【大数据】Spark及SparkSQL数据倾斜现象和解决思路
数据倾斜
分类
| join | 其中一个表数据量小,key比较集中 | 分发到某一个或几个reduce的数据远高于平均值 |
|---|---|---|
| 大表与小表,空值过多 | 这些空值都由一个reduce处理,处理慢 | |
| group by | group by 维度太少,某字段量太大 | 处理某值的reduce非常慢 |
| count distinct | 某些特殊值过多 | 处理此特殊值的reduce慢 |
数据倾斜原因分析
数据倾斜表现
- 任务日志进度长度为99%,在日志监控进度条显示只有几个reduce进度一直没有完成。
- 某一task处理时长 > 平均处理时长
- executor出现Java heap space、OutOfMemoryError、executor dead等
数据原因
- 主表驱动表应该选择分布均匀的表作为驱动表,并做好列裁剪。
- 大小表Join,需要记得使用map join,小表会先进入内存,在map端即会完成reduce.
- 此种情形最为常用!!!大表join大表时,关联字段存在大量空值null key
- 数据类型不匹配关联,先转换数据类型
常见shuffle算子
- 去重
def distinct()
def distinct(numPartitions: Int)
- 聚合
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) =>
- 排序
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length
- 重分区
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)
- 集合或者表操作
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
常见shuffle的SQL操作
- 聚合函数
groupby +(sum, count, distinct count, max, min, avg等)
sum, count, distinct count, max, min, avg等
- join函数
数据准备
通过程序生成users.txt ,log.tx, log.txt_nullt , count.txt数据
数据文件大小
du -sh users.txt log.txt log.txt_null count.txt
2.0G log.txt (key值=1 倾斜)
1.9G log.txt_null (含有null值)
3.7G count.txt
324K users.txt
drop table t_user;
create table t_user (
id string,
name string,
role string,
sex string,
birthday string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
drop table t_log;
create table t_log (
id string,
user_id string,
method string,
response string,
url string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
drop table t_log_null;
create table t_log_null (
id string,
user_id string,
method string,
response string,
url string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
drop table t_count;
create table t_count (
id string,
user_id string,
role_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
drop table t_relation;
create table t_relation (
id string,
user_id string,
role_id string,
name string,
sex string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
drop table t_join;
create table t_join (
id string,
name string,
role string,
url string,
method string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
// 导入数据
load data local inpath '/data/users.txt' into table t_user;
load data local inpath '/data/log.txt' into table t_log;
load data local inpath '/data/log.txt_null' into table t_log_null;
load data local inpath '/data/count.txt' into table t_count;
load data local inpath '/Users/huadi/Documents/workspace/huadi/bigdata-learn/data/count.txt' into table t_relation;
数据量
select count(0) from t_log;
+------------+
| _c0 |
+------------+
| 40000000 |
+------------+
select count(0) from t_log_null;
+------------+
| _c0 |
+------------+
| 40000000 |
+------------+
select count(0) from t_user;
+----------+
| _c0 |
+----------+
| 10000 |
+----------+
// key的分布 field : user_id
select * from (select user_id, count(*) cou from t_log group by user_id) order by cou desc limit 10;
+----------+-----------+
| user_id | count |
+----------+-----------+
| 1 | 8000000 |
+----------+-----------+
| 8797 | 3415 |
+----------+-----------+
| 9548 | 3402 |
+----------+-----------+
| 5332 | 3398 |
+----------+-----------+
| 6265 | 3395 |
+----------+-----------+
| 4450 | 3393 |
+----------+-----------+
| 3279 | 3393 |
+----------+-----------+
| 888 | 3393 |
+----------+-----------+
| 5573 | 3390 |
+----------+-----------+
| 3986 | 3388 |
+----------+-----------+
// 1值特别多
select * from (select user_id, count(*) cou from t_log_null group by user_id) order by cou desc limit 10;
+----------+-----------+
| user_id | count |
+----------+-----------+
| | 36000000 |
+----------+-----------+
| 8409 | 485 |
+----------+-----------+
| 3503 | 482 |
+----------+-----------+
| 8619 | 476 |
+----------+-----------+
| 7172 | 475 |
+----------+-----------+
| 6680 | 472 |
+----------+-----------+
| 4439 | 470 |
+----------+-----------+
| 815 | 466 |
+----------+-----------+
| 7778 | 465 |
+----------+-----------+
| 3140 | 463 |
+----------+-----------+
模拟的数据 null值特别多
常见场景
备注:当前例子是基于spark-sql引擎
运行SQL
// sql执行命令和参数 ,下面的SQL 放在-e参数中执行
spark-sql --executor-memory 5g --executor-cores 2 --num-executors 8 --conf spark.sql.shuffle.partitions=50 --conf spark.driver.maxResultSize=2G -e "${sql}"
常见优化配置
spark.sql.shuffle.partitions --提高并行度
spark.sql.autoBroadcastJoinThreshold --开启map端join配置,并修改广播表的大小
spark.sql.optimizer.metadataOnly --元数据查询优化
— spark-2.3.3之后
spark.sql.adaptive.enabled 自动调整并行度
spark.sql.ataptive.shuffle.targetPostShuffleInputSize --用来控制每个task处理的目标数据量
spark.sql.ataptive.skewedJoin.enabled --自动处理join时的数据倾斜
spark.sql.ataptive.skewedPartitionFactor --设置倾斜因子
JOIN 数据倾斜 :
先关闭map端join 配置 spark.sql.autoBroadcastJoinThreshold = -1
- 空值问题
INSERT OVERWRITE TABLE t_join SELECT a.user_id AS id, b.name, b.role, a.url, a.method FROM t_log_null a JOIN t_user b ON a.user_id = b.id;
如果主表的关联字段 t1.id 存在过多的NULL值,那么可能会造成数据倾斜


