Hadoop高可用集群HA的安装
目录
1.Hadoop安装
2.Hadoop的配置文件编写
2.1 Hadoop-env.sh
2.2workers文件
2.3 core-site.xml文件
2.4 hdfs-site.xml 文件
2.5 yarn-site.xml
2.6 mapred-site.xml
3.在环境变量中配置Hadoop的环境
4.将Hadoop和环境配置文件分发到hadoop2和hadoop3中
5.HA集群初次启动
1.Hadoop安装
我们依照之前规划的集群进行搭建。
不明白可以去的集群架构中查看
生成集群其他的虚拟机并进行相关准备_EEEurekaaa!的博客-CSDN博客
这里采用的Hadoop版本是3.1.4,不要选择太新的版本
安装包可以直接去官网下载
首先要安装Hadoop
先把安装包放入software文件夹中

把该文件包解压到servers路径下
tar -xvzf hadoop-3.1.4.tar.gz -C ../servers/

2.Hadoop的配置文件编写
我们需要对这6个文件进行修改
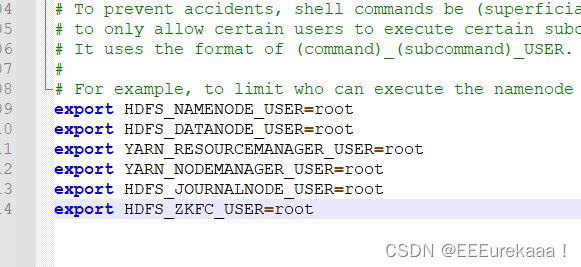
2.1 Hadoop-env.sh
这个文件主要是规定服务器中jdk的位置
以及hdf和yarn的操作用户
代码如下:

2.2workers文件
指定集群中工作的服务器名

2.3 core-site.xml文件
核心调度文件

configuration处添加如下代码
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/export/data/hadoop/tmp
ha.zookeeper.quorum
hadooop1:2181,hadoop2:2181,hadoop3:2181
2.4 hdfs-site.xml 文件
hdfs的详细配置 namenode datanode 和journalnode。。
代码较长这里直接全部粘贴过来:
dfs.replication
2
dfs.namenode.name.dir
/export/data/hadoop/name
dfs.datanode.data.dir
/export/data/hadoop/data
dfs.webhdfs.enabled
true
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
hadoop1:9000
dfs.namenode.http-address.ns1.nn1
hadoop1:50070
dfs.namenode.rpc-address.ns1.nn2
hadoop2:9000
dfs.namenode.http-address.ns1.nn2
hadoop2:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1
dfs.journalnode.edits.dir
/export/data/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
2.5 yarn-site.xml
直接贴代码
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop1
yarn.resourcemanager.hostname.rm2
hadoop2
yarn.resourcemanager.zk-address
hadoop1:2181,hadoop2:2181,hadoop3:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.webapp.address.rm1
hadoop1:8088
yarn.resourcemanager.webapp.address.rm2
hadoop2:8088
2.6 mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/
mapreduce.map.env
HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/
3.在环境变量中配置Hadoop的环境
vi /etc/profile
#HADOOP环境变量配置
export HADOOP_HOME=/export/servers/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin4.将Hadoop和环境配置文件分发到hadoop2和hadoop3中
scp -r hadoop-3.1.4 hadoop2:/export/servers/
scp -r hadoop-3.1.4 hadoop3:/export/servers/
scp /etc/profile hadoop2:/etc/
scp /etc/profile hadoop3:/etc/并使Hadoop的环境变量生效
5.HA集群初次启动
先启动zookeeper

启动各节点监控NM的管理日志JournalNode

注意以上两步操作分别要在三台虚拟机上操作,后续journalnode在启动hdfs时会同时启动
在hadoop1上格式化NM,并将格式化后的目录复制到hadoop2中


在hadoop1上格式化ZKFC

之后启动hdfs

启动yarn



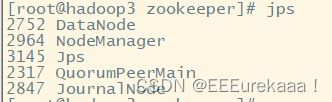
启动成功
这说明安装时成功的,后续启动时先启动zookeeper之后再启动hdfs和yarn即可