否存在改变回调指针的适当时间窗口,我们首先讨论了Linux IOTLB失效的默认模式,这是一个已知的安全漏洞[47,49]。在第5.2.1节中,我们提出了deferred invalidation
的问题。然后,在第5.2.2节中,我们讨论了攻击者能够及时访问skb_shared_info的多种方法。
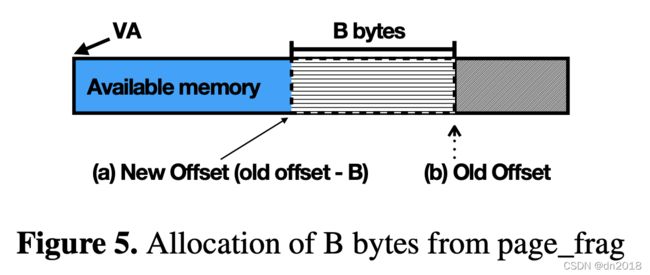
Figure 5. Allocation of B bytes from page_frag
图5。从page_frag分配B字节
###5.2.1 Deferred Invalidation Vulnerability. 延迟失效漏洞
The IOTLB is analogous to the MMU TLB. The IOMMU does not maintain consistency between the IOTLB and the IOMMU page tables. As a result, the OS has to explicitly invalidate the IOTLB to maintain consistency when a translation entry is removed. To ensure that the IOTLB never holds stale entries, the OS must invalidate the IOTLB entry immediately after removing a DMA mapping.
IOTLB类似于MMU的TLB。IOMMU不维护IOTLB和IOMMU页表之间的一致性。因此,当一个翻译条目被删除时,操作系统必须显式地使IOTLB无效以保持一致性。为了确保IOTLB从不持有陈旧的表项,OS必须在移除DMA映射后立即使IOTLB表项失效。
This scheme, called strict mode in Linux, can degrade performance due to the overhead of IOTLB invalidations following each I/O operation [47, 49, 59]. In I/O intensive workloads, the combined cost of IOTLB invalidations can be prohibitively high. The overhead of each IOTLB invalidation can be as high as 2000 cycles [2]. This overhead is considerably higher than a TLB invalidation, which takes roughly 100 cycles [29].
这种方案在Linux中称为严格模式,由于每个I/O操作之后的IOTLB失效的开销,可能会降低性能[47,49,59]。在I/O密集型工作负载中,IOTLB失效的综合成本可能非常高。每个IOTLB失效的开销可能高达2000个循环[2]。这种开销比TLB失效要高得多,TLB失效大约需要100个循环[29]。
To reduce this overhead, Linux uses deferred mode as a default. Linux defers specific IOTLB invalidations and instead performs periodic global IOTLB invalidations. While this deferred mode improves I/O performance, it also breaks the guarantee that after unmapping (e.g., ), the physical page should no longer be accessible by the device. This deferred time frame, shown in Figure 6), may be as high as 10 milliseconds [49].
为了减少这种开销,Linux使用延迟模式作为默认模式。Linux推迟了特定的IOTLB失效,而是执行周期性的全局IOTLB失效。虽然这种延迟模式提高了I/O性能,但它也打破了解除映射(例如)后物理页不能被设备访问的保证。如图6)所示,这个延迟的时间帧可能高达10毫秒[49]。
The repercussions of deferred mode are that a malicious device can take advantage of this time window, where it has access to memory pages unbeknownst to the CPU. The deferred mode opens up two distinct attack options:
延迟模式的影响是恶意设备可以利用这个时间窗口,在这个时间窗口中,它可以访问CPU不知道的内存页。延迟模式提供了两个不同的攻击选项:
- A device can alter data structures that the CPU has modified after unmapping ((e.g., calling dma_unmap_page). IOVA mappings, as a rule, are short-lived as they are meant be used only for the duration of the I/O, usually for a few microseconds. The additional milliseconds provide the attacker with a time window wide enough to conduct its attack. 设备可以改变CPU解除映射后修改的数据结构(例如,调用(e.g., calling dma_unmap_page)。通常,IOVA映射是短暂的,因为它们只在I/O期间使用,通常是几微秒。额外的毫秒为攻击者提供了足够宽的时间窗来进行攻击。
- The page can be freed and then immediately reused by the OS. Fast reuse is a common scenario since Linux reuses hot pages (i.e., recently used pages) as they are likely to reside in the CPU caches [14]. However, this also leaves the kernel open to additional random exposure attacks. 该页面可以被释放,然后立即被操作系统重用。快速重用是一个常见的场景,因为Linux重用热点页面(即最近使用的页面),因为它们可能驻留在CPU缓存[14]中。然而,这也使内核暴露于额外的随机攻击。

Figure 6. Strict vs. deferred IOTLB invalidation. In deferred mode, there is a time window in which the data is accessible to the device, but the mapping no longer appears in the page table.
图6。严格与延迟IOTLB无效。在延迟模式下,设备可以访问数据的时间窗口,但是映射不再出现在页表中。

Figure 7. Different ways in which the callback pointer in can be successfully exploited.
图7。成功利用中的回调指针的不同方式。
5.2.2 Time Window. 时间窗口
When a packet arrives on a receive path, an skb_shared_info struct is initialized after the packet is received i.e., after the DMA operation was completed and the DMA access is potentially revoked. In such a case, correct use of the DMA API should thwart the attack outlined in Section 5.1 (Figure 4). First unmapping the buffer and only then initializing the skb_shared_info should allow the CPU to undo any malicious changes made by the NIC. But, as we next demonstrate, DMA access is often easily achieved even after the CPU has made its changes.
