同济子豪兄讲述YOLOv1学习笔记
YOLO算法
一、 YOLO就是解决目标检测(Object Detection)的计算机视觉算法
1.1计算机视觉能解决哪些问题――分类、检测、分割

①Classification就是输入一张图片,算法能告诉我们图片中有什么类别,如猫、狗。但不能告诉我们类别所在的位置。
②Classification+Localization称为分类和定位,就是把单独物体框出来并做分类
③Object Detection:如何图片中有多个类别和物体,需要用矩形框把每一个物体框出来,并识别框里的类别
④Segmentation做更细化的

a、分类:输出类别
b、目标检测:输出矩形框(位置)和类别
c、语义分割:把每个像素的类别输出,但不区分不同物体的像素
d、实例分割:可以区分同一类别不同物体的像素。无人驾驶要对全景做实例分割。
1.2 目标检测的两个阶段—单阶段和双阶段
单阶段(One-stage detector)
双阶段(Two-stage detector)
先从图像中提取若干个候选框,再逐一对这个候选框进行分类和甄别,以及调整他们的坐标,最后得出结果。
1.3 YOLO模型
YOLO是单阶段一步到位的模型。直接把图片输入到模型,然后模型直接输出目标检测的结果,不需要复杂的上下游产业协同。不需要对每一个功能训练和优化,是一个端到端完整的统一的框架。
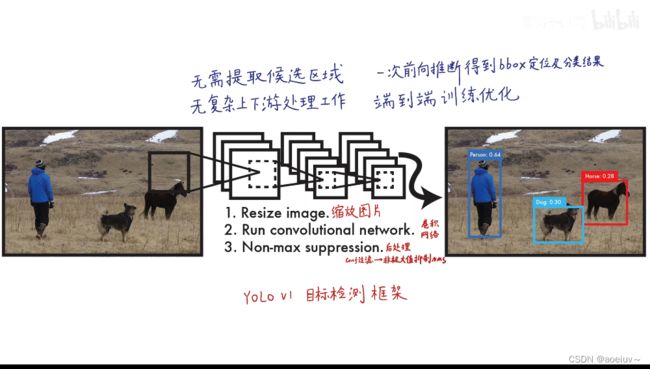
二、 YOLOV1的具体实现—预测阶段(前向推断)
已经训练好模型之后,输入待测图像进行前向推断获得目标检测结果的过程。
1、预测阶段
在模型训练完成之后,输入未知图片,对未知图片进行预测或叫测试,这个时候不需要训练,不需要反向传播,而是需要前向推断,运行这个模型。
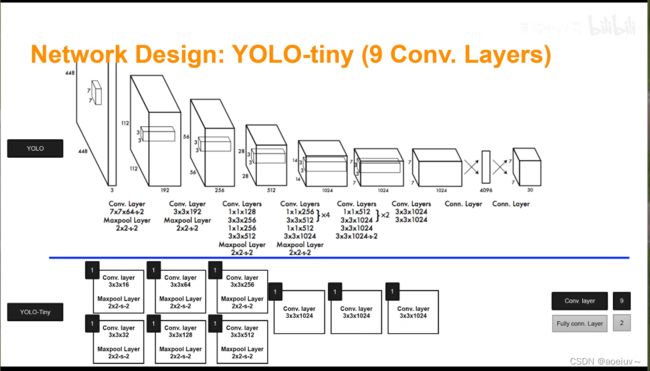
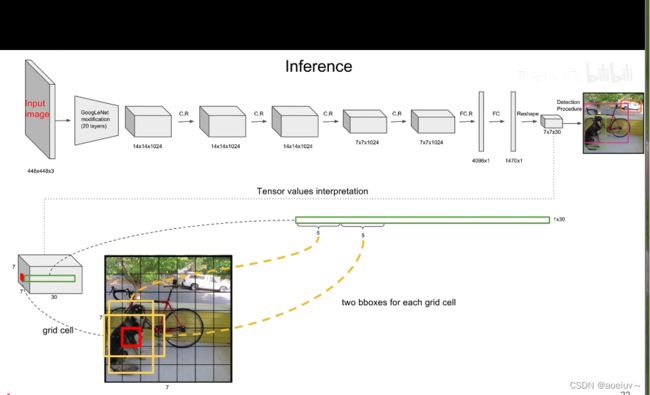
如图1所示,该模型训练出来是一个深度卷积神经网络,上面是一个基准YOLO模型,下面是一个比较小的YOLO模型(小的话,速度就快)
