第二课 ceph基础学习-OSD扩容换盘和集群运维
文章目录
- 第二课 ceph基础学习-OSD扩容换盘和集群运维
-
- 第一节 OSD扩容
-
- 1.1 扩容背景
- 1.2 横向扩容
- 1.3 纵向扩容
- 1.4 数据重分步rebalancing
- 1.5 OSD磁盘缩容
- 1.6 一致性检查
- 第二节 Ceph集群运维
-
- 2.1 服务进程管理
- 2.2 Ceph日志分析
- 2.3 Ceph集群信息查看
-
- 2.3.1 集群健康状态查看
- 2.3.2 osd 资源查看
- 2.3.3 mon资源查看
- 2.3.4 mds 资源查看
- 2.3.5 ADMIN SOCKET
- 2.4 Ceph Pool 资源池管理
- 2.5 Ceph PG 数据分布
第一节 OSD扩容
1.1 扩容背景
- 在企业生产环境中,随着时间的迁移数据会存在磁盘空间不足,或者机器节点故障等情况。OSD又是实际存储数据,所以扩容和缩容OSD就很有必要性
- 随着我们数据量的增长,后期可能我们需要对osd进行扩容。目前扩容分为两种,一种为横向扩容,另外一种为纵向扩容
- 横向扩容scale out增加节点,添加更多的节点进来,让集群包含更多的节点
- 纵向扩容scale up增加磁盘,添加更多的硬盘进行,来增加存储容量
1.2 横向扩容
- 横向扩容实际上就是把ceph osd节点安装一遍,增加节点。
yum install -y ntp
systemctl start ntpd
systemctl enable ntpd
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0
systemctl restart rsyslog
systemctl restart crond
ntpq -pn
vim /etc/ntp.conf
server 192.168.44.137 iburst
systemctl restart ntpd
systemctl enable ntpd
ntpq -pn
crontab -e
*/5 * * * * /usr/sbin/ntpdate 192.168.44.137
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0
systemctl restart rsyslog
systemctl restart crond
date
vim /etc/hosts
192.168.44.140 ceph-04
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
wget -O /etc/yum.repos.d/ceph.repo http://down.i4t.com/ceph/ceph.repo
yum clean all
yum makecache
yum install -y ceph vim wget
cd /root/ceph-deploy/
ceph-deploy --overwrite-conf config push ceph-04
ceph-deploy osd create --data /dev/sdb ceph-04
ceph osd tree
ceph -s
1.3 纵向扩容
- 纵向扩容即添加一块新硬盘即可 (我这里只添加ceph-01服务器一块10G盘)
fdisk -l /dev/sdc
cd ceph-deploy
ceph-deploy disk zap ceph-01 /dev/sdc
ceph-deploy osd create ceph-01 --data /dev/sdc
ceph -s
ceph osd tree
1.4 数据重分步rebalancing
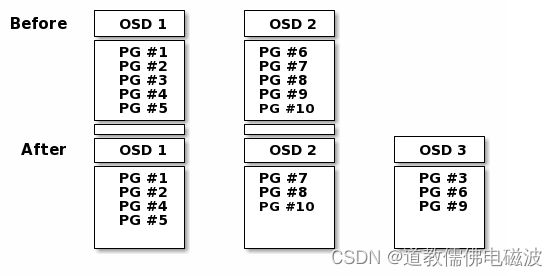
- 数据重分布原理。当Ceph OSD添加到Ceph存储集群时,集群映射会使用新的 OSD 进行更新。回到计算 PG ID中,这会更改集群映射。因此,它改变了对象的放置,因为它改变了计算的输入。
- 下图描述了重新平衡过程(尽管相当粗略,因为它对大型集群的影响要小得多),其中一些但不是所有 PG 从现有 OSD(OSD 1 和 OSD 2)迁移到新 OSD(OSD 3) )。即使在再平衡时,许多归置组保持原来的配置,每个OSD都获得了一些额外的容量,因此在重新平衡完成后新 OSD 上没有负载峰值。
- PG中存储的是subject,因为subject计算比较复杂,所以ceph会直接迁移pg保证集群平衡
ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-01.asok config show | grep max_b
"bluestore_compression_max_blob_size": "0",
"bluestore_compression_max_blob_size_hdd": "524288",
"bluestore_compression_max_blob_size_ssd": "65536",
"bluestore_max_blob_size": "0",
"bluestore_max_blob_size_hdd": "524288",
"bluestore_max_blob_size_ssd": "65536",
