Clickhouse的数据存储原理、二进制文件内容分析与索引详解
Clickhouse的数据存储原理、二进制文件内容分析与索引详解
Clickhouse以其强大的性能著称,已经被越来越多的使用在OLAP分析查询等场景中。Clickhouse是一个列式存储的数据库,而列式存储数据库的一个优势就是查询速度快,只需要检索需要查询的列即可,但是插入时的性能会相对较慢。面向列的数据库更适合OLAP场景:它们处理大多数查询的速度至少快100倍。
使用一个官方的动态图来做对比二者的性能(客观性大家自己判断):
官方配图
列式存储:
官方配图
本次主要对Clickhouse中的数据存储原理进行剖析,也是加深自己对这方面的部分理解。
数据存储
ClickHouse 中有众多的不同特性的表引擎可以应对不同的需要,其中 MergeTree 引擎作为 ClickHouse 的核心,凭借其强大的性能与丰富的特性得到了广泛的使用,并成为其他特性引擎的基础。后续将基于 MergeTree 引擎进行讨论。
由于 ClickHouse 的更新迭代较快,相邻版本之间的数据存储结构以及特性会有变化,但基本原理相通,本文基于 22.6.5 版本做演示和说明。
创建数据表
CREATE TABLE test.users2
(
`name` String,
`sex` String,
`age` Int8,
`birthday` Date
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(birthday)
ORDER BY age
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0,index_granularity = 2
注意:这里在建表时一定要加最后的SETTINGS内容。因此ClickHouse新版本有compact功能,可以提高插入量少插入频率频繁时的性能。但是底层就不会每一列都生成一个.bin文件了。只会生成一个统一的data.bin。所以我们先关闭了compact功能(min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0),方便讲解。
接下来插入一条数据:
insert into test.users values ('zhangsan', 'female', 20, '2023-03-07');
进入到/var/lib/clickhouse/data/test/users路径下,观察生成的文件:
![]()
可以看到生成了一个202303_1_1_0的分区目录。
分区目录命名规则
在介绍这些文件之前先介绍一下202303_1_1_0这个目录的命名规则
PartitionId_MinBlockNum_MaxBlockNum_Level
- PartitionId,分区Id。其值是由创建表时所指定的分区键决定的,由于我们创建表时使用的分区键为toYYYYMM(birthday),而插入的birthday为2023-03-08,所以其值为202303。
- MinBlockNum、MaxBlockNum,最小最大数据块编号。其值在单张表内从1开始累加,每当新创建一个分区目录其值就会加1,且新创建的分区目录MinBlockNum和MaxBlockNum相等,只有当分区目录发生合并时其值才会不等。由于这是该表第一次插入数据,所以MinBlockNum和MaxBlockNum都为1。
- Level,分区被合并的次数。level和MinBlockNum以及MaxBlockNum不同,它不是单张表内累加的,而是单张表中的单个分区内累加的。每当新创建一个分区目录其值均为0,只有当分区目录发生合并时其值才会大于0。
这里为了更好的理解这些值,我们再尝试插入两条相同数据后发现,每次插入都生成了一个新的分区目录。同时,MinBlockNum和MaxBlockNum在自增。
![]()
由于MergeTree引擎对于分区的合并是不定时的,因此这里为了更快的尝试对分区进行合并后的结果,我们使用optimize命令强制合并分区
optimize table users final;
命令执行后,再去到上面的目录中观察,可以发现,多了一个202303_1_3_1的分区目录,也就是合并后的目录。这里的第一个1和3,表示MinBlockNum,MaxBlockNum,因为合并的3个分区中,MinBlockNum=1,MaxBlockNum=3。最后一个表示Level,也就是分区被合并的次数,由于只合并了一次,所以此时level=1。
![]()
通过实验与上面各参数说明中进行了一一对应。同时,过了一段时间后,其他的几个分区会被删除,只保留合并后的分区
![]()
文件结构
进入到上述的文件路径中,利用tree命令查看目录下的文件结构:
[root@linux121 202303_1_3_1]# tree
.