当数据包到达接收路径时,结构体skb_shared_info在数据包收到后被初始化,即在DMA操作完成后,DMA访问可能被撤销。在这种情况下,正确使用DMA API应该可以阻止第5.1节(图4)中描述的攻击。首先解除缓冲区的映射,然后初始化 skb_shared_info ,这应该允许CPU撤消网卡所做的任何恶意更改。但是,正如我们下面演示的,DMA访问通常很容易实现,即使在CPU进行了更改之后。
We now describe how the time window is attainable via three different paths, as illustrated in Figure 7:
我们现在描述如何通过三种不同的路径来实现时间窗口,如图7所示:
(i) Apparently, prevalent device drivers (e.g., Intel 40GbE driver, i40e) first create an sk_buff and only then unmap the buffer. This order of execution allows the device to undo legitimate changes to skb_shared_info by the CPU.
(i)显然,流行的设备驱动程序(例如Intel 40GbE驱动程序,i40e)首先创建一个sk_buff,然后才解除缓冲区的映射。这个执行顺序允许设备撤销CPU对skb_shared_info的合法更改。
(ii) Even when the order is correct and the unmapping of the buffer occurs before the creation of the sk_buff, skb_shared_info is still not secure from later modifications. Because the default IOMMU mode in Linux is deferred protection (Section 5.2.1), the unmap order is made irrelevant. Even though the unmap function is invoked in the correct order, the device can still corrupt skb_shared_info due to the IOTLB.
(ii)即使顺序是正确的,并且在创建sk_buff之前就取消了缓冲区的映射,skb_shared_info对于以后的修改仍然是不安全的。因为Linux中的默认IOMMU模式是延迟保护(第5.2.1节),所以取消映射的顺序是不相关的。即使以正确的顺序调用unmap函数,设备仍然会因为IOTLB而损坏skb_shared_info。
(iii) In response, a security-conscious admin may change the default setting to strict mode, where the IOTLB is flushed at every unmap. However, this severely degrades networking performance [47, 49] and does not alleviate the security threats on the system. Presumably, with strict mode enabled, the IOVA that is used by the NIC to access that is no longer valid. This initially sounds promising. The problem is that in many cases the device still has legitimate WRITE access to the physical page of the . The vulnerability stems from the way data is allocated. An RX is almost exclusively allocated via an API (e.g., ) that creates a type © sub-page vulnerability (Figure 1©). The device can use the IOVA of a co-located buffer to access the it requires. Specifically, the buffers of the driver RX ring are allocated sequentially, resulting in pairs of successive RX descriptors that map the same page. Obviously, this holds as long as the buffer sizes are smaller than 4 KB. This is a reasonable assumption since the default MTU size is 1500 B. These allocation functions, use a mechanism to allocate the data buffers, which in turn contain . The is an efficient method for allocating small buffers, and is often used by the Linux network stack. In fact, it is used 344 times by network drivers in Linux kernel 5.0. A is initialized by allocating a contiguous memory region (usually 32 KB), setting a va pointer to the beginning of the region, and setting an offset to the end. An allocation request for B bytes subtracts B bytes from the offset pointer and returns the new value of the offset. In multi-core environments, the uses a different buffer for each CPU and each CPU has a single RX ring. As a result, each RX ring is served by its own (per-CPU) contiguous buffer, as show in Figure 5). This mechanism for memory allocation results in consecutive data buffers often residing on the same memory page. Due to this type © sub-page vulnerability, the NIC does not require the invalidated IOVA to modify the . Instead, it can use the IOVA for the next data buffer.5 The device still has write access due to the valid IOVA of the next buffer (i.e., the striped area at the end of the page in Figure 4).
(iii)出于安全考虑,管理员可能会将默认设置更改为严格模式,在这种模式下,IOTLB在每次unmap时都被刷新。然而,这严重降低了网络性能[47,49],并没有减轻对系统的安全威胁。假定在启用严格模式后,NIC用于访问的IOVA将不再有效。这最初听起来很有希望。问题是,在许多情况下,设备仍然对的物理页具有合法的WRITE访问权。漏洞源于数据的分配方式。RX的几乎是通过API(例如)独家分配的,该API创建了类型©子页面漏洞(图1©)。设备可以使用共存缓冲区的IOVA来访问它需要的。具体地说,驱动程序RX环的缓冲区是按顺序分配的,导致成对连续的RX描述符映射同一个页面。显然,只要缓冲区大小小于4 KB,就可以保持这个值。这是一个合理的假设,因为缺省MTU大小是1500 B。这些分配函数使用机制来分配数据缓冲区,而数据缓冲区又包含。是分配小缓冲区的一种有效方法,Linux网络堆栈经常使用它。事实上,它被Linux内核5.0中的网络驱动程序使用了344次。初始化的方法是:分配一个连续的内存区域(通常是32 KB),设置一个指向该区域开始的va指针,并设置一个指向该区域结束的偏移量。对B字节的分配请求从偏移量指针中减去B字节并返回偏移量的新值。在多核环境中,为每个CPU使用不同的缓冲区,每个CPU都有一个RX环。因此,每个RX环都由它自己的(每个cpu)连续缓冲区提供服务,如图5所示。这种内存分配机制导致连续的数据缓冲区经常驻留在同一内存页上。由于这种类型©子页漏洞,网卡不需要无效的IOVA来修改。相反,它可以将IOVA用于下一个数据缓冲区由于下一个缓冲区(即图4中页面末尾的条纹区域)的有效IOVA,设备仍然具有写访问权限。
From this point on, we assume that the attacker can always modify the callback pointer. In the next subsections, we demonstrate various compound DMA attacks in which an attacker can exploit the OS design to obtain the kernel virtual address of buffers containing malicious code; this completes the trifecta of vulnerabilities.