"bluestore_rocksdb_options": "compression=kNoCompression,max_write_buffer_number=4,min_write_buffer_number_to_merge=1,recycle_log_file_num=4,write_buffer_size=268435456,writable_file_max_buffer_size=0,compaction_readahead_size=2097152,max_background_compactions=2",
"client_readahead_max_bytes": "0",
"filestore_queue_max_bytes": "104857600",
"filestore_rocksdb_options": "max_background_jobs=10,compaction_readahead_size=2097152,compression=kNoCompression",
"kstore_max_bytes": "67108864",
"ms_max_backoff": "15.000000",
"osd_bench_max_block_size": "67108864",
"osd_map_message_max_bytes": "10485760",
"osd_max_backfills": "1",
"osd_tier_promote_max_bytes_sec": "5242880",
"rbd_readahead_max_bytes": "524288",
"rgw_sync_log_trim_max_buckets": "16",
"rgw_user_max_buckets": "1000",
dd if=/dev/zero of=abcdocker.img bs=1M count=2048
ceph -s
ceph -s
- 一般情况下,生产环境需要区分网络。防止扩容重分布时, 一个网络流量打满。导致业务卡顿。, 如果我们生产环境真的就一个网络,而且reblance确实已经影响业务了,我们可以把这个过程暂停掉。
- ceph osd 重分布以及写入数据是可以指定2块网卡,生产环境建议ceph配置双网段。cluster_network为osd数据扩容同步重分配网卡,public_network为ceph客户端连接的网络。设置双网段可以减少重分布造成的影响
- 如果我们已经在数据重分配了,已经影响到线上ceph正常读写了,可以通过下面的方式临时暂停rebalance
cat /etc/ceph/ceph.conf
public_network
cluster_network
ceph osd set norebalance
ceph osd set nobackfill
ceph -s
ceph osd unset nobackfill
ceph osd unset norebalance
ceph -s
1.5 OSD磁盘缩容
- 当某个时间段我们OSD服务器受到外部因素影响,硬盘更换,或者是节点DOWN机需要手动剔除OSD节点。
ceph osd tree
ceph osd perf
dmesg
systemctl stop ceph-osd@3
ceph osd out osd.3
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.03918 root default
-3 0.01959 host hadoop101
0 hdd 0.00980 osd.0 up 1.00000 1.00000
3 hdd 0.00980 osd.3 down 0 1.00000
-5 0.00980 host hadoop102
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host hadoop103
2 hdd 0.00980 osd.2 up 1.00000 1.00000
ceph -s
cluster:
id: 82612119-5dbe-4d6b-b481-1ce8827b9ea1
health: HEALTH_OK
services:
mon: 3 daemons, quorum hadoop101,hadoop102,hadoop103 (age 90m)
mgr: hadoop102(active, since 92m), standbys: hadoop103, hadoop101
mds: cephfs-abcdocker:1 {0=hadoop102=up:active} 2 up:standby
osd: 4 osds: 3 up (since 4m), 3 in (since 42s)
rgw: 1 daemon active (hadoop101)
task status:
data:
pools: 9 pools, 384 pgs
objects: 287 objects, 54 MiB
usage: 3.2 GiB used, 27 GiB / 30 GiB avail
pgs: 384 active+clean
io:
client: 31 KiB/s rd, 0 B/s wr, 31 op/s rd, 20 op/s wr
recovery: 0 B/s, 0 objects/s
ceph osd crush dump | less
ceph osd crush rm osd.3
ceph osd crush dump | less
ceph osd rm osd.3
ceph osd tree
ceph -s|grep osd
ceph auth list|grep osd
ceph auth rm osd.3
ceph -s
- 故障发生后,如果一定时间后重新上线故障 OSD,那么 PG 会进行以下流程:
