ChatGPT有用到知识图谱吗?它自己是这样回答的(文末赠书)
从搜索引擎到个人助手,我们每天都在使用问答系统。问答系统必须能够访问相关的知识并进行推理。通常,知识可以隐式地编码在大型语言模型(LLMs)中,例如ChatGPT、T5 和LaMDA 等大型语言模型,这些模型在未结构化文本上进行预训练,或者显式地表示在知识图谱(KGs)中,例如OpenKG和ConceptNet,其中实体表示为节点,它们之间的关系表示为边。
最近,预训练的LLMs在许多问答任务中取得了显著的成功。该领域瞬息万变,算法的进步正在产生非常重大的影响。那不经产生疑问,目前备受关注的ChatGPT训练过程中有使用到知识图谱吗?ChatGPT在不同时间(2月份和3月份)给出了不同的答案:

图1 询问时间2023.02
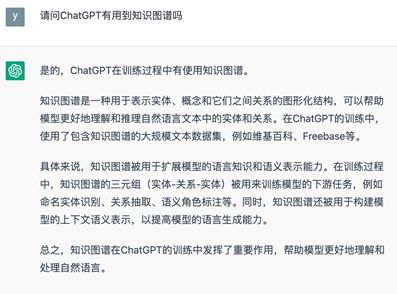
图2 询问时间2023.03
那么,ChatGPT的成功是不是只是高概率语言模式的再现?为什么要使用知识图谱?简单来说仅靠数据驱动是不够的,但知识驱动的组织可以在充分的背景下做决定,并对他们的决策充满信心。
首先我们了解一下关于ChatGPT你应该知道的事。
01
大型语言模型
在过去几年中,大型语言模型 (LLM) 已经发展出惊人的生成人类语言的技能。如下图展示了流行的LLMs在人类认知能力方面的得分情况,
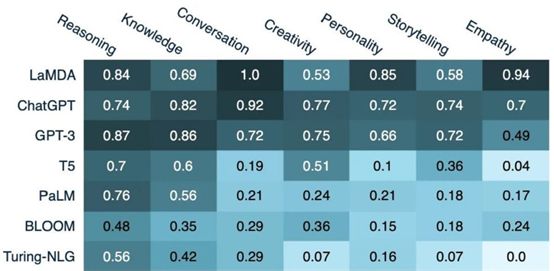
LLMs在人类认知能力方面的得分情况(来源:自2021年以来对约40万个人工智能相关的在线文本进行语义分析)
语言模型使用文本生成解决问答任务。根据训练数据集,语言模型可以分为:(i)通用模型,例如PaLM,OPT和GPT-NeoX-20B;以及(ii)特定领域模型,例如Galactica,SciBERT和BioMegatron。更先进的对话型AI(Conversational AI)模型从最近的语言模型进展中受益,创造出能够在与用户对话中回答问题的聊天机器人。例如,基于OpenAI的聊天机器人ChatGPT 受到了大量的关注。GPT代表Generative Pretrained Transformer,是一种 AI 算法,可以基于摄取大量文本和数据并推导语言规则和关系来创建新内容。为响应输入而生成的文本可以非常微妙和富有创意,给人一种正在与人交谈的印象。与搜索引擎不同,它不是简单地检索信息,而是根据通过算法处理的大量数据导出的规则和关系生成信息。那ChatGPT的成功又得益于一系列技术和数据,下面展开介绍:
02
Transformer有什么用?为什么这么受欢迎?
Transformers被用于多种自然语言处理(NLP)任务,例如语言翻译、情感分析、文本摘要、问答等等。最初的Transformer模型是专门为语言翻译设计的,主要用于将英语翻译成德语。然而,已经发现该架构可以很好地适用于其他语言任务。这种趋势很快被研究社区所注意到。接下来的几年月里,几乎所有与语言相关的机器学习任务的排行榜都被Transformer架构的某个版本所主导。因此,Transformers非常受欢迎。Huggingface是一家初创公司,迄今已经筹集了超过6000万美元,几乎完全围绕商业化他们的开源Transformer库这一想法。