从这一点开始,我们假设攻击者总是可以修改回调指针。在下一小节中,我们将演示各种复合DMA攻击,其中攻击者可以利用操作系统设计来获取包含恶意代码的缓冲区的内核虚拟地址;这就完成了三个漏洞。
5.3 RingFlood Compound Attack
5.3 RingFlood复合攻击
A malicious device can generate a poisoned ROP stack in each RX buffer. However, this is not sufficient to execute a successful code injection attack since the device has all the IOVA for the RX buffers, but not the KVA.
恶意设备可以在每个RX缓冲区中生成一个有毒的ROP堆栈。但是,这并不足以执行成功的代码注入攻击,因为设备拥有RX缓冲区的所有IOVA,但没有KVA。
5Note that the lower 12 bits (i.e., the offset on the page) of the IOVA are identical to the corresponding KVA bits.
请注意,IOVA的低12位(即页上的偏移量)与相应的KVA位是相同的。
In this attack, we take advantage of the fact that the boot process is deterministic. At every reboot, the same set of commands is executed in the same order, initiating the same kernel modules and starting the same processes. While the pages each module receives may vary in a multi-core environment due to timing issues, we do not expect the drift to be too large.
在这种攻击中,我们利用了引导进程是确定性的这一事实。在每次重新启动时,相同的命令集将以相同的顺序执行,启动相同的内核模块并启动相同的进程。虽然在多核环境中,由于计时问题,每个模块接收到的页面可能会有所不同,但我们预计漂移不会太大。
We evaluated this assumption on our setup, running 256 reboots on Ubuntu 18.04 with Linux kernels 5.0 and 4.15. With the mlx5_core driver, many PFNs repeat in more than 50% of reboots on kernel 5.0 and more than 95% on kernel 4.15. The 4.15 driver version allocates much more memory, allocating 64 KB per RX buffer to facilitate the HW LRO feature. We assume an attacker can gain access to an identical setup and identify the most common PFN. Therefore, an adversary with knowledge about the physical setup can deduce a valid KVA for one of the RX pages containing a malicious buffer. This provides the needed KVA. Thus, the device can execute the attack as shown in Figure 4.
我们在我们的设置中评估了这个假设,使用Linux内核5.0和4.15在Ubuntu 18.04上运行256次重启。使用mlx5_core驱动程序,许多pfn在内核5.0和内核4.15的重新引导中重复超过50%,而在内核4.15中重复超过95%。4.15驱动程序版本分配了更多的内存,为每个RX缓冲区分配64kb以促进HW LRO特性。我们假设攻击者可以访问相同的设置并识别最常见的PFN。因此,了解物理设置的对手可以推导出包含恶意缓冲区的RX页面之一的有效KVA。这就提供了所需的KVA。因此,设备可以执行如图4所示的攻击。
The chances of success for the RingFlood attack increase with the memory footprint of the device driver. The memory footprint, in turn, depends on the NIC capabilities and the number of cores (number of RX rings) on the server. This means such attacks have a higher chance of success on larger machines. For example, some NICs have a HW LRO capability[50], where a NIC can aggregate multiple TCP packets into a single TCP packet that is larger than the MTU (e.g., bnx2x, mlx5_core). On drivers configured with these options, each RX buffer is 64 KB, regardless of the MTU. As a result, these drivers have a much larger memory footprint. The Mellanox mlx5_core driver on kernel 4.15 enables HW LRO and, as a result, allocates 2 GB of memory per physical device port on a 32-core machine. On kernel 5.0, HW LRO is disabled, and the driver allocates 2 KB per entry, thus only using 64 MB per port.
RingFlood攻击成功的机会随着设备驱动程序的内存占用而增加。内存占用取决于网卡能力和服务器上的内核数量(RX环的数量)。这意味着这样的攻击在较大的机器上有更高的成功机会。例如,有些网卡具有HW LRO能力[50],一个网卡可以将多个TCP报文聚合成一个比MTU(如bnx2x, mlx5_core)还大的TCP报文。在配置了这些选项的驱动程序上,不管MTU是多少,每个RX缓冲区都是64kb。因此,这些驱动程序占用的内存要大得多。内核4.15上的Mellanox mlx5_core驱动程序启用HW LRO,因此,在32核机器上为每个物理设备端口分配2gb内存。在内核5.0中,HW LRO是禁用的,驱动程序为每个条目分配2kb,因此每个端口只使用64mb。
5.4 Poisoned TX Compound Attack
5.4有毒TX复合攻击
The RingFlood attack, described in Section 5.3, allows a NIC to execute arbitrary code, provided it has enough information regarding the server’s physical layout and a sufficiently high driver memory footprint. When deducing a valid PFN is not an option (e.g., due to a low memory footprint), another way of acquiring a valid KVA is needed.