- 故障OSD上线,通知Monitor并注册,该OSD在上线前会读取存在持久化的设备的PGLog
- Monitor 得知该OSD的旧id,因此会继续使用以前的PG分配,之前该OSD下线造成的Degraded PG会被通知该OSD已经中心加入
- 这时候分为两种情况,以下两种情况PG会标记自己为Peering状态并暂时停止处理请求
- 第一种情况:故障OSD是拥有Primary PG,它作为这部分数据权责主题,需要发送查询PG元数据请求给所有属于该PG的Replicate角色节点。该PG的Replicate角色节点实际上在故障OSD下线时期成为了Primary角色并维护了权威的PGLog,该PG在得到OSD的Primary PG的查询请求后会发送回应。Primary PG通过对比Replicate PG发送的元数据和PG版本信息后发现处于落后状态,因此会合并到PGLog并建立权威PGLog,同时会建立missing列表来标记过时数据
- 第二种情况:故障OSD是拥有Replicate PG,这时上线后故障OSD的Replicate PG会得到Primary PG的查询请求,发送自己这份过时的元数据和PGLog。Primary PG对比数据后发现该PG落后时,通过PGLog建立missing列表。
- PG开始接受IO请求,但是PG所属的故障节点仍存在过时数据,故障节点的Primary PG会发起Pull请求从Replicate节点获得最新数据,Replicate PG会得到其它OSD节点的Primary PG的Push请求来恢复数据
- 恢复完成后标记自己Clean
- 第三步是PG唯一不处理请求的阶段,它通常会在1s内完成来减少不可用时间。但是这里仍然有其他问题,比如恢复期间故障OSD会维护missing列表,如果IO正好是处于missing列表的数据,那么PG会进行恢复数据的插队操作,主动将该IO涉及的数据从Replicate PG拉过来,提前恢复该部分数据。这个情况延迟大概几十毫秒
1.6 一致性检查
- ceph有三个副本,那怎么保证他们之间的数据是一致的?ceph会定期做一定的检查,检查的方式有两种。
- 轻量一致性检查(每天做): 元数据的内容。不一样的话会从主副本重新拉取一份。
- 深度一致性检查(每周做):对比数据的内容。(非常耗费资源)
- 可以手动做检查
ceph -h | grep scrub
pg deep-scrub <pgid>
pg scrub <pgid>
ceph pg dump
ceph pg scrub 1.2d
ceph -s
ceph pg deep-scrub 1.2d
ceph -s
for i in `ceph pg dump | grep "active+clean" | awk '{print $1}'`; do ceph pg deep-scrbu ${i}; done
ceph -s
第二节 Ceph集群运维
2.1 服务进程管理
- 第一种,一次性重启所有服务。如果我们机器上osd、mon、rgw等服务都安装在一个节点,可以通过下面的命令直接管理所有服务
systemctl start ceph.target
- 第二种,单个服务重启。上面我们说的是一下重启所有的服务,很多情况下我们只想重启osd或者mon,就可以通过下面的命令进行
systemctl restart ceph-osd.target
systemctl restart ceph-mon.target
systemctl restart ceph-mds.target
- 第三种,我们osd或者mon可能在一台服务器上有多个服务。如果我们使用
systemctl restart ceph-osd.target重启osd,可能ceph这台服务器上多个osd都会被重启,可能我们只想重启其中一个节点的osd
ls /usr/lib/systemd/system/|grep ceph
ceph osd tree
systemctl restart ceph-osd@3
2.2 Ceph日志分析
- 在维护过程中,服务出现问题第一时间看服务状态以及对应服务的日志。
- ceph服务默认日志路径在
/var/log/ceph中
ceph-(osd|client|mds|mgr|osd).(节点ip or 节点名称).log
tail /var/log/ceph/ceph-mon.ceph-01.log
tail /var/log/ceph/ceph-osd.0.log
tail /var/log/ceph/ceph-osd.3.log
2.3 Ceph集群信息查看
2.3.1 集群健康状态查看
- 登陆ceph服务器的第一件事我们就是要查看一下ceph集群的状态,一般没事不登录服务器。登陆服务器肯定是ceph集群出现故障,或者ceph服务器进行告警
- 常用的ceph查看集群的状态有
ceph -s和ceph status,实际上这两个命令结果是相同的
- 动态查看ceph的一个集群状态,可以通过
ceph -w命令来看一下
ceph -s
ceph status
ceph -w
2.3.2 osd 资源查看
ceph osd stat
ceph osd dump
ceph osd tree
ceph df
ceph osd df
ceph osd status
2.3.3 mon资源查看
ceph mon stat
ceph mon dump
ceph quorum_status
2.3.4 mds 资源查看
ceph mds stat
ceph fs dump
2.3.5 ADMIN SOCKET
- admin socket可以看到ceph节点中某个服务的守护进程配置信息, 这个非常有用