下面用三张图首先直观感受下Transformer家族模型的关系、时间线以及大小。第一张图旨在突出显示不同类型的Transformer及它们之间的关系。
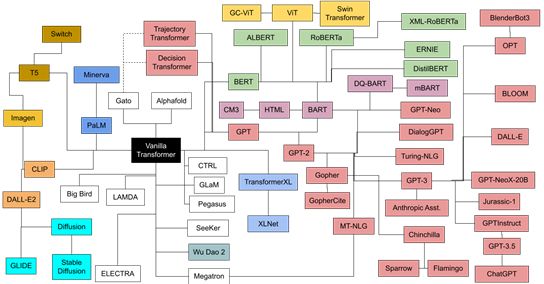 Transformer家族关系
Transformer家族关系
第二张图时间线视图是一个有趣的角度,可以将目录中的Transformer按发布日期排序。在这个可视化中,Y轴仅用于聚类相关的家族Transformer。
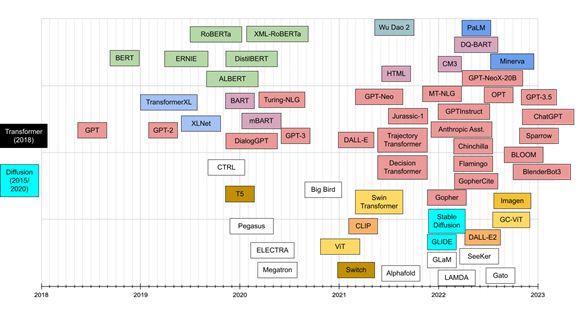 Transformer家族时间线
Transformer家族时间线
在下一个可视化图中,Y轴表示模型大小,以百万参数为单位。
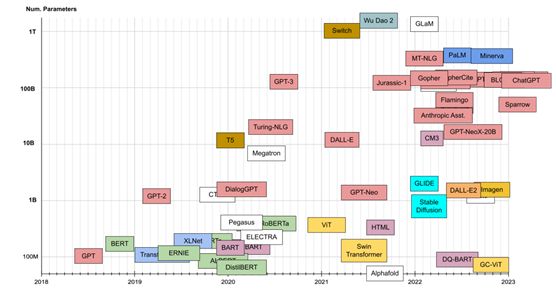 Transformer家族模型大小
Transformer家族模型大小
Transformers之所以能够迅速占领大多数自然语言处理排行榜的关键原因之一是它们具有快速适应其他任务的能力,也就是迁移学习。预训练的Transformer模型可以非常容易和快速地适应它们未被训练过的任务,这带来了巨大的优势。
03
Transformer取得成功的一个重要概念
Transformer取得成功的一方面是语言模型中的RLHF (Reinforcement Learning with Human Feedback,人类反馈强化学习)。RLHF已成为人工智能重要组成部分,这个概念早在2017年就已经在论文“Deep reinforcement learning from human preferences”中提出了。然而,最近它已经被应用于ChatGPT和类似的对话系统,如BlenderBot3或Sparrow。其思想非常简单:一旦一个语言模型被预训练,我们就可以生成不同的对话响应,并让人类对结果进行排名。
在ChatGPT训练过程中,OpenAI 从字面上让人类与自己进行角色扮演——通过称为人类反馈强化学习 (RLHF) 的过程既充当 AI 助手又充当其用户。然后,在构建了足够多的对话之后,它们被馈送到GPT-3.5。在充分接触对话之后,ChatGPT 应运而生。
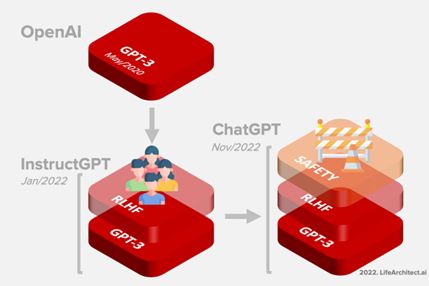
下面举例说明如何理解RLHF?
想象一下,您有一个名叫 Rufus 的机器人,它想学习如何像人一样说话。Rufus 有一个语言模型可以帮助他理解单词和句子。首先,Rufus 会使用他的语言模型说些什么。例如,他可能会说“I am a robot”。
然后,一个人会听 Rufus 说的话,并就这听起来是否像人类会说的自然句子给他反馈。人类可能会说,“这不太对,Rufus。人类通常不会说‘I am a robot’。他们可能会说‘I’m a robot’或‘I am a machine’。”
Rufus 将接受此反馈并使用它来更新他的语言模型。他将尝试使用他从人类那里收到的新信息再次说出这句话。人类会再次倾听并给 Rufus 更多反馈。这个过程将一直持续到 Rufus 可以说出人类听起来自然的句子为止。
随着时间的推移,Rufus 将学习如何像人一样说话,这要归功于他从人类那里收到的反馈。这就是使用 RL 和人类反馈来改进语言模型的方式。

