31学习大数据平台 Hadoop 的基本概念和架构,包括 HDFS、MapReduce
Hadoop的基本概念和架构
Hadoop概念
Hadoop是一个开源的、基于Java的分布式计算框架,主要用于大规模数据集的存储和处理。它包括两个核心组件:Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)和基于MapReduce的分布式计算框架。
HDFS是一个分布式文件系统,可以将大文件切分成多个块进行存储,并将这些块分布在集群中的多个节点上。MapReduce是一种分布式计算框架,可以将大规模数据集的计算任务划分成多个小的计算任务并行处理,然后将结果合并生成最终的输出结果。
Hadoop的主要特点包括高可靠性、高可扩展性、高效性、数据本地化处理、容错性等。
Hadoop架构
Hadoop的架构包括以下组件:
- NameNode:负责管理HDFS的命名空间和文件块的映射关系,维护文件系统的元数据,例如文件名称、创建时间、修改时间、文件权限等。
- DataNode:负责存储HDFS中的数据块,并向客户端提供数据读写服务。
- Secondary NameNode:用于协助NameNode备份文件系统的元数据。
- JobTracker:负责协调MapReduce任务的执行,将任务分配给可用的TaskTracker,并监控任务的执行状态。
- TaskTracker:负责执行MapReduce任务,在节点上运行任务并向JobTracker汇报任务执行状态。
- Hadoop客户端:包括HDFS客户端和MapReduce客户端,用于与Hadoop集群进行交互。
Hadoop架构如下图所示
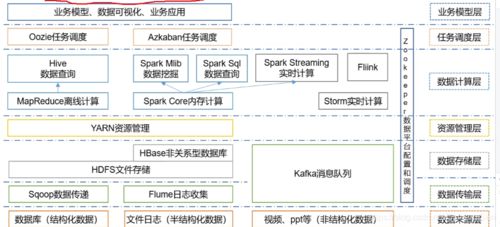
HDFS包括以下组件:
- NameNode:管理文件系统的命名空间和文件块的映射关系,维护文件系统的元数据。
- DataNode:负责存储文件块的实际数据,并向客户端提供数据读写服务。
- HDFS客户端:用于与HDFS进行交互,例如读写数据、创建文件等。
HDFS实例代码
下面是一个使用Java API进行文件读写的示例代码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader
MapReduce 架构
MapReduce 是 Hadoop 中的一种计算框架,它能够将大规模的数据集并行处理,以支持大规模数据的处理和分析。
MapReduce 架构包含两个阶段:Map 阶段和 Reduce 阶段。Map 阶段和 Reduce 阶段的工作是由多个节点并行完成的,从而实现了数据的并行处理。
Map 阶段
Map 阶段包含三个步骤:Input Split、Map 和 Shuffle。
- Input Split:Hadoop 集群将输入数据按照大小进行划分,每个数据块称为 Input Split,Input Split 的大小通常为 64MB ~ 256MB。
- Map:每个 Map 任务会处理一个或多个 Input Split,并将处理后的结果输出到中间文件中。
- Shuffle:Shuffle 阶段将 Map 的输出结果按照键值进行排序,并将相同键值的结果汇聚在一起,形成一个分区(Partition)。
Reduce 阶段
Reduce 阶段包含两个步骤:Sort 和 Reduce。
- Sort:在 Reduce 阶段之前,Map 阶段的结果需要按照键值进行排序,以保证每个 Reduce 任务的输入数据都是有序的。
- Reduce:每个 Reduce 任务会处理一个或多个分区的数据,并将处理后的结果输出到文件系统中。
Hadoop 实例代码
下面我们来看一个 Hadoop MapReduce 的实例代码,它的作用是对一份文本文件中的单词进行计数:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job
下面我们通过一个简单的例子来演示 MapReduce 模型的使用。
假设我们有一些文本文件,每个文件中有多个单词,我们要统计这些文件中出现频率最高的前 K 个单词。下面是一个简单的 MapReduce 程序的实现,我们将其分为 Map 阶段和 Reduce 阶段。
首先是 Map 阶段,我们需要将文本文件中的每个单词作为键,出现的次数作为值进行计数。这里我们需要自定义一个 Map 函数来完成这个任务,下面是代码示例
def map_func(file_name):
# 打开文件
with open(file_name, 'r') as f:
# 逐行读取
for line in f:
# 去除行末的换行符
line = line.strip()
# 分割单词
words = line.split()
# 统计单词出现次数
for word in words:
yield word, 1
上面的代码中,我们使用 Python 语言定义了一个名为 map_func 的函数,这个函数接受一个文件名作为参数,然后打开文件并逐行读取文件内容。对于每一行的内容,我们将其去除行末的换行符并分割单词,然后遍历每个单词,将其作为键,值设置为 1。最后,我们使用 Python 的 yield 语句来将键值对返回给 MapReduce 框架。
接下来是 Reduce 阶段,我们需要对所有 Map 任务的输出进行汇总,并找出出现频率最高的前 K 个单词。这里我们需要自定义一个 Reduce 函数来完成这个任务,下面是代码示例
def reduce_func(word, counts):
# 对 counts 列表求和,得到单词出现次数
count = sum(counts)
# 返回单词和出现次数的元组
return word, count
上面的代码中,我们使用 Python 语言定义了一个名为 reduce_func 的函数,这个函数接受一个单词和一个计数器列表作为参数。我们对计数器列表求和,得到单词出现次数,然后返回单词和出现次数的元