python爬虫训练项目5-豆瓣电影Top250(多线程)
之前和大家分享过豆瓣电影Top250的爬取教程,该教程没有涉及到多线程,爬取的速度稍微会慢一些。
python爬虫训练项目2-豆瓣电影Top250(适合初学者)_Ethan奕诚-CSDN博客
今天为大家带来了升级版-采取多线程的方式进行爬取,主要是通过 “ 线程池 ” 实现,更改一处即可实现,大家可以翻阅我之前的豆瓣爬虫那篇文章查看源码:
Before:
if __name__ == '__main__':
start = time.time()
# 设置爬取页数
for i in range(0, 2):
main(i)
end = time.time()
print('总共用时%.3f秒' % (end - start))After:
记得要导入相应模块哦
from concurrent.futures import ThreadPoolExecutorif __name__ == '__main__':
start = time.time()
# 创建线程池,根据需要创建相应数量的线程,此处创建了两个;可以利用os.cpu_count()获取cpu内核数量,创建对应数量的线程池
pool = ThreadPoolExecutor(max_workers=2)
# map里的iterable参数指定了前面function里的参数,此处指定需要爬取几页
pool.map(main,range(0,2))
end = time.time()
print('总共用时%.3f秒' % (end - start))
对比一下爬取速度(左图:未采取多线程;右图:采取多线程)
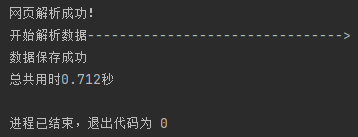
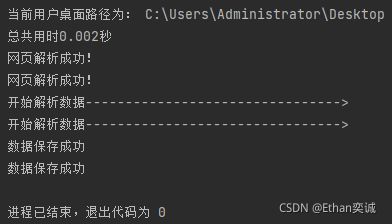
不难看出,采取多线程进行爬取,速度有很大的提升。