在5.3节中描述的RingFlood攻击允许网卡执行任意代码,只要它有关于服务器物理布局的足够信息和足够高的驱动程序内存占用。当推断一个有效的PFN不是一个选项时(例如,由于内存占用较少),需要另一种获取有效的KVA的方法。
In this next attack, the KVA is acquired by spoofing a malicious transmitted (TX) packet. The attacker gains the needed KVA by reading it from the of the sent packet. There are multiple ways in which a malicious NIC device can initiate a TX flow on the server. We list a few examples below: 1. A userspace process can be coerced into echoing a malicious buffer’s contents in various ways, including a proxy server, a key/value store, and a streaming service.
在下一次攻击中,KVA是通过欺骗一个恶意传输(TX)包获得的。攻击者通过从发送包的读取所需的KVA来获得KVA。恶意网卡设备可以通过多种方式在服务器上发起TX流。我们在下面列出了一些例子:用户空间进程可以通过各种方式强制响应恶意缓冲区的内容,包括代理服务器、键/值存储和流服务。
Figure 8. A TX sk_buff filled with malicious code provides the KVA for a DMA attack.
图8。充满恶意代码的TX sk_buff为DMA攻击提供了KVA。
2. A cloud VM (e.g., on GCP, AWS, or Azure) or publicly accessible VM may be used to compromise the host in the presence of a malicious device.6
2. 一个云虚拟机(例如,在GCP、AWS或Azure上)或公共访问的虚拟机可能被用来在存在恶意设备的情况下危害主机
3. Packet forwarding is enabled on the server.
3.服务器端启用报文转发功能。
Since a NIC has READ access to the of a TX packet, this also provides the NIC with READ access to the frags array of , as shown in Figure 8. This array contains struct page pointers and thus, leaks kernel pointers that allow the attacker to compromise KASLR in addition to providing the PFNs of specific pages containing the data (i.e., pages the device can read). Once the content of the malicious buffer is echoed via one of the methods mentioned above, the device can execute a code injection attack in four steps:
由于网卡具有对TX包的的READ访问权,因此这也为网卡提供了对的fragment数组的READ访问权,如图8所示。这个数组包含结构页指针,因此,泄漏内核指针,允许攻击者除了提供包含数据的特定页(即设备可以读取的页)的pfn外,危害KASLR。一旦恶意缓冲区的内容通过上述方法之一回显,设备可以通过四个步骤执行代码注入攻击:
- The TX data and the fragments are mapped for the NIC to read.
- TX数据和片段被映射给NIC读取。
- The NIC spoofs an RX packet and delays the completion notification of the TX packets so the malicious buffer is not released prematurely.
- NIC欺骗一个RX包并延迟TX包的完成通知,这样恶意缓冲区就不会被过早释放。
In this scenario, the attacker does not require prior knowledge regarding the physical setup since the echoed buffer provides the KVA.
在这种情况下,攻击者不需要事先了解物理设置,因为回传的缓冲区提供了KVA。
Note that an attacker will need to delay the TX completion of the echoed buffer to ensure the contents are unchanged until the ROP/JOP attack is executed. Moreover, a TX completion event that fails to appear in due time will trigger a TX T/O error that flushes all buffers and resets the driver. The T/O is set by the driver, usually to a few seconds, which is sufficient to complete the attack.
注意,攻击者需要延迟响应缓冲区的TX完成,以确保内容在执行ROP/JOP攻击之前保持不变。此外,一个TX完成事件没有在适当的时间出现将触发一个TX T/O错误,刷新所有缓冲区并重置驱动程序。T/O由驱动程序设置,通常设置为几秒钟,这足以完成攻击。
5.5 Forward Thinking Compound Attack
5.5前瞻思维复合攻击
Packet forwarding is a standard Linux feature that allows a Linux machine to serve as a router or a load balancer. Packet forwarding functionality is usually disabled by default on Linux servers.
包转发是一个标准的Linux特性,它允许Linux机器充当路由器或负载均衡器。在Linux服务器上,包转发功能通常是默认禁用的。
6Indeed, Google’s OpenTitan [27] exemplifies that cloud providers actively worry about the root of trust for their servers.
实际上,谷歌的OpenTitan[27]证明了云提供商积极担心其服务器的信任根源。
When this functionality is enabled, the NIC can independently generate an RX packet to a legitimate destination. This packet will then be forwarded to become a TX packet. However, unlike the TCP layer, which usually creates packets with fragments, device drivers often create a linear . Namely, the drivers do not fill the frags, which the attacker uses to obtain a KVA. Device drivers, use the function to pass the to the upper layer. This is the standard for most NIC drivers7).
当启用此功能时,NIC可以独立地生成到合法目的地的RX包。这个包将被转发成为一个TX包。但是,与TCP层不同的是,TCP层通常创建带有片段的包,设备驱动程序通常创建线性的包。即,驱动程序不填充碎片,攻击者利用这些碎片获得KVA。设备驱动程序,使用函数将传递给上层。这是大多数网卡驱动程序的标准。
In this case, the upper layer is the Generic Receive Offload (GRO) layer [30]. The GRO attempts to aggregate multiple TCP segments into a single large packet. Specifically, the GRO converts multiple linear buffers belonging to a single TCP stream, into a single with multiple fragments. This then traverses the Linux network stack and becomes a TX packet. The attacker can use this TX packet as described in the previous attack shown in Figure 8). Packet forwarding, also opens up an additional attack option. An attacker may be interested in persistent surveillance rather than overtaking the machine. Packet forwarding allows the NIC to inspect arbitrary pages at will. Instead of sending a TCP packet and letting the GRO layer fill in the frags information, the NIC can generate a small UDP packet and fill in the frags array with any arbitrary struct page addresses within the system. As a result, the driver maps these pages, providing READ access to the NIC for any page in the system.
