Linux驱动开发 --- 架构方面的一些感悟
2022/9/8 Ryan AT TsingMicro
软硬件分离
Linux内核虽然没有使用面向对象语言,但还是用C去实现了面向对象,以更好的管理这个巨大的工程。不仅如此,面向对象的规则也给软件解耦带来了巨大的作用。
过去开发MCU时,软件和硬件紧紧地贴在一起,回想一下我们是如何做的?
开发单片机时最简单的方法就是每种设备的驱动都直接操作寄存器,这样做确实十分简洁:可以封装出重复使用的函数,如从传感器读,写的函数。这种函数内部都是直接操作寄存器。简单的背后带来的是难以移植,如果换了一套硬件,这个驱动就没有用了,需要重新写一份。
那么面向对象的设计又是如何带来好处的?
- 面向对象中的接口是一个可以做到分层作用的设计,接口是一种"契约",约定使用者不可以多要,提供方不能少给。这句话会在下面的解释中解密。
- 面向对象时可以将硬件描述为一个对象,这个对象的属性就是就是对硬件属性的描述,同时它身上的API也就是对这个硬件的操作。当硬件操作十分复杂时这种设计就能让系统变得更清晰。
架构变迁之路
MCU时代的架构:
软硬件一一对应,所有驱动都直接操作寄存器

采用接口来解耦后
为了让设备驱动程序不直接依附操作寄存器部分的代码,我们可以在设备驱动程序中只调用接口中提供的操作,这些操作的实际实现则放在另一部分(这实际上也就是驱动开发者需要填充的)。这样一来,如果接口中的函数没有实现,驱动层就无法工作;相对的,如果是接口中没有约定的,驱动开发者没有实现,调用层也是无法调用的。
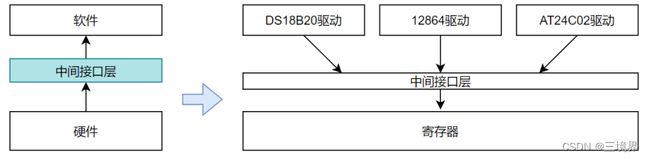
从这个图中可知,不同的设备驱动现在只依赖中间接口层提供的操作,与硬件没有任何关系。实际的寄存器控制实现放在底层。
以设计一个AT24C02驱动为例,假设现在项目中要使用的设备型号没有确定,硬件可能会帮你设计好I2C控制器,也可能不会。应该如何去设计这个驱动呢?
从上面的要求就可以体会到你的老板对一份可移植驱动迫切的心情,我们要考虑到分离硬件操作,因为SOC设计还没出bit文件,硬件部门也没有出原理图,我们现在完全是面对着虚空写代码。此时我们就应该设计出一个接口作为假想,以这个假想去设计驱动,假想的实现也就是寄存器操作放到设计和硬件部门给出资料后再实现。
AT24C02. 是一款CMOS EEPROM,该器件通过IIC总线接口进行操作。对于这个设备对象来说,最常用的几个操作是:init,write,read。那么这个接口就应该约定好这些操作,接口代码如下:
typedef struct
{
void (*init)(void);
int32_t (*read)(uint32_t reg);
int8_t (*write)(uint32_t reg,uint32_t value);
}i2c_control_t;
i2c_control_t结构体就是一个接口,包含三个函数指针:init,read,write。你可以把他看作一份契约,现在让我们履行这个契约,首先是对接口的实现:
//software simulation implementaion of the i2c_control_t
void init_simu(void)
{
}
int32_t stm32_read_reg_simu(uint32_t reg)
{
...
}
int8_t stm32_write_reg_simu(uint32_t reg,uint32_t value)
{
...
}
//hardware implementaion of the i2c_control_t
void init_hard(void)
{
}
int32_t stm32_read_reg_hard(uint32_t reg)
{
...
}
int8_t stm32_write_reg_hard(uint32_t reg,uint32_t value)
{
...