├── age.bin
├── age.mrk2
├── birthday.bin
├── birthday.mrk2
├── checksums.txt
├── columns.txt
├── count.txt
├── default_compression_codec.txt
├── minmax_birthday.idx
├── name.bin
├── name.mrk2
├── partition.dat
├── primary.idx
├── sex.bin
└── sex.mrk2
0 directories, 15 files
说明:
- checksums.txt: 校验文件,二进制存储了各文件的大小、哈希等,用于快速校验存储的正确性。
- columns.txt: 列名以及数据类型,本例该文件的内容为:
0 directories, 15 files
[root@linux121 202303_1_3_1]# cat columns.txt
columns format version: 1
4 columns:
`name` String
`sex` String
`age` Int8
`birthday` Date
-
count.txt: 记录数据的总行数,本例中文件内容为 2(只写入了两行数据)。
-
primary.idx: 主键索引文件,用于存放稀疏索引的数据。通过查询条件与稀疏索引能够快速的过滤无用的数据,减少需要加载的数据量。
-
{column}.bin: 实际列数据的存储文件,以
列名+bin为文件名,默认设置采用 lz4 压缩格式。每一列都会有单独的文件,此种方式为wide part模式。另外一种模式是compact part模式,这种模式下所有的列的数据放在一个文件data.bin里面。(新版本需要指定 SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0 参数来强制跳过 Compact format)。 -
{column}.mrk2: 列数据的标记信息,记录了数据块在 bin 文件中的偏移量。标记文件首先与列数据的存储文件对齐,记录了某个压缩块在 bin 文件中的相对位置;其次与索引文件对齐,记录了稀疏索引对应数据在列存储文件中的位置。clickhouse 将首先通过索引文件定位到标记信息,再根据标记信息直接从.bin 数据文件中读取数据。
-
Partition.dat: 保存一个值,就是partition的编号,从0开始。
[root@linux121 202303_1_3_1]# od -An -l partition.dat 202303 -
minmax_[Column].idx: minmax索引。用于记录当前分区下分区字段的最小最大值
二进制文件格式详解
在介绍了上述目录下的每个文件的功能和作用后,我们一起来看看上面各项文件中,具体存储了什么信息,以及如何去分析这些二进制文件。
在讲解之前,为了更好的看清文件内容,我们一共在users表中插入5条数据:
insert into test.users values ('zhangsan', 'female', 20, '2023-03-07');
insert into test.users values ('lisi', 'female', 22, '2023-03-06');
insert into test.users values ('lilei', 'female', 25, '2023-03-06');
insert into test.users values ('xiaoming', 'female', 27, '2023-03-09');
insert into test.users values ('yaya', 'female', 30, '2023-03-07');
SELECT *
FROM users
ORDER BY age DESC
Query id: ee21ad84-be21-47cf-92bd-55059d59fa6e
┌─name─┬─sex────┬─age─┬───birthday─┐
│ yaya │ female │ 30 │ 2023-03-07 │
└──────┴────────┴─────┴────────────┘
┌─name─────┬─sex────┬─age─┬───birthday─┐
│ xiaoming │ female │ 27 │ 2023-03-09 │
│ lilei │ female │ 25 │ 2023-03-06 │
│ lisi │ female │ 22 │ 2023-03-06 │
│ zhangsan │ female │ 20 │ 2023-03-07 │