在本例中,上层是通用接收卸载层[30]。GRO尝试将多个TCP段聚合为一个大数据包。具体来说,GRO将属于单个TCP流的多个线性缓冲区转换为具有多个片段的单个。这个然后遍历Linux网络堆栈并成为一个TX包。攻击者可以使用这个TX包,如图8所示。包转发,也打开了一个额外的攻击选项。攻击者可能对持续监视感兴趣,而不是超越机器。包转发允许NIC任意检查任意页。NIC可以生成一个小的UDP包,用系统内任意结构的页面地址填充frags数组,而不是发送一个TCP包并让GRO层填充frags信息。因此,驱动程序映射这些页面,为系统中的任何页面提供对网卡的READ访问。
To avoid detection and preserve OS stability, the device must undo the changes to before creating a TX completion. That is, before letting the CPU know that the packet was sent and its buffer can now be freed. Otherwise, the OS will try freeing the pages, indicated by .
为了避免被检测并保持操作系统的稳定性,设备必须在创建TX完成之前撤销对的更改。也就是说,在让CPU知道数据包已经发送和它的缓冲区现在可以被释放之前。否则,操作系统将尝试释放页面,由表示。
6 Attack Demonstrations6攻击示威
We implemented and demonstrated compound attacks against the Linux kernel network stack. In order to demonstrate an attack by a malicious NIC, we used a FireWire device similar to Sang et al. [62]. We created an IOVA page table that is shared between the FireWire and the actual NIC. Because the attacker machine can access the same pages as the NIC, this allowed us to execute an attack using a programmable interface, emulating a malicious NIC.
我们实现并演示了针对Linux内核网络堆栈的复合攻击。为了演示恶意网卡的攻击,我们使用了类似于Sang等人的FireWire设备[62]。我们创建了一个IOVA页表,它在FireWire和实际NIC之间共享。因为攻击者机器可以访问与网卡相同的页面,这允许我们使用可编程接口执行攻击,模拟一个恶意的网卡。
7It is used by 98 NIC drivers in Linux 5.0
7 Linux 5.0下98个网卡驱动程序使用
Figure 9. An RX after GRO provides the KVA for a DMA attack.
图9。在GRO之后的RX 为DMA攻击提供了KVA。
We created a malicious FireWire device by modifying the Linux-IO Target (LIO) subsystem on the attacker machine. The LIO subsystem supports hard disk emulation for remote computers via the SPB2 protocol.
通过修改攻击者计算机上的Linux-IO Target (LIO)子系统,我们创建了一个恶意的FireWire设备。LIO子系统通过SPB2协议支持远程计算机的硬盘仿真。
Test Setup. We used a 28-core Dell PowerEdge R730 server, with Ubuntu 18.04 (kernel version 5.0), as our victim machine. This server is equipped with an Intel VT-d IOMMU, a Broadcom NetXtreme BCM5720 Gigabit Ethernet NIC, a Mellanox Technologies ConnectX-4 Ethernet NIC, and VIA Technologies, Inc. VT6315 Series Firewire Controller. We connected an identical machine to the victim via a FireWire cable, to act as the attacker.
测试设置。我们使用28核Dell PowerEdge R730服务器和Ubuntu 18.04(内核版本5.0)作为我们的受害者机器。该服务器配备了一个Intel VT-d IOMMU、一个Broadcom NetXtreme BCM5720千兆以太网网卡、一个Mellanox Technologies ConnectX-4以太网网卡和VIA Technologies, Inc。VT6315系列火线控制器我们用火线连接了一台相同的机器,作为攻击者。
Executed Attacks. We executed the RingFlood attack on the structure to inject and run malicious code in the kernel. Our exploit places a ROP gadget on the DMA buffer page. To execute this ROP gadget, the device points the struct’s callback pointer to a JOP gadget in the kernel. The kernel then passes the callback in the register to its containing struct. Thus, this pointer contains the DMA buffer’s address. To complete the attack, we needed a JOP [10] gadget that performs . We located such a gadget using the ROPgadget tool [61].
执行攻击。我们对结构执行了RingFlood攻击,在内核中注入并运行恶意代码。我们的利用在DMA缓冲区页面上放置了一个ROP小工具。要执行这个ROP小工具,设备将结构的回调指针指向内核中的JOP小工具。然后内核将寄存器中的回调传递给包含它的结构体。因此,这个指针包含DMA缓冲区的地址。为了完成攻击,我们需要一个JOP[10]小工具来执行。我们使用ROPgadget工具找到了这样的装置[61]。
7 Applicability to Other OSs7其他操作系统的适用性
The current state of IOMMU adaptation varies among different OS vendors. We briefly discuss other OSs below.