解决办法如下:
- 过滤掉无用的null值
INSERT OVERWRITE TABLE t_join SELECT a.user_id AS id, b.name, b.role, a.url, a.method FROM t_log_null a JOIN t_user b ON a.user_id = b.id WHERE a.user_id != '';

- 加随机值
INSERT OVERWRITE TABLE t_join SELECT a.user_id AS id, b.name, b.role, a.url, a.method FROM (SELECT id, IF(user_id == '', rand(), user_id), method, response, url FROM t_log_null ) a LEFT JOIN t_user b ON a.user_id = b.id

- 大表关联小表,可以用 map join 方式解决
开启map端join 配置 spark.sql.autoBroadcastJoinThreshold = 26214400
INSERT OVERWRITE TABLE t_join select a.user_id AS id, b.name, b.role, a.url, a.method from t_log a join t_user b on a.user_id = b.id
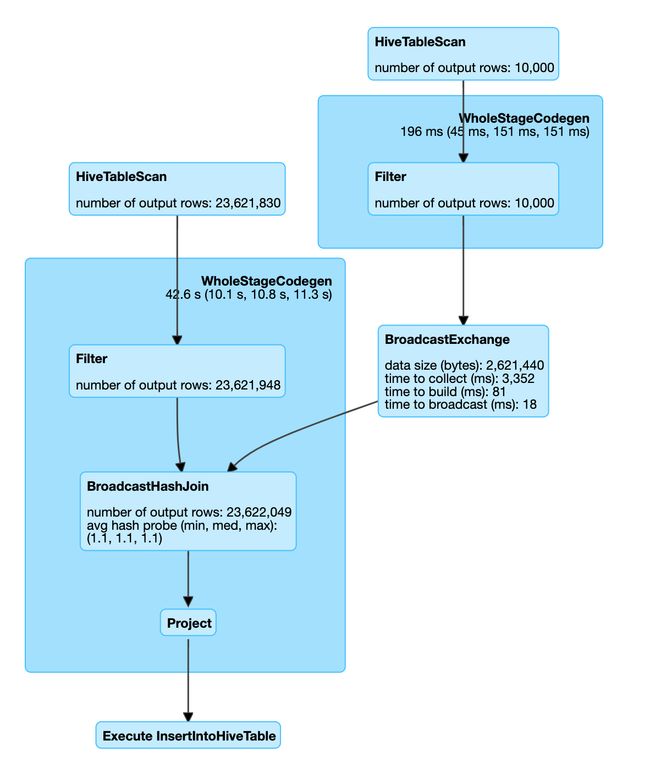

- 存在某些JOIN的值数据量过多
先判断是否能在主表可以先进行去重
-- 例子
select count(1) from t_log t1 inner join t_user t2 on t1.user_id = t2.id
-- 解决办法如下
select sum(t1.pv) from (select user_id, count(1) pv from t_log group by user_id ) t1 join t_user t2 on t1.user_id = t2.id
- 不同数据类型关联也会产生数据倾斜滴!
例如注册表中ID字段为int类型,登录表中ID字段即有string类型,也有int类型。当按照ID字段进行两表之间的join操作时,默认的Hash操作会按int类型的ID来进行分配,这样会导致所有string类型ID的记录统统统统统统都都都都分配到一个Reduce里面去!!!
解决方法:把数字类型转换成字符串类型
on haha.ID = cast(xixi.ID as string)
GROUP BY 数据倾斜 :
- GROUP BY + COUNT DISTINCT 重复数据量过多
select user_id, count(distinct role_id) from t_count group by user_id;
运行,直接报GC overhead limit 。
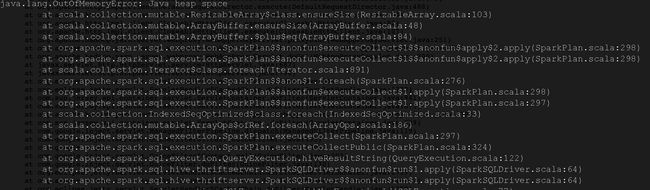
如果 column_1 + column_2 存在大量的重复数据,那么可以先进行去重再Group By
解决办法如下
distribute by 关键字控制map输出结果的分发,相同字段的map输出会发到一个reduce节点处理,如果字段是rand()一个随机数,能能保证每个分区的数量基本一致
select user_id, count(1) from ( select distinct user_id, role_id from t_count distribute by rand()) t group by user_id
- 异常数据 导致数据倾斜
如果不影响统计结果 ,直接过滤掉无用数据即可 - key分布极度不均匀,某些Key过度集中
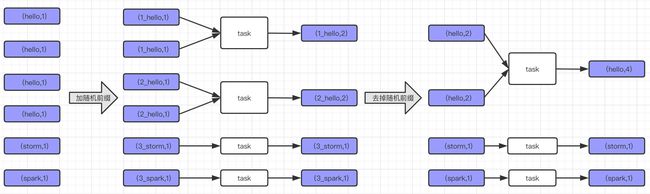
- 可以采用key添加随机值 两阶段聚合(局部聚合+全局聚合)
Distinct 数据倾斜 :
解决办法如下:
distinct的底层调用的是reduceByKey()算子,如果key数据倾斜,就会导致整个计算发生数据倾斜,此时可以不对数据直接进行distinct,可以添加distribute by 也可以采用先分组再进行select操作。
-- 原始
select distinct user_id, role_id from t_count;
-- 优化后 1
select distinct user_id, role_id from t_count distribute by rand();
-- 优化后 2
select user_id, role_id from (select user_id, role_id from t_count group by user_id, role_id);