└──────────┴────────┴─────┴────────────┘
5 rows in set. Elapsed: 0.002 sec.
-
primary.idx
MergeTree表会根据排序键生成primary.idx表,由users的建表语句可知,我们设置排序的键为age,同时index_granularity = 2。因此对应primary.idx中生成的记录应该为20、25、30三条记录。接下来,我们进入到primary.idx文件中,看下记录的内容是不是我们逻辑上分析的结果:
hexdump -C primary.idx 00000000 14 19 1e 1e |....| 00000004hexdump可以用来查看二进制文件的十六进制编码。由于定义的age Int8占用1个字节,因此上面的每一个16进制值应该对应于一个Age值。 对上面的十六进制结果做一下转换:
- 14(十六进制)->20(十进制)
- 19(十六进制)->25(十进制)
- 1e(十六进制)->30(十进制)
可以发现,转换成10进制后跟我们一开始的逻辑分析结果一致。证明了我们的猜想,更进一步核实了Clickhouse中primary.idx稀疏索引的原理。
-
{column}.mrk2
一个{column}.bin文件有1至多个数据压缩块组成,mark2数据标记文件格式比较固定,primary.idx文件中的每个索引在此文件中都有一个对应的Mark,有三列:
- Offset in compressed file,8 Bytes,代表该标记指向的压缩数据块在bin文件中的偏移量。
- Offset in decompressed block,8 Bytes,代表该标记指向的数据在解压数据块中的偏移量。
- Rows count,8 Bytes,行数,通常情况下其等于index_granularity。

因此,每一行mrk2文件共占用24 Bytes。所以通过primary.idx中的索引寻找mrk2文件中对应的Mark非常简单,如果要寻找第n(从0开始)个index,则对应的Mark在mrk2文件中的偏移为n*24,从这个偏移处开始读取24 Bytes即可得到相应的Mark。
age.mrk2
$ hexdump -C age.mrk2
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 02 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 |................|
00000040 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000060
$ od -An -l age.mrk2
0 0
2 0
2 2
0 4
1 0
5 0
分析下上面的文件内容。由于24 Bytes表示一行数据,因此从上面以每24位做切分,可以得到如下所示的表:
| 下标 | 压缩文件中的偏移量 | 解压文件中的偏移量 | 行数 |
|---|---|---|---|
| 0 | 0 | 0 | 2 |
| 1 | 0 | 2 | 2 |
| 2 | 0 | 4 | 1 |
| 3 | 0 | 0 | 0 |
从表中可以看出,解压文件中的偏移量对应的原表中的age值这与我们在primary.idx中分析出来的3个索引值一一对应。
-
index_granularity =2,且定义的age Int8占用1个字节,所以每两行对应一个索引,mrk2中也是没两行生成一条对应mark。
-
由于本次存储的数据 < 默认的压缩大小块64KB,因此所有的数据都在一个压缩块内,压缩文件中的偏移量都是0
-
由于最后一个mark对应的数据只有一条,所以最后一个行数为1
-
{column}.bin
{column}.bin文件由若干数据块组成,默认使用LZ4压缩格式,用于存储某一列数据。
一个压缩数据块由头信息和压缩数据两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。
如:0x821200065536
0x82:是压缩方法
12000:压缩后数据大小
65536:压缩前数据大小
{column}.bin文件存储如下:
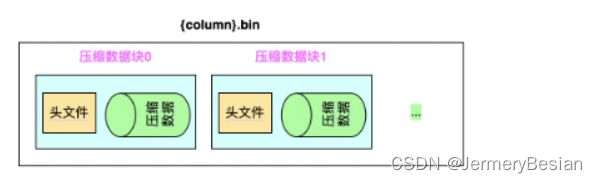
age.bin文件查看:
- 第一行16个字节是该文件的checksum值
- 第二行(以Id.bin为例)
- 第一个字节是0x82,是默认的LZ4算法
- 第2个到第5个字节是压缩后的数据块的大小,这里是小端模式,Int64占4个字节, 倒着就是 00 00 00 1f = 15