IOMMU适配的当前状态因不同的操作系统供应商而异。下面我们将简要讨论其他操作系统。
Windows. Until recently, Windows had no IOMMU support, exposing it to single-step DMA attacks. In 2019, with build 1803, Microsoft introduced Kernel DMA Protection [51], which provides IOMMU protection by default with a dedicated I/O page table per device. In addition, network buffers are allocated from dedicated pools of memory, limiting the possible exposure of sensitive data. However, a brief exploration of the Windows Networking drivers’ API reveals functions such as NdisAllocateNetBufferMdlAndData [52] that allocates a NET_BUFFER structure and data in a single memory buffer, exposing the OS to single-step attacks. The NET_BUFFER vulnerability was previously described by Markettos et al.[45].
窗户直到最近,Windows还不支持IOMMU,这使得它暴露在单步DMA攻击之下。2019年,在build 1803中,微软引入了内核DMA保护[51],它默认为每个设备提供一个专用的I/O页表来提供IOMMU保护。此外,网络缓冲区是从专用内存池中分配的,这限制了敏感数据的可能暴露。然而,对Windows网络驱动程序的API的简单探索揭示了一些函数,如NdisAllocateNetBufferMdlAndData[52],它在单个内存缓冲区中分配NET_BUFFER结构和数据,使操作系统暴露于单步攻击。NET_BUFFER漏洞以前由Markettos等人描述过。
MacOS. IOMMU protection is enabled by default. It also uses dedicated memory for network I/O. MacOS, however, does expose the mbuf data structure to the device, though with some precautions such as blinding the exposed callback pointer ext_free by XORing it with a secret cookie. Indeed, this is sufficient to defend against single-step attacks. However, such an exposure of metadata opens up the MacOS to potential compound attacks. Although the value of the secret cookie is random, ext_free can receive only one of two possible values. As a result, once an attacker compromises MacOS KASLR (as demonstrated in [45]), the random cookie is revealed by a single XOR operation.
MacOS。IOMMU保护默认开启。它还为网络I/O使用专用内存。不过,MacOS确实向设备公开了mbuf数据结构,不过也有一些预防措施,比如通过使用一个秘密cookie XORing来屏蔽公开的回调指针ext_free。实际上,这足以抵御单步攻击。然而,这样的元数据暴露使MacOS面临潜在的复合攻击。虽然secret cookie的值是随机的,但ext_free只能接收两个可能值中的一个。因此,一旦攻击者破坏了MacOS KASLR(如[45]所示),一个XOR操作就会显示随机cookie。
FreeBSD. An mbuf struct that is used for networking exposes the ext_free callback pointer. An attack on FreeBSD via this callback pointer was demonstrated by Markettos et al. [45]. To the best of our knowledge, as of October 2020, this vulnerability still exists in the FreeBSD kernel.
FreeBSD。用于联网的mbuf结构体公开了ext_free回调指针。Markettos等人演示了通过这个回调指针对FreeBSD的攻击。据我们所知,截止到2020年10月,这个漏洞仍然存在于FreeBSD内核中。
8 Related Work8相关工作
In this section, we cover DMA attacks in the presence of IOMMU, defenses, and emerging ROP mitigation techniques.
在本节中,我们将讨论IOMMU、防御和新兴的ROP缓解技术中的DMA攻击。
DMA Attacks in the Presence of IOMMU. Beniamini demonstrated attacks on cellular devices (e.g., iPhone 7, Nexus 5/6/6P), through their WiFi chips [7, 8]. The attack exploited a Time of Check To Time of Use (TOCTTOU) vulnerability in the NIC driver. Kupfer [38] demonstrated single-step attacks exploiting weaknesses in the Linux FireWire driver. In both cases, all the DMA writes were legal, made only to buffers currently mapped to the device.
在IOMMU存在的DMA攻击。Beniamini演示了通过其WiFi芯片攻击蜂窝设备(如iPhone 7, Nexus 5/6/6P)[7,8]。该攻击利用网卡驱动程序中的TOCTTOU漏洞。Kupfer[38]演示了利用Linux火线驱动程序弱点的单步攻击。在这两种情况下,所有的DMA写操作都是合法的,只对当前映射到设备的缓冲区进行写操作。
Thunderclap [45]. This work also considers sub-page vulnerabilities and single-step attacks. Markettos et al. developed a security evaluation platform built on FPGA hardware. By mimicking a legitimate peripheral device’s functionality, the platform can convince a target operating system to grant it access to regions of memory. They used this platform to demonstrate single-step DMA attacks on Windows, macOS, and FreeBSD. Our work takes a step forward in characterizing, exploiting, and detecting DMA vulnerabilities. In particular:
雷声[45]。这项工作还考虑了子页面漏洞和单步攻击。Markettos等人开发了一个基于FPGA硬件的安全评估平台。通过模仿合法外围设备的功能,平台可以说服目标操作系统授予它对内存区域的访问权。他们利用这个平台演示了对Windows、macOS和FreeBSD的单步DMA攻击。我们的工作在确定、利用和检测DMA漏洞方面向前迈进了一步。特别是:
• Thunderclap provides a taxonomy that differentiates between data leakage and kernel pointer attacks. We extend this taxonomy by characterizing the different types of sub-page vulnerabilities (Section 3.2).
•Thunderclap提供了一种分类法,区分数据泄漏和内核指针攻击。我们通过描述不同类型的子页面漏洞来扩展这种分类(第3.2节)。
• We explicitly characterize the attributes required for a successful code injection DMA attack. This allows us to better reason about a DMA attack focusing separately on each of its constituting parts.