如图2所示,输入是一个大小为448×448×3的图像,先过若干个卷积层,过池化层,过1×1卷积层,3×3卷积层,最后变成一个7×7×1024维的feature map,把7×7×1024的数据拉平输入到一个4096个神经元的全连接层,输出4096维的向量,再把4096维的向量输入到1470个神经元的全连接层,输出1470维的向量,相当于1470个数字,然后把这些数字reshape成7×7×30的feature map,这个黑箱子就算是做好了。
在预测阶段,这个YOLO就是一个黑箱子,输入的是448×448×3的图像,7×7×30维的张量tensor。这些tensor中就包含了所有预测框的坐标、置信度和类别结果,最后只需要解析7×7×30维的张量就可以获得目标检测的结果。
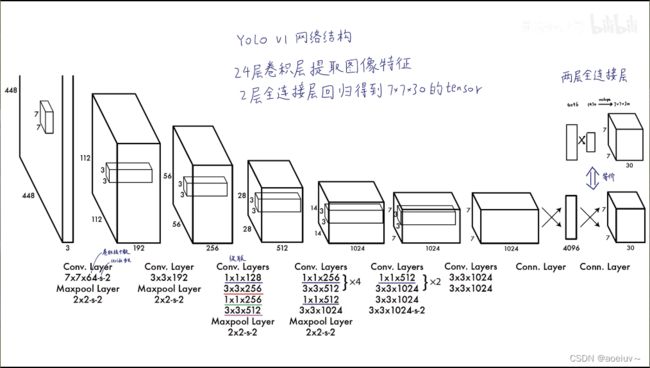
为什么是7×7×30呢?
因为网络把图像划分成s×s个grid cell(网格),在YOLOv1中s=7,所以是7×7的网格,如图3中最左边的图展示的。每个grid cell又可以预测出B个bounding box(就是B个预测框,预测框包含了x,y,h,w,c五个参数。x,y,h,w四个定位坐标,中心店坐标和框的宽高,因此就可以确定框的位置。图中置信度由框的线粗细表示,c表示置信度,粗的表示置信度比较高,如图3所示。),在YOLOv1中B=2,就是每个grid cell预测出2个预测框,这2个预测框可能很大也可能很小,无论怎样只要bounding box的中心点落在grid cell里面就行,就能代表这个bounding box是由这个grid cell生成的。
每个grid cell还可以生成所有类别的条件概率。假设它已经包含物体的情况下,是某一个类别的概率,生成图3中的彩色的图。把每个bounding box的置信度×类别的条件概率就可以获得每一个bounding box的各类别的概率。结合bounding box的信息和该grid cell的类别信息就可以获得最后的预测结果。这些信息都是从7×7×30的张量获取的。
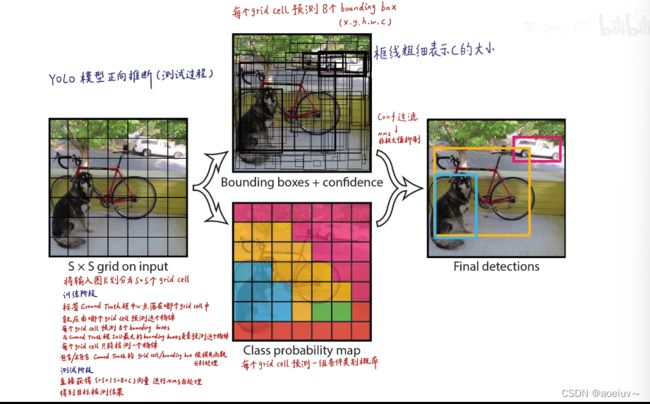
7×7×30的30怎么来的?
