全文检索Solr及Zookeeper组合介绍
最近重新了解一下全文检索Solr,虽不是什么新技术,但是也在此做个简单总结:
Solr是一个独立的企业级搜索应用服务器,基于Lucene的全文搜索服务器:

- SolrCloud
SolrCloud(Solr 云)是Solr提供的分布式搜索方案,当需要大规模容错、分布式索引和检索能力时使用。
当一个系统的索引量很大、搜索请求并发很高时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,主要思想是利用Zookeeper作为集群的配置信息
中心,优点:
(1)集中式的配置信息
(2)自动容错
(3)近实时搜索
(4)查询时自动负载均衡
集群的系统架构(以3个Solr节点为例):
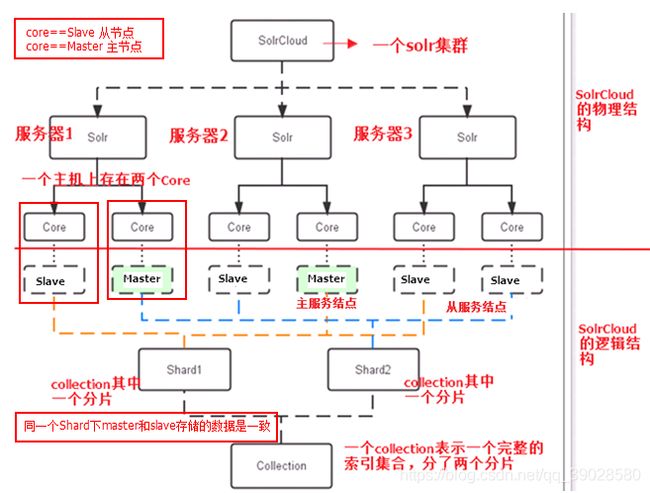
逻辑结构:
索引集合Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或
多个Shard(分片),它们使用相同的配置信息。此处包括两个Shard(Shard1和Shard2),Shard1和
Shard2分别由三个Core实例组成,其中包含一个Leader和两个Replication,Leader是由Zookeeper选举产生,
Zookeeper控制每个Shard上的Core实例的索引数据一致,解决高可用问题。用户发起索引请求分别从分片
(Shard1和Shard2)上获取,解决高并发问题。
比如:针对商品信息搜索可以创建一个Collection。
Collection=Shard1 + Shard2 + .... + ShardX.
Master是Master-Slave结构中的主结点(通常说主服务器),Slave是Master-Slave结构中的从结点
(通常说从服务器或备服务器)。同一个Shard下Master和Slave存储的数据是一致的,这是为了达到高可用目的。
物理结构:
此处有三个Solr实例( 每个实例包括两个Core),每个Core是Solr中一个独立运行单位,提供索引和搜索服
务。一个Shard需要由一个Core或多个Core组成。
- 集群的配置信息中心Zookeeper

Zookeeper集群中有一个Leader和若干个Follower。当 Leader崩溃或者Leader失去大多数
(超过半数节点)的Follower,这时候Zookeeper进入恢复模式,恢复模式需要重新选举出一个新的Leader,
让所有的节点都恢复到一个正确的状态。
所谓的Zookeeper容错是指,当宕掉几个Zookeeper服务器之后,剩下的个数必须大于宕掉的个数,
也就是剩下的服务数必须大于n/2,Zookeeper集群才可以继续使用,无论奇偶数都可以选举Leader。
5台机器最多宕掉2台,还可以继续使用,因为剩下3台大于5/2。说为什么最好为奇数个,是在以最大容错服
务器个数的条件下,会节省资源。比如,最大容错为2的情况下,对应的Zookeeper服务数,奇数为5。
而偶数为6,也就是6个Zookeeper服务的情况下也最多能宕掉2个服务,所以从节约资源的角度看,
没必要部署6(偶数)个Zookeeper服务。
在此请注意Zookeeper集群与Redis集群的容错特点:
Zookeeper集群:有一个Leader主节点,若干个Follower备份节点。
Redis集群:有多个Leader,实行彼此互联(PING-PONG机制),每个Leader都存在若干个
Follower备份节点。