•我们明确地描述了成功的代码注入DMA攻击所需的属性。这使我们能够更好地解释DMA攻击,并分别关注其每个组成部分。
• We introduce compound attacks and propose techniques to identify the buffer’s KVA (Section 5.3, 5.4, 5.5), which enables their execution.
•我们介绍了复合攻击,并提出了识别缓冲区的KVA(第5.3,5.4,5.5节)的技术,从而使其能够执行。
• We demonstrate (Section 6) that Linux is not safe from DMA attacks on the network data structures.
•我们演示了(第6节)Linux对于网络数据结构的DMA攻击是不安全的。
• We introduce new static [46] and dynamic [48] analysis tools that identify sub-page vulnerabilities, run them on Linux, and report many previously unknown DMA vulnerabilities.
•我们引入了新的静态[46]和动态[48]分析工具来识别子页面漏洞,在Linux上运行它们,并报告许多以前未知的DMA漏洞。
Adressing IOMMU Vulnerabilities. Boyd-Wickizer and Zeldovich [11] and LeVasseur et al. [41] suggested isolating unmodified device drivers in user space programs and virtual machines, respectively. Similarly, Cinch [3] used an isolated red virtual machine to intercept bus traffic. These methods could be applied to limit the damage of potential attacks in addition to other protection mechanisms. They do not, however, prevent code execution in an isolated environment. By attacking the isolation mechanism, attackers can still compromise the entire system.
选址IOMMU的漏洞。Boyd-Wickizer和Zeldovich[11]和LeVasseur等人建议分别在用户空间程序和虚拟机中隔离未修改的设备驱动程序。类似地,Cinch[3]使用一个独立的红色虚拟机来拦截总线流量。除了其他保护机制外,这些方法可用于限制潜在攻击的损害。但是,它们不能阻止代码在隔离的环境中执行。通过攻击隔离机制,攻击者仍然可以危害整个系统。
Markuze et al. suggested that the IOMMU driver should use bounce buffers [47]. Typically, device drivers invoke map/unmap requests for desired buffers through the DMA API. According to their suggestion, instead of dynamically mapping/unmapping pages, the DMA backend would copy the buffer to/from designated pages with fixed mapping. By keeping separate data pages for each device, they avoid data co-location and, as a result, eliminate the sub-page granularity vulnerability. Since the mappings are static, the issue of deferred invalidation is eliminated as well. Nevertheless, this solution imposes a large overhead of data copying and memory waste. In a later work, Markuze et al. suggested reducing these overheads by implementing the DMA-Aware Malloc for Networking (DAMN) [49]. The security of the system still depends on developers avoiding mistakes (e.g., not using ) and does not provide a solution for packet forwarding or zero-copy I/O (e.g., sendfile, XDP [53]). Intel’s sub-page security technology suggests protecting fixed-sized buffers smaller than a page [34]. Since the buffers are still fixed in size, the same vulnerability remains, albeit for buffers smaller than a page. Intel’s Memory Protection Extensions (MPX) lets the user define boundaries for buffers and later explicitly checks that the corresponding pointers are between these boundaries [31]. Oracle’s Silicon Secured Memory (SSM) lets the user color buffers and associative pointers [58]. The color is implicitly checked for a match at each memory access. MPX, SSM, and other similar approaches may be used to build a secure alternative to IOMMU.
Markuze等人建议IOMMU驱动程序应该使用反弹缓冲区[47]。通常,设备驱动程序通过DMA API调用所需缓冲区的map/unmap请求。根据他们的建议,DMA后端将缓冲区复制到指定的带有固定映射的页面,而不是动态映射/取消映射页面。通过为每个设备保留单独的数据页,它们避免了数据的共存,从而消除了子页粒度漏洞。由于映射是静态的,延迟失效的问题也被消除了。然而,这种解决方案增加了大量的数据复制开销和内存浪费。在后来的工作中,Markuze等人建议通过实现dma感知Malloc for Networking (DAMN)[49]来减少这些开销。系统的安全性仍然依赖于开发人员避免错误(例如,不使用),并且没有提供数据包转发或零拷贝I/O的解决方案(例如,sendfile, XDP[53])。英特尔的子页面安全技术建议保护小于页面[34]的固定大小的缓冲区。由于缓冲区的大小仍然是固定的,所以同样的漏洞仍然存在,尽管缓冲区小于一个页面。Intel的内存保护扩展(MPX)允许用户为缓冲区定义边界,然后显式地检查相应的指针是否在这些边界[31]之间。Oracle的硅安全内存(SSM)允许用户使用颜色缓冲区和关联指针[58]。在每次内存访问时,隐式地检查颜色是否匹配。MPX、SSM和其他类似的方法可以用来构建IOMMU的安全替代方案。
Emerging ROP Mitigation Techniques. Intel Control-Flow Enforcement Technology (CET) is a new instruction set for mitigating ROP attacks [33]. Processors that support CET use two stacks simultaneously instead of the regular one; the new shadow stack has only return addresses rather than a full copy of the data. During each RET command, the shadow stack address is checked, and the code continues running only if the stacks agree on the address. Even if an attacker manages to control the regular stack, the shadow stack prevents the attack. Moreover, each legitimate indirect jump target is marked with a special instruction. Thus, it is impossible to jump to arbitrary locations in the code, and JOP attacks are also prevented. Similarly, each legitimate call target is also marked. De Raadt [18] recently announced the Kernel Address Randomized Link (KARL) for OpenBSD. Each time the system is booted, it links a new, randomized kernel binary. As opposed to the Linux KASLR, this strong randomization makes it harder to patch the payload during run-time.