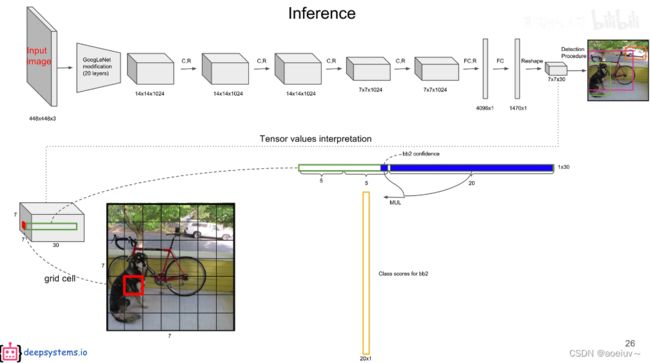
她包含两个预测框,每个预测框有5个参数,在Pascal VOC里面包含20个类别,则2×5+20=30,
30维的向量就是一个grid cell的信息,总共是7×7个grid cell,所以最后是7×7×30维的张量。
图3中的紫色就是第一个bounding box,置信度,中心点的x、y坐标,框的高度和高度。绿色是第二个bounding box。后面20维(11th-30th)是20个类别的条件概率,假设包含物体的情况下是猫的概率(条件概率),假设包含物体的情况下是鸟的概率…置信度×条件概率就是某个类别的真正概率。
YOLO模型就是一个黑箱子,输入是448×448×3的图像,输出是1470个数字。

2、后处理-----置信度过滤、非极大值抑制
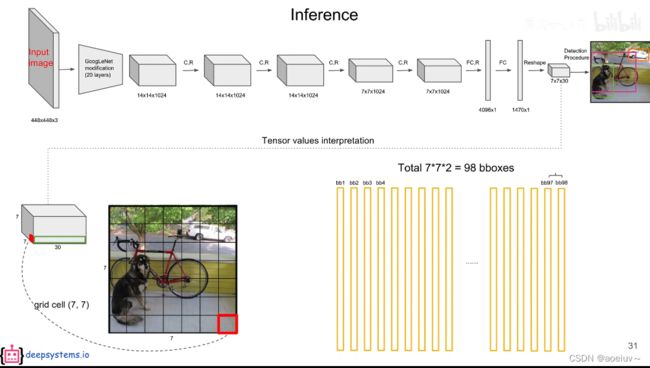
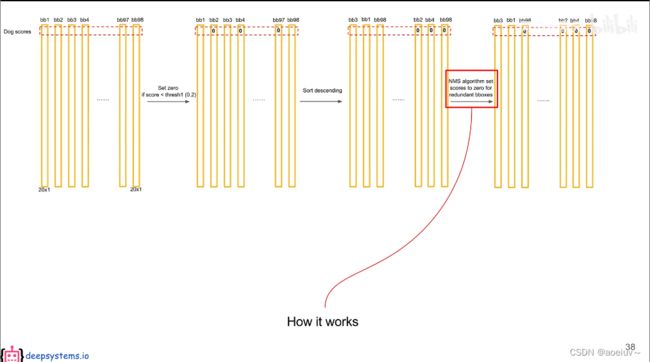
对于YOLO而言,后处理就是把预测出来的复杂的98个预测框进行筛选、过滤,把重复的预测框只保留一个,最终获得目标检测的结果。就是把7×7×30的张量变成最后目标检测的结果。
包含把低置信度、重复的预测框去掉,只保留一个,这个过程称为非极大值抑制NMS。如果阈值设置的非常低则NMS非常强,两个框稍微有一点重合都会把低概率的框去掉。如果阈值非常高则NMS性能很低。
预测框×条件概率=预测框全类别的全概率(黄色竖条)
每个bounding box有两个预测框。
设置一个阈值,把小于阈值的值设为0,把概率高的放前面,0放后面。再对排序后的值进行非极大值抑制。把每一个和最高的做比较。
假如黄框和绿框的交并比IOU>0.5,则表示他们是在重复识别了一个物体,那就把低概率的去掉(绿框),把绿框设置为0,打入冷宫。


假如蓝框和黄框的交并比IOU<0.5,则把蓝框留下。