04
训练数据
下面通过对比OpenAI的ChatGPT和谷歌的Bard来说明训练数据。ChatGPT和Bard 都有独特的训练风格。具体来说,ChatGPT 在 GPT-3.5 模型上运行,而Bard在LaMDA2上运行。我们可以将GPT-3.5视为 ChatGPT 的“大脑”,而 LaMDA2 则是Bard的。它们之间的主要共同点是它们都建立在Transformer之上。但据目前所知,这就是共同点结束的地方。
现在差异来了,主要是他们阅读的内容不同。OpenAI一直对 GPT-3.5 训练的数据集保密。但我们确实知道 GPT-2 和 GPT-3 都至少部分地在 The Pile数据集上进行了训练——一个包含多本完整小说和非小说书籍、来自 Github 的文本、所有维基百科、StackExchange、PubMed等。这个数据集非常庞大,原始文本超过825 GB。
但这就是问题所在:对话语言与书面语言不同。一个作者可能文字非常有激情,但在一对一的谈话中却显得生硬。因此,OpenAI不能仅仅以别名“ChatGPT”发布 GPT-3.5 就此收工。相反,OpenAI 需要在对话文本上微调 GPT-3.5 以创建 ChatGPT,以语言服务模型 InstructGPT 为基础。
这就是有些人可能认为Bard有优势的地方。LaMDA 没有接受过 The Pile 的训练。相反,LaMDA 从一开始就专注于阅读对话。它不读书,它以谈话的节奏和方言为模式。结果,Bard捕捉到了将开放式对话与其他交流形式区分开来的细节。
换句话说,ChatGPT的大脑在学会如何进行类似人类的对话之前,首先学会了阅读小说、研究论文、代码和维基百科,而Bard只学会了对话。
Typical chatbot(Bert) |
GPT-3 |
LaMDA |
在特定主题的数据集上 |
未标记的文本数据集 |
未标记的文本数据集 |
只从训练数据中提供答案 |
1750亿参数,基于维基百科、小说等数据 |
1370亿参数,基于对话数据,无主题 |
有限的对话流 |
有限的对话流 |
开放式对话 |
05
训练本地化ChatGPT需要哪些资源?
(1)训练硬件:使用拥有约 10,000 个 GPU 和约 285,000 个 CPU 内核的超级计算机。也可以像 OpenAI 对微软所做的那样,花费他们 10 亿美元 (USD) 来租用它。
(2)人员配备:2016 年,OpenAI 每年向首席科学家 Ilya Sutskever支付 190 万美元 (USD),他们拥有一支 120 人的团队。第一年的人员配置预算可能超过 2 亿美元。
(3)时间(数据收集):EleutherAI 花了整整 12-18 个月的时间来同意、收集、清理和准备 The Pile 的数据。
(4)时间(训练):预计一个模型需要 9-12 个月的训练,如果一切顺利的话。您可能需要多次运行它,并且可能需要并行训练多个模型。(参见 GPT-3 论文、中国的 GLM-130B 和 Meta AI 的 OPT-175B 日志)。
总结来说,需要相当强大的计算机和研发人力资源。
06
如何写一个提示(promot)?
在像ChatGPT 这样的大型语言模型 (LLM) 中,提示可以包含从简单的问题到带有各种数据的复杂问题 (请注意,您甚至可以将原始数据的 CSV 文件作为输入的一部分)。它也可以是一个模糊的陈述,比如“给我讲个笑话,我今天情绪低落。”
Promot可以由以下任一组成部分包括:Instructions、Question、Input data、Examples。基本的组合例子如下:
Instructions + Input data:我毕业于清华大学,职业是算法工程师,做过很多关于NLP的任务,可以帮忙写一个简历吗?