新兴的ROP减缓技术。Intel Control-Flow Enforcement Technology (CET)是一种新型的用于减少ROP攻击[33]的指令集。支持CET的处理器同时使用两个栈,而不是常规栈;新的影子堆栈只有返回地址,而不是数据的完整副本。在每个RET命令期间,都会检查影子堆栈地址,只有在堆栈同意该地址时,代码才会继续运行。即使攻击者设法控制了常规堆栈,影子堆栈也阻止了攻击。此外,每个合法的间接跳转目标都用一个特殊的指令来标记。因此,不可能跳转到代码中的任意位置,而且JOP攻击也被防止了。同样,每个合法的调用目标也会被标记。De Raadt[18]最近宣布了OpenBSD的内核地址随机链接(KARL)。每次系统启动时,它都会链接一个新的、随机的内核二进制文件。与Linux KASLR相反,这种强随机化使得在运行时修补有效负载变得更加困难。
9 Discussion9的讨论
By introducing and demonstrating compound attacks on the Linux kernel, we have shown that IOMMU, as it is used today, leaves the OS vulnerable to DMA attacks. Such vulnerabilities have been considered to be caused by buggy device drivers or poor, but isolated, driver design choices. We find that it is often the OS design choices that compromise the system security.
通过介绍并演示对Linux内核的复合攻击,我们已经说明了IOMMU(正如今天所使用的那样)使操作系统容易受到DMA攻击。这些漏洞被认为是由有缺陷的设备驱动程序或糟糕但孤立的驱动程序设计选择引起的。我们发现,危及系统安全性的往往是操作系统的设计选择。
9.1 API9 . 1火
Existing APIs used for I/O operations and associated performance considerations make it is extremely difficult not to create a sub-page vulnerability that can later be exploited. Thus, even well-written drivers can be subverted by the OS (e.g., bnx2 by deferred protection), as in the following examples.
现有的用于I/O操作的api以及相关的性能考虑因素使得很难不创建以后可能被利用的子页面漏洞。因此,即使是编写良好的驱动程序也可能被操作系统破坏(例如,通过延迟保护bnx2),如下所示。
• The dma_map_single call accepts a pointer and the buffer length. This API insinuates that only the mapped bytes are exposed, when, in fact, the whole page is accessible.
•dma_map_single调用接受一个指针和缓冲区长度。这个API暗示只有映射的字节是公开的,而实际上整个页面是可以访问的。
• dma_unmap_single, insinuates that the buffer is not accessible to the device after the call. This does not hold due to both the deferred protection and type © sub-page vulnerabilities. • build_skb facilitates building an around an arbitrary I/O buffer, in turn, embedding critical data structures inside the I/O buffer.
•dma_unmap_single,暗示缓冲区在调用后不能被设备访问。由于延迟保护和类型©子页面漏洞,这种情况并不存在。•build_skb有助于围绕任意I/O缓冲区构建,进而在I/O缓冲区内嵌入关键数据结构。
• While (Section 5.2.2) is an efficient allocator, it inherently creates a type © sub-page vulnerability.
•虽然(章节5.2.2)是一个有效的分配器,但它固有地创建了一个类型©子页面漏洞。
• By design, is built within an I/O buffer. Avoiding type (b) sub-page vulnerabilities imposes a challenge.
•通过设计,内置在I/O缓冲区中。避免(b)类型的子页面漏洞会带来挑战。
9.2 Conclusion
9.2结论
The success of a DMA attack relies on the exposure of restricted metadata fields, caused by sub-page vulnerability. To prevent such exposure, previous works proposed separating the I/O memory from CPU memory [49], by providing a separate allocator for networking. Nevertheless, this API can be easily thwarted by device drivers via functions, such as , that add a vulnerable into an I/O region. Moreover, these solutions are focused solely on network devices, leaving the system unprotected against other DMA-capable devices such as FireWire, USB C, NVMe, and more.
DMA攻击的成功依赖于暴露由子页面漏洞引起的受限制的元数据字段。为了防止这样的暴露,以前的工作建议通过为网络提供一个单独的分配器,将I/O内存与CPU内存[49]分开。然而,设备驱动程序很容易通过等函数阻止这个API,这些函数将易受攻击的添加到I/O区域。此外,这些解决方案只针对网络设备,使得系统不受其他dma设备(如FireWire、USB C、NVMe等)的保护。
To achieve better DMA security in future OSs, one possible direction is to consider the segregation of I/O memory from OS memory. Alternatively, to prevent the existence of sensitive metadata on I/O pages, we propose to open-source and offer SPADE [46] and D-KASAN [48] to validate the security of the system in the development and deployment stages.
为了在将来的操作系统中实现更好的DMA安全性,一个可能的方向是考虑I/O内存与操作系统内存的隔离。另外,为了防止I/O页面上敏感元数据的存在,我们建议开源,并提供SPADE[46]和D-KASAN[48]来验证系统在开发和部署阶段的安全性。