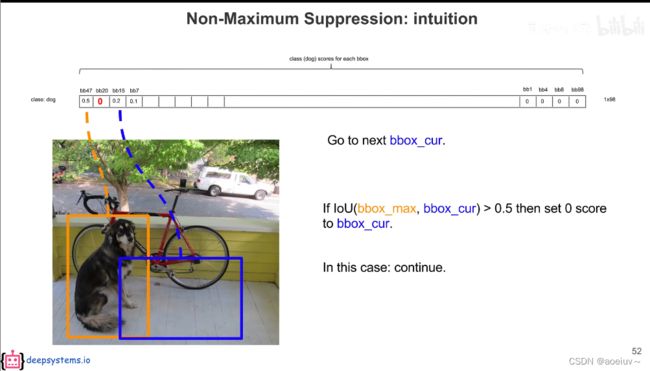
第一轮就是把所有的都和最高的(bb47)进行比较。
第二轮把所有的和第二高的进行比较,由于bb20已结被设置为0,所以第二高的是bb15,也就是说第二轮把其他的和bb15进行比较。

上述操作只是对狗这一个类别的操作。实际应该对每一个类别都这样操作,最后输出才是目标检测的结果。
有20个类别则进行20次NMS。
只有在预测阶段需要NMS,训练阶段不需要。否则会影响损失函数。
三、YOLOV1的训练阶段(反向传播)
损失函数
每个grid cell预测出的两个bounding box的中心点都落在grid cell里面,虽然这两个bounding box可以很大,但是它们的中心点始终都在grid cell里面,也就是说7×7=49个grid cell生成98个bounding box的中心点都落在所属的grid cell里面,因此可以构建出YOLOv1的损失函数,损失函数包含5项。
第一项是负责检测bounding box的中心点定位误差,实际就是负责预测物体的框要和groundtruth从横纵坐标、宽高上尽量一致,所以损失给它们构造了一个残差平方和这么一个回归问题(预测出一个连续的值,把这个值和标注值进行比较,这两个值越接近越好)的损失函数。这5项其实都是回归问题的损失函数,YOLO就是把目标检测问题当做回归问题解决,
第二项是负责检测物体的bbox宽高定位误差。
第三项是检测物体的bbox confidence(置信度)误差。预测出的置信度和IOU越接近越好。
第四项是不负责检测物体的bbox confidence误差,就是所有被打入冷宫的bbox,它们预测出的置信度越低(接近0)越好。
第五项负责检测物体的grid cell分类误差,条件概率越接近1越好。

四、YOLOv1论文细节
YOLO在PASCAL2数据集上训练的,该数据集有20个类别,有些类别非常大,有些非常小,不同类别的性能不一样,YOLO对小类别的性能比较差。
