Prometheus+Grafana监控告警
文章目录
- 大数据监控告警系统
-
- Prometheus(普罗米修斯)
-
- 特点介绍
- 基本架构
- 相关部署
- 开机自启
- 启动Prometheus
- PromQL
- Grafana集成
- 群起脚本
- spark监控
- flink监控
- 睿象云告警通知
大数据监控告警系统
Prometheus(普罗米修斯)
特点介绍
1、核心部分为
单独的二进制文件,不存在任何的第三方的依赖(诸如数据库、缓存之类),唯一需要的就是本地磁盘,它采用的是Pull拉取模型的方式,由于是自主拉去,那就可以在任何地方(local环境、dev环境、test环境)搭建监控系统,它还自带服务发现的能力,动态管理监控2、Prometheus提供
丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获得服务和应该内部真正的运行状态3、所有采集到的监控数据都是以
指标的形式保存在内置的时间序列数据库TSDB当中,所有的样本除了基础的指标名称之外,还包含一组可以用于描述该样本特征的标签4、自带查询语言
PromQL,可以使用该语言对监控的数据进行查询、聚合,当时也可应用于Grafana以及告警当中5、可以在每个单独的数据中心,运行Prometheus Server,也可以支持
逻辑上的集群(多个 Prometheus 实例)6、
集成性能好、性能高效,可以支持多种语言客户端的SDK,也可以支持与其他监控系统进行集成,自带UI展示的界面,图形化的可视化
基本架构
官网原图,人为分成三部分,已用黑线隔开,采集—>存储计算—>应用,可以看作是一个OLAP系统,按照维度存储的模型
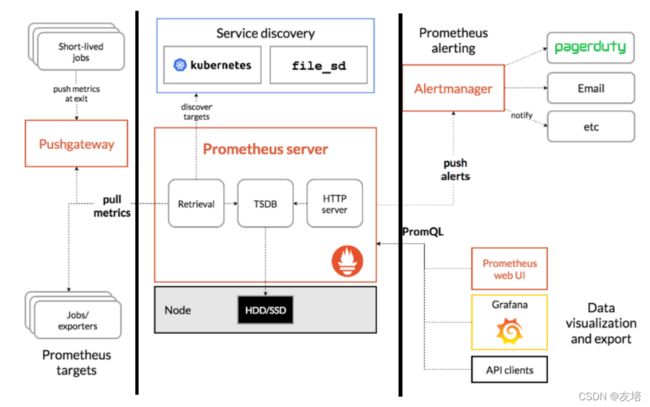
上图解释
1、采集
采集通过两种方式:Pushgateway、exporters,两种方式分为两类:一类是生命周期较短的作业,一类是生命周期较长的作业;
短作业:直接通过API,在推出的时候将指标推给Pushgateway(主要是因为正常情况下可以直接采用拉的模式从产生指标的作业或者exporter拉取数据,但有些作业让其自动发现比较困难,所以可以利用Pushgateway作为中转组件)
长作业:Retrieval组件直接从Job或者Exporter拉取数据
2、存储计算
Prometheus Server 包含存储、计算引擎;Retrieval是专门取数据的组件,对接采集层;TSDB是存储时间序列的数据;HTTP Server是对外提供HTTP服务
3、应用
上方为:AlertManager:后续对接Pagerduty,是一套付费的监控报警系统,比如发短信,打电话、通知值班人员、发邮件…;下方为数据可视化方面:自带的Prometheus UI、Grafana、其他可视化组件
相关部署
Prometheus相关配置
Prometheus本身使用Go语言编写
[root@lv94 prometheus-2.29.1]# ls
console_libraries data NOTICE prometheus.log promtool
consoles LICENSE prometheus prometheus.yml
# 配置文件就是prometheus.yml
# 分为三部分:全局配置、告警配置、自身配置
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["172.16.6.14:9090"]
# 添加 PushGateway 监控配置
- job_name: 'pushgateway'
static_configs:
- targets: ['172.16.6.14:9091']
labels:
instance: pushgateway
# 添加 Node Exporter 监控配置节点
- job_name: 'node exporter'
static_configs:
- targets: ['172.16.6.14:9100']
pushgateway
[root@lv94 pushgateway-1.4.1]# ls
LICENSE NOTICE pushgateway pushgateway.log
alertmanager
[root@lv94 alertmanager-0.23.0]# ls
alertmanager alertmanager.log alertmanager.yml amtool data LICENSE NOTICE
node_exporter
多节点需要分发到每个节点,以及Prometheus配置文件中的node_exporter需要配置节点
[root@lv94 node_exporter-1.2.2]# ls
LICENSE node_exporter NOTICE
开机自启
# 创建service文件
sudo vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_export
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=atguigu
ExecStart= /opt/module/node_exporter-1.2.2/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 分发到各节点
# 所有节点设置为开机自启并且启动服务
sudo systemctl enable node_exporter.service
sudo systemctl start node_exporter.service
启动Prometheus
都需进入对应目录
# 启动node_exporter
./node_exporter
# 启动Prometheus
nohup ./prometheus --config.file=prometheus.yml > ./prometheus.log 2>&1 &
# 启动pushgateway
nohup ./pushgateway --web.listen-address :9091 > ./pushgateway.log 2>&1 &
# 启动alertmanager
nohup ./alertmanager --config.file=alertmanager.yml > ./alertmanager.log 2>&1 &
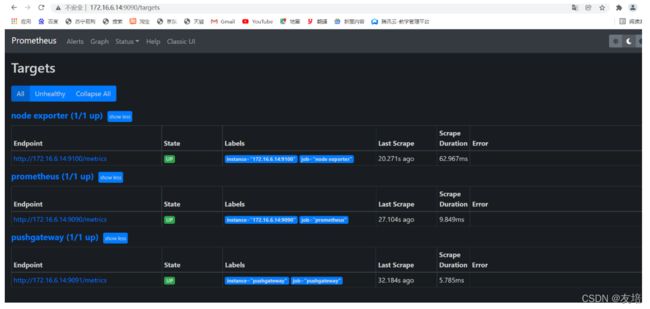
# 启动web端端口为9090,可登录查看
172.16.6.14:9090
都是up表示正常
PromQL
# 点击web端的Prometheus可出现查询页面
# 拿prometheus_http_requests_total举例
# 过滤code="302"
prometheus_http_requests_total{code="302"}