- 第6个字节到第9个字节是压缩前的数据块大小,同理00 00 00 05=5
- 与 clickhouse-compressor --stat < Id.bin得到的结果一致
- 第11~15个字节表示的数:14 16 19 1b 1e,就对应了表中age的22、22、25、27、30
$ hexdump -C age.bin
00000000 df 29 49 be ab 5f 11 25 36 3d 24 53 d0 e4 ff f5 |.)I.._.%6=$S....|
00000010 82 0f 00 00 00 05 00 00 00 50 14 16 19 1b 1e |.........P.....|
0000001f
$ clickhouse-compressor --stat <./age.bin | cat
5 15
这里可以发现,数据被压缩后的大小,反而大于压缩前的大小。这是因为我们测试的数据比较少,只有5条数据,而压缩时,还有一些必要的信息要压缩,所以压缩后会比压缩前大。
-
minmax_birthday.idx
minmax文件里面存放的是该分区里分区字段的最小最大值。分区字段birthday的类型为Date,其底层由UInt16实现,存的是从1970年1月1号到现在所经过的天数。通过上面的INSERT语句我们可以知道Birthday的最小值为2023-03-06,最大值为2023-03-09。这两个时间转换成天数分别为19422和19425,再转换成16进制就是0x4bde和0x4be1。
$ hexdump -C minmax_birthday.idx 00000000 de 4b e1 4b |.K.K| 00000004 $ od -An -td2 -w4 minmax_birthday.idx 19422 19425
这里,我们就逐一分析了primary.idx,{column}.mrk2,{column}.bin这三个主要文件包含的内容,可以更进一步的理解Clickhouse数据存储的基本原理。其他的文件也是类似的分析步骤,都比较简单了,就不再赘述。
索引过程
在对Clickhouse数据文件的结构和内容有过了解后,接下来探究基于这些数据文件利用索引来查询数据的过程。
通过上面对primary.idx和mrk2、bin文件的分析我们知道,对于每一个primary.idx中的索引,mrk2都有一条记录与之对应。而从mrk2中就可以找到bin文件中的压缩数据块和解压缩后的数据索引。
如果按照默认8192的索引粒度把数据分成批次,每批次读入数据的规则:
设x为批次数据的大小,
- 如果单批次获取的数据 x<64k,则继续读下一个批次,找到size>64k则生成下一个数据块
- 如果单批次数据64k
- 如果x>1M,则按照1M切分数据,剩下的数据继续按照上述规则执行。
查询过程
下图展示了一个大致的查询流程:
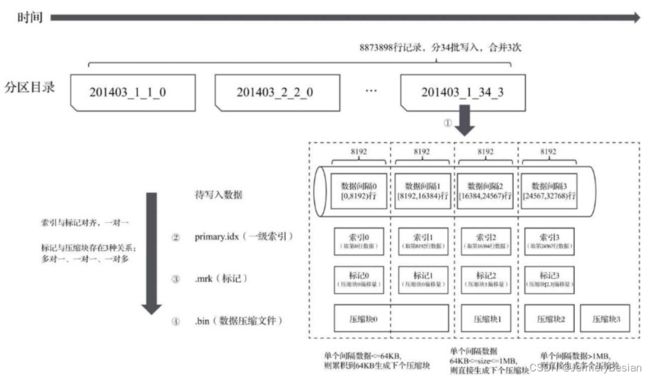
在MergeTree读取数据时,必须通过标记数据的位置信息找到所需要的数据。查找过程大致分为读取压缩数据块和读取数据两个步骤:
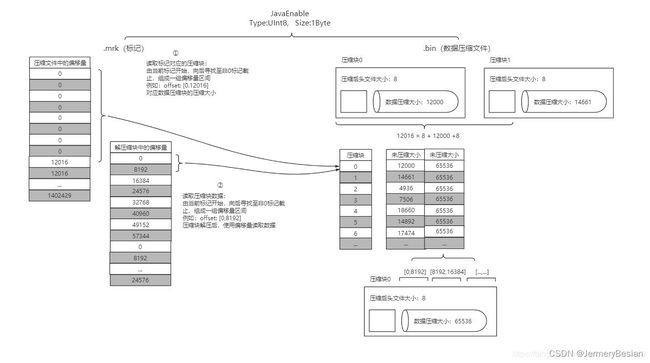
上图中,以JavaEnable字段说明:1 b * 8192 = 8192b 8192b * 8 = 64k,相当于8个8192条数据形成一个数据块。而第二个数据块的压缩文件的偏移量是从12016 Bytes开始的,原因是加上了两个数据块的头文件部分(假设第一个数据块压缩后的大小为12000Bytes),压缩后的头文件大小为8 Bytes,以此类推。而未压缩大小的65536大小则表示这里每一块数据块的大小都正好是64K大小。
有了mrk2,MergeTree在读取数据时并不需要将数据一次性加载到内存。定位压缩数据块并读取数据的过程:
- 读取压缩数据块:在查询某一列数据MergeTree无须一次性加载整个.bin文件。借助标记文件中的压缩文件偏移量加载指定的数据压缩块。
- 读取数据:解压后的数据,MergeTree并不需要一次性扫描整段解压数据,借住标记文件中保存的数据块中偏移量以index_granularity的粒度加载特定一小段
数据标记与压缩数据块的对应关系
- 一对一
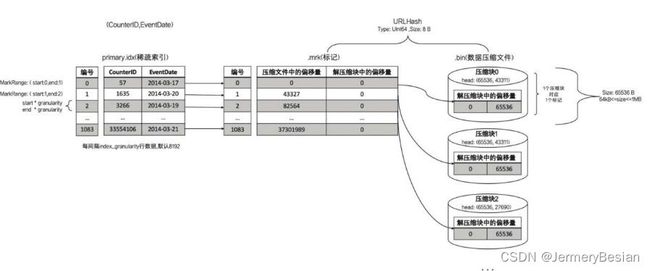
此时,每一个压缩数据块都是64KB。这里图中压缩数块中,头信息数组的前一个位置65536表示解压后的大小,第二个43311表示压缩后的大小。
- 多对一
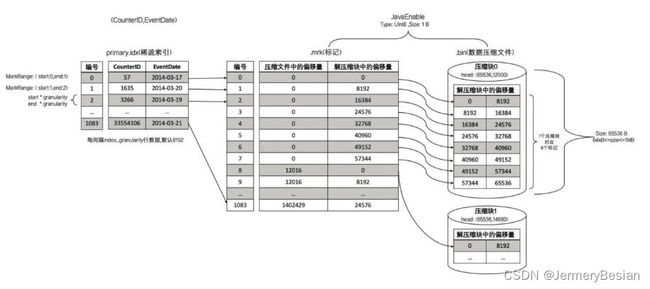
- 一对多
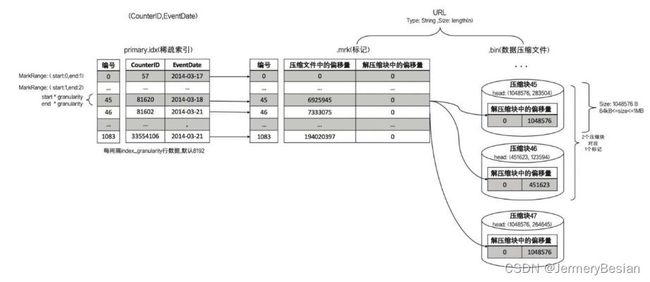
即mrk2中的一行对应两个压缩数据块中的数据。