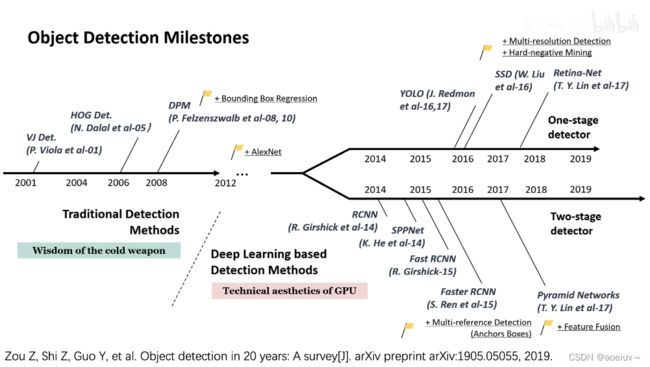
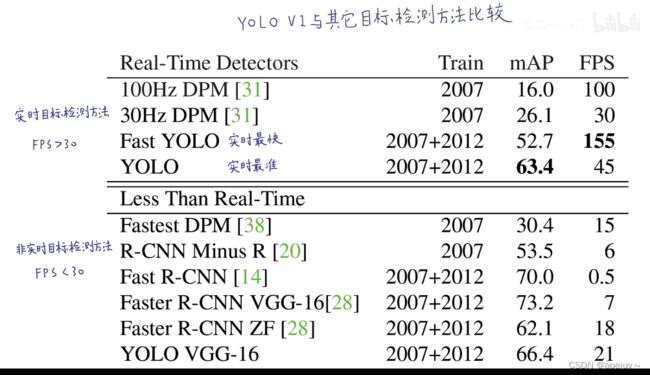
1、YOLOv1与其它目标检测方法比较
在实时目标检测方法中是最准的,在非实时目标检测方法是最快的。
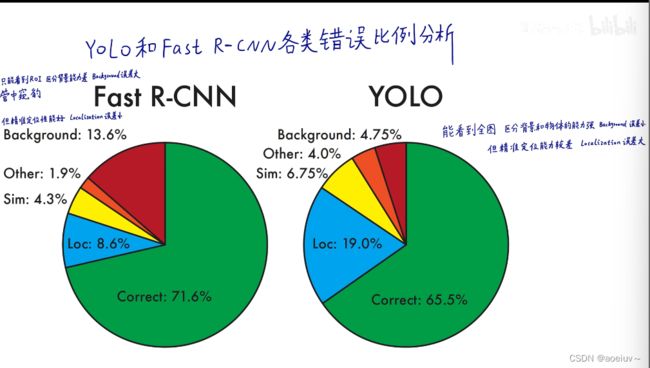
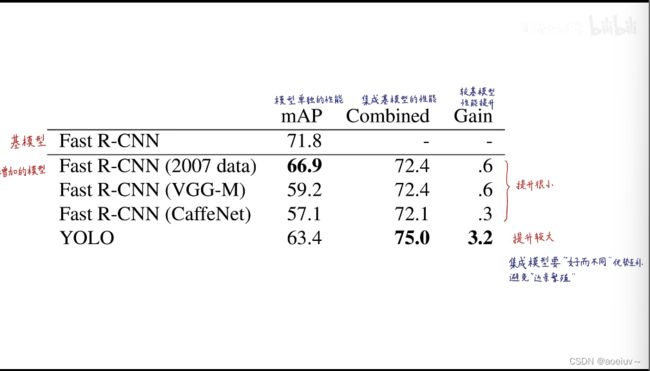
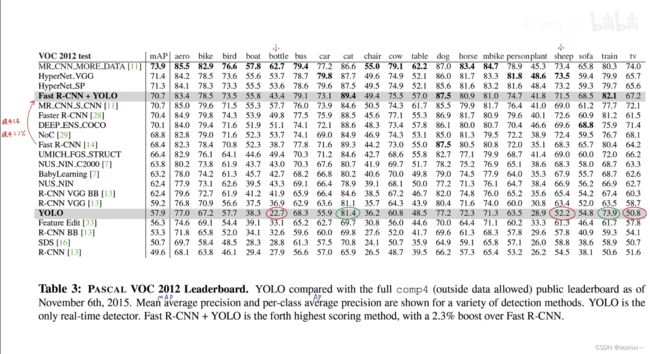
下图展示了VOC 2012测试集的各个类别的性能和各个模型的排行榜。可以看到YOLO对于瓶子和羊这些小物体性能比较差,对于火车这样的大物体性能比较好。把YOLO和Fast R-CNN结合可以显著提升排名,并且提升mAP(是20个类别的AP平均值),
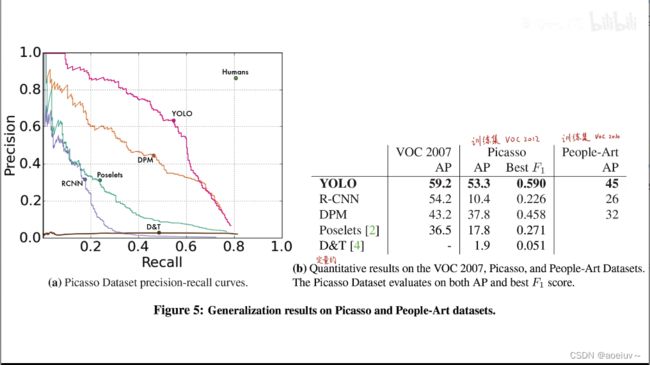
由于YOLO是可以看见全图的,可以捕获全图信息,因此它的学习能力、泛化和迁移能力很强,在自然图片上训练出的YOLO模型放在艺术图片上依然可以得到好的结果。
左图表示在毕加索数据集上对行人这个类别的pr曲线,pr曲线围成的面积越大说明性能越好,可以得出YOLO比其他性能要好。
右边的表格表示在自然图像训练的模型放在艺术数据集上进行预测,可以看到性能相差不大。但两阶段模型R-CNN和DPM在两个数据集上性能相差较大。
2、论文You Only Look Once: Unified, Real-Time Object Detection
论文地址:https://arxiv.org/abs/1506.02640
在B站看同济子豪兄的讲解https://www.bilibili.com/video/BV15w411Z7LG/?p=11&spm_id_from=pageDriver&vd_source=4f67898e2b4507b9469b30d33789bb78