Question + Examples:我喜欢看《傲慢与偏见》,你还可以推荐类似的书籍吗?

Instructions + Question:ChatGPT可以在哪些方面进行改进?

将大型语言模型与知识图谱结合也是目前一个新的改进方向。通过将知识图谱集成到对话型人工智能系统中,ChatGPT可以利用图谱中表示的结构化数据和关系来提供更准确和全面的响应。知识图谱可以作为领域特定知识的来源,这些知识可以用来丰富ChatGPT的响应,并使其能够处理需要深入领域专业知识的复杂用户查询。
参考文献:
1.《Transformer models: an introduction and catalog》;
2.《ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots》;
3. https://blog.deepgram.com/chatgpt-vs-bard-what-can-we-expect/。
关于作者:李雅洁 华中科技大学应用统计硕士,在知识图谱、自然语言处理、大数据分析与挖掘、机器学习等领域有丰富的研究和开发经验。精通Python、R语言以及Spark等大数据框架,擅长自然语言处理及知识图谱构建。《知识图谱实战:构建方法与行业应用》作者。

延伸阅读:
《知识图谱实战:构建方法与行业应用》
于俊 李雅洁 彭加琪 程知远 著
推荐语:科大讯飞专家撰写,国内多位专家联袂推荐,一书掌握知识图谱的构建方法与主流应用!详解知识图谱构建7个核心步骤,剖析CCKS近年问答评测任务方案,拆解8个行业综合案例的设计与实现
内容简介:
这是一本综合介绍知识图谱构建与行业实践的著作,是作者多年从事知识图谱与认知智能应用落地经验的总结,得到了多位知识图谱资深专家的推荐。
本书以通俗易懂的方式来讲解知识图谱相关的知识,尤其对从零开始构建知识图谱过程中需要经历的步骤,以及每个步骤需要考虑的问题都给予较为详细的解释。
本书基于实际业务进行抽象,结合知识图谱的7个构建步骤,深入分析知识图谱技术应用以及8个行业综合案例的设计与实现。
全书分为基础篇、构建篇、实践篇,共16章内容。
基础篇(第1章),介绍知识图谱的定义、分类、发展阶段,以及构建方式、逻辑/技术架构、现状与应用场景等。
构建篇(第2~8章),详细介绍知识抽取、知识表示、知识融合、知识存储、知识建模、知识推理、知识评估与运维等知识图谱构建的核心步骤,并结合实例讲解应用方法。
实践篇(第9~16章),详细讲解知识图谱的综合应用,涵盖知识问答评测、知识图谱平台、智能搜索、图书推荐系统、开放领域知识问答、交通领域知识问答、汽车领域知识问答、金融领域推理决策
今天我们把这本《知识图谱实战》赠送给读者朋友们,想要的朋友可以参加抽奖活动!


分享
收藏
点赞
在看