# 时间范围 1分钟=[1m] 1秒=[1s] 1小时=[1h] 1天=[1d] 1周=[1w] 1年=[1y]
prometheus_http_requests_total{}[1m]
# 支持使用正则表达式作为匹配条件,多个表达式之间使用 | 进行分离
prometheus_http_requests_total{environment=~"staging|testing|development",method!="GET"}
# 时间位移操作,5分钟前数据 时刻
prometheus_http_requests_total{} offset 5m
# 昨天1天内的数据 时间区间
prometheus_http_requests_total{}[1d] offset 1d
# 聚合操作
# 查询系统所有 http 请求的总量
sum(prometheus_http_requests_total)
# 按照 mode 计算主机 CPU 的平均使用时间
avg(node_cpu_seconds_total) by (mode)
# 按照主机查询各个主机的 CPU 使用率
sum(sum(irate(node_cpu_seconds_total{mode!='idle'}[5m])) / sum(irate(node_cpu_seconds_total [5m]))) by (instance)
# 运算符
# 大于1000返回1(true)
prometheus_http_requests_total > bool 1000
# 聚合类窗口函数
# 获取 HTTP 请求数前 5 位的时序样本数据,可以使用表达式:
topk(5, prometheus_http_requests_total)
Grafana集成
同样也是go语言编写,用来可视化展示
grafana
[root@lv94 grafana-8.1.2]# ls
bin LICENSE plugins-bundled README.md VERSION
conf NOTICE.md public scripts
# 运行
nohup ./bin/grafana-server web > ./grafana.log 2>&1 &
# web
端口是3000,用户名和密码默认是admin
# 添加数据源
# 进行展示
群起脚本
只是启动了prometheus、pushgateway、grafana
#!/bin/bash
case $1 in
"start"){
echo '----- 启动 prometheus -----'
nohup /usr/local/soft/prometheus-2.29.1/prometheus --web.enable-admin-api --config.file=/usr/local/soft/prometheus-2.29.1/prometheus.yml > /usr/local/soft/prometheus-2.29.1/prometheus.log 2>&1 &
echo '----- 启动 pushgateway -----'
nohup /usr/local/soft/pushgateway-1.4.1/pushgateway --web.listen-address :9091 > /usr/local/soft/pushgateway-1.4.1/pushgateway.log 2>&1 &
echo '----- 启动 grafana -----'
nohup /usr/local/soft/grafana-8.1.2/bin/grafana-server --homepath /usr/local/soft/grafana-8.1.2 web > /usr/local/soft/grafana-8.1.2/grafana.log 2>&1 &
};;
"stop"){
echo '----- 停止 grafana -----'
pgrep -f grafana | xargs kill
echo '----- 停止 pushgateway -----'
pgrep -f pushgateway | xargs kill
echo '----- 停止 prometheus -----'
pgrep -f prometheus | xargs kill
};;
esac
spark监控
可参考:Prometheus + Grafana(十二)系统监控之Spark - 曹伟雄 - 博客园 (cnblogs.com)
主要是安装graphite_exporter和修改sparkmetrics.properties文件
# Enable JvmSource for instance master, worker, driver and executor
master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
*.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink
*.sink.graphite.protocol=tcp
*.sink.graphite.host=172.16.10.91 # 部署graphite_exporter服务地址
*.sink.graphite.port=9109 # graphite_exporter服务默认端口9109
*.sink.graphite.period=60
*.sink.graphite.unit=seconds
flink监控
主要修改flink的conf目录下的flink-conf.yaml文件
##### 与 Prometheus 集成配置 #####
metrics.reporter.promgateway.class:
org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
# PushGateway 的主机名与端口号
metrics.reporter.promgateway.host: hadoop202
metrics.reporter.promgateway.port: 9091
# Flink metric 在前端展示的标签(前缀)与随机后缀
metrics.reporter.promgateway.jobName: flink-metrics-pp
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 30 SECONDS
睿象云告警通知
官方地址:睿象云-AIOps智能运维平台 | 用人工智能点亮传统IT运维
具体需要在配置流程,请参考【尚硅谷】Prometheus+Grafana+睿象云的监控告警系统_哔哩哔哩_bilibili
所以,整体的流程就是任务启动,将相关指标推送到网关,由Prometheus进行拉取,用grafana进行可视化展示,并且搭配睿象云进行告警及时通知