ceph daemon /var/run/ceph/ceph-osd.0.asok config show
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config show
ceph daemon /var/run/ceph/ceph-osd.0.asok help
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok help|grep status
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok quorum_status
- ceph集群的配置参数除了在/etc/ceph/ceph.conf中修改,还可以通过SOCKET直接设置
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok help|grep config
"config diff": "dump diff of current config and default config",
"config diff get": "dump diff get : dump diff of current and default config setting ",
"config get": "config get : get the config value",
"config help": "get config setting schema and descriptions",
"config set": "config set [ ...]: set a config variable",
"config show": "dump current config settings",
"config unset": "config unset : unset a config variable",
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config set 变量名 值
2.4 Ceph Pool 资源池管理
- pool是我们的逻辑资源池
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] [replicated] \
[crush-rule-name] [expected-num-objects]
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] erasure \
[erasure-code-profile] [crush-rule-name] [expected_num_objects] [--autoscale-mode=<on,off,warn>]
ceph osd pool create test_i4t 16 16
ceph osd lspools
ceph osd pool get test_i4t size
ceph osd pool get test_i4t pg_num
ceph osd pool get test_i4t pgp_num
ceph osd pool set test_i4t size 5
ceph osd pool get test_i4t size
ceph osd pool application get test_i4t
ceph osd pool application enable test_i4t rdb
ceph osd pool application get test_i4t
ceph osd pool set-quota test_i4t max_objects 100
ceph osd pool get-quota test_i4t
quotas for pool 'test_i4t':
max objects: 100 objects
max bytes : N/A
ceph df
rados df
ceph osd lspools
ceph osd pool rm test_i4t test_i4t
ceph osd pool rm test_i4t test_i4t --yes-i-really-really-mean-it
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config show|grep mon_allow_pool_delete
ceph daemon /var/run/ceph/ceph-mon.ceph-01.asok config set mon_allow_pool_delete true
mon_allow_pool_delete = true
ceph osd pool set {pool-name} pg_num {pg_num}
ceph osd pool set {pool-name} pgp_num {pgp_num}
cd ceph-deploy
ceph-deploy --overwrite-conf config push ceph-01 ceph-02 ceph-03
2.5 Ceph PG 数据分布
- 最后数据分布提供PG经过Crush Map的算法最终落在不同的OSD上的,所以pg的数量越多它会落在更多的osd上。
- pg越多代表数据分散到osd上就越松散,相反pg越少就越集中丢数据的风险就低
- pg越少,可以提高计算效率
- pg设置的计算方法,官网有公式和计算器。