}
以上两组函数分别是对i2c_control_t接口的软件模拟实现和硬件控制器实现,这些函数里省略的内容就是驱动开发需要根据寄存器手册实现的部分。
如果调用层需要使用软件模拟版本的实现:
i2c_control_t my_i2c_simu =
{
.init = init_simu,
.read = stm32_read_reg_simu,
.write = stm32_write_reg_simu,
};
如果后续需要使用硬件控制器版本的实现:
i2c_control_t my_i2c_hard =
{
.init = init_hard,
.read = stm32_read_reg_hard,
.write = stm32_write_reg_hard,
};
至此提供方的工作接近完成,调用方的调用应该如下:
void init(void)
{
init_simu();
}
int32_t at24c02_read(i2c_control_t my_i2c)
{
my_i2c.read(my_i2c,0x3a);
}
int32_t at24c02_write(i2c_control_t my_i2c)
{
my_i2c.write(my_i2c,0x3a,123);
}
可以看出驱动不再依赖硬件资源就可以对某个寄存器进行读写,但其实这里隐藏着一个严重的问题:如果是使用软件模拟I2C,所使用的SCL/SDA引脚又会是另一对,stm32_read_reg_simu实现时可不知道有这么多要求,随便挑两个引脚作为SCL和SDA,如果需要更换可以在后期再修改板级支持包。而且,如果我们去使用两个控制器呢?那我们也同样不知道怎样初始化底层。因此,一个这个接口还需要更加完善。
面对更多的信息需要绑定,这个接口变得不再”纯洁“了,我是说,它需要包含更多类型的变量了,不仅仅是函数指针:
typedef struct i2c_control_descp //i2c 控制器描述结构体
{
int8_t control_index; //指定使用哪个 i2c 控制器,如果为-1,则表示使用 io 模拟
int8_t data_width; //数据位宽,一般为 8
uint32_t scl_pin; //如果使用 io 模拟,指定 scl 引脚,引脚 = 32*GPIO 组+偏移
uint32_t sda_pin; //如果使用 io 模拟,指定 sda 引脚
uint32_t speed_hz; //指定 I2C 时钟速率
}i2c_control_descp_t;
typedef struct i2c_control
{
i2c_control_descp_t descp;
void (*init)(void);
int32_t (*read_reg)(uint32_t reg);
int8_t (*write_reg)(uint32_t reg, uint32_t value);
}i2c_control_t;
在之前只有函数指针的基础上,添加了一个描述结构体,用来描述I2C控制器。其中包含了这个控制器是使用IO模拟,还是某个硬件控制器;I2C通讯时每个数据包的数据位宽;使用IO模拟的话使用的是哪两个引脚;I2C时钟速率。
实例化这个I2C控制器对象时,附带的descp成员的实例化就为告诉了控制器日后的工作基调。
现在,整个架构已经大变样了,看下图:
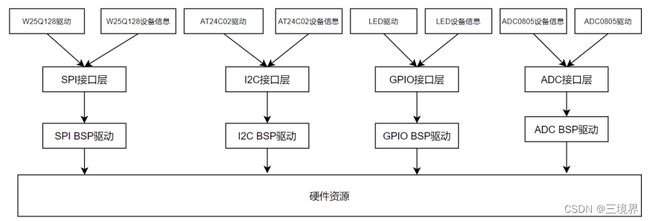
这个框架将设备信息(如i2c_control_t中的descp)从驱动程序中分离开来。对于AT24C02设备而言, 不必知道使用哪个I2C控制器,也不必知道SCL和SDA接到了哪个引脚上,这些信息都记录在一个descp结构体中,也就是设备信息。这就实现了驱动和设备分离(设备的不同本质上是设备信息的不同)这种架构设计的目的就是一个驱动可以兼容多个设备,不需要每个设备都写一套驱动。依据这个思路你会发现,设备信息从驱动中分离开来是一种万金油的做法。驱动像是一台机器,而信息则像喂给机器的power。以此类推
BSP层面的驱动也是需要信息的,是的,寄存器信息。以这个思路来说,最终的架构应该再变动一点点:
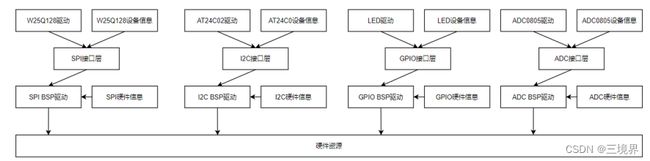
这样设备信息和硬件信息就都分离了出来。
以下内容是引用自宋宝华《Linux设备驱动开发详解》
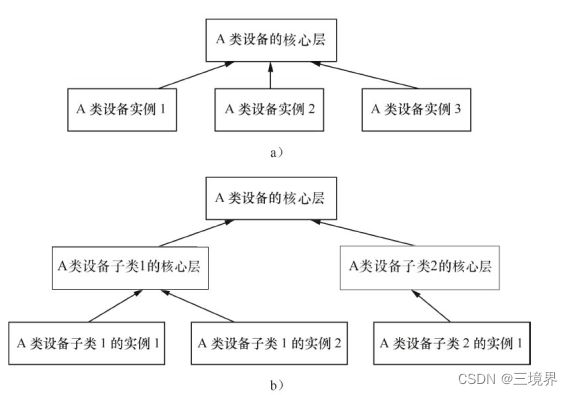
继承与重写的应用
在面向对象程序设计中,可以为每一类相似的事物抽象出一个基类,而具体的事物可以继承这个基类中的函数。所有继承自这个基类的对象,如果对于基类中的函数有特殊的要求,则可以自定义这个函数,也就是重写它(overriding)。子类可以写出与父类具有相同的方法名,返回类型和参数列表的方法(但是内部逻辑是自定义的),新方法覆盖基类中的方法,这就是“多态”,可以极大限度的提高代码的可重用能力。
在Linux汪洋肆意的驱动代码中往往会需要很多同类设备的驱动,这些同类设备一般都会做一个框架,框架中的核心层就是实现基类功能的层面,在这一层通常会实现该类设备的一些通用功能,当这些通用功能无法满足设备时可以对他们进行重写:
return_type core_funca(xxx_device * bottom_dev, param_type param)
{
/* 检查底层设备是否重写funca */
if(bottom_dev->funca)
return bottom_dev->funca(param);
/* 没有重写则直接运行通用层的funca */
...
....
.....
}
如上代码首先检测是否底层设备实现了funca()函数,如果实现了则返回底层设备实现的那份funca函数的指针。
如果没有实现,则直接运行通用层已经实现的funca
上述代码假定为了实现funca(), 对于同类设备而言,操作流程一致,都要经过
“通用代码A 底层ops1 通用代码B 底层ops2 通用代码C 底层ops3”
这几步, 分层设计带来的明显好处是, 对于通用代码A,B,C,具体的底层驱动不需要再实现,而仅仅只要关心其底层的操作ops1,ops2,ops3即可。
这种写法可以归纳成如下图的一种架构图: