clickhouse副本和分片
title: clickhouse副本和分片
date: 2021-02-20 16:48:02
categories: 数据库
tags: clickHouse
副本和分片是在很多分布式系统中都有,首先简单来看看他们的概念。
副本:数据结构相同,数据相同(数据层面的备份冗余)
分片:数据结构相同,数据不同。(数据量层面水平切分)

集群是副本和分片的基础,它将ClickHouse的服务拓扑由单节点延伸到多个节点,但它并不像Hadoop 生态的某些系统那样,要求所有节点组成一个单一的大集群。ClickHouse的集群配置非常灵活,用户既可以 将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。在每个小的集群区 域之间,它们的节点、分区和副本数量可以各不相同。
副本
在clickhouse中实现副本可以使用下面引擎系列
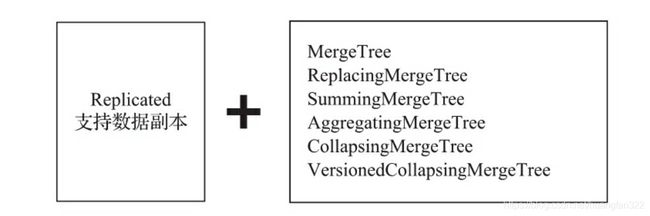
换言之,若使用了ReplicatedMergeTree复制表系列引擎,就能应用副本的能力(后面会介绍另一种副本的实现方式)。
ReplicatedMergeTree是MergeTree的派生引擎,它是依靠zookeeper监听节点实现副本在节点间的传输。
- zookeeper配置
首先,在服务器的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件
<yandex>
<!—ZooKeeper配置,名称自定义,一般就用这个名字就好 -->
<zookeeper-servers>
<node index="1">
<!—节点配置,可以配置多个地址-->
<host>127.0.0.1host>
<port>2181port>
node>
zookeeper-servers>
yandex>
接着,在全局配置config.xml中使用
<include_from>/etc/clickhouse-server/config.d/metrika.xmlinclude_from>
并引用ZooKeeper配置的定义 ,incl与metrika.xml配置文件内的节点名称要彼此对应
<zookeeper incl="zookeeper-servers" optional="false" />
在clickhouse中一切皆表,重启后会有一张zookeeper代理表,通过它可以查询zk内的数据
SELECT * FROM system.zookeeper where path = '/'
-
副本的定义
ReplicatedMergeTree 系列引擎
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')zk_path:用于指定在ZooKeeper中创建的数据表的路径,路径名称是自定义的,并没有固定规则,但是ck中一般约定俗成为/clickhouse/tables/{shard}/table_name- /clickhouse/tables/是约定俗成的路径固定前缀,表示存放数据表的根路径
- {shard}表示分片编号,通常用数值替代,例如01、02、03。一张数据表可以有多个分片,而每个分片都拥有自己的副本
- table_name表示数据表的名称,为了方便维护,通常与物理表的名字相同(也是不强制)
replica_name:作用是定义在ZooKeeper中创建的副本名称,该名 称是区分不同副本实例的唯一标识,一种约定成俗的命名方式是使用所在服务器的域名称。
例如:
//1分片,1副本. zk_path相同,replica_name不同
ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'linux01');
ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'linux02');
- 实践
// linux01
CREATE TABLE replicated_sales_1( id String,
price Float64,
create_time DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_1','linux01') PARTITION BY toYYYYMM(create_time)
ORDER BY id
// linux02
CREATE TABLE replicated_sales_1( id String,
price Float64,
create_time DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_1','linux01') PARTITION BY toYYYYMM(create_time)
ORDER BY id
这样后续在任何一个副本上执行INSERT、MERGE、MUTATION和ALTER操作都会影响另外一个副本。
- 实现原理
ReplicatedMergeTree能够实现副本的核心逻辑是使用了zk的能力。在执行INSERT数据写入、MERGE分区和MUTATION操作的时候,都会涉及与ZooKeeper的通信。在查询数据的时候也不会访问ZooKeeper,所以不必过于担 心ZooKeeper的承载压力。
上述linux01和linux02机器创建为例,大概步骤:
linux01
- 根据zk_path初始化所有的ZooKeeper节点。
- 在/replicas/节点下注册自己的副本实例linux01。
- 启动监听任务,监听/log日志节点。
- 参与副本选举,选举出主副本,选举的方式是向/leader_election/插入子节点,第一个插入成功的副本 就是主副本。
linux02
- 在/replicas/节点下注册自己的副本实例linux02。
- 启动监听任务,监听/log日志节点。
- 参与副本选举,选举出主副本。在这个例子中,linux01副本成为主副本。
后续操作任何一个节点,都会在zk上有对应的log目录,另外一个节点实时监控到log目录的变动,会动态拉取log日志,主动从主副本那里拉取数据更新自己。实际上可能会出现更新操作比较频繁,所以都是将任务放入到队列中,排队拉取更新。
分片
分片可以简单理解为是表结构相同,数据不同一系列表集合。这里就可以延伸出2个问题,写入时候怎么分配,查询时候如何合并结果集。在clickhouse中引入一个Distributed表引擎,充当读写门面,它作为分布式表的一层透明代理,在集群内部自动开展数 据的写入、分发、查询、路由等工作。
集群配置
Distributed表引擎需要读取集群的信息,所以首先必须为ClickHouse添加集群的配置。找到前面在 介绍ZooKeeper配置时增加的metrika.xml配置文件,在ClickHouse中,集群配置用shard代表分片、用replica代表副本。
语义的配置如下所示:
// 1分片、0副本
<shard>
<replica>
<!—副本 -->
replica>
shard>
// 1分片、1副本
<shard>
<replica>
<!—副本 -->
replica>
<replica>
<!—副本 -->
replica>
shard>
shard更像是逻辑层面的分组,而无论是副本还是分片,它们 的载体都是replica。
集群有两种配置形式:
1、不包含副本的分片
如果直接使用node标签定义分片节点,那么该集群将只包含分片,不包含副本。以下面的配置为例
// 2个分片、0个副本<yandex> <zookeeper-servers> <cluster1> <node> <host>linux01host> <port>9000port> node> <node> <host>linux02host> <port>9000port> node> cluster1> zookeeper-servers>yandex>
该配置定义了一个名为cluster1的集群,其包含了2个分片节点,它们分别指向了是linux01和linux02服务器。
现在分别对配置项进行说明:
- cluster1表示自定义的集群名称,全局唯一,是后续引用集群配置的唯一标识。在一个配置文件内,可以定义任意组集群。
- node用于定义分片节点,不包含副本。
- host指定部署了ClickHouse节点的服务器地址。
- port指定ClickHouse服务的TCP端口。
接下来介绍选填参数:
- weight分片权重默认为1,在后续小节中会对其详细介绍。
- user为ClickHouse用户,默认为default。
- password为ClickHouse的用户密码,默认为空字符串。
- secure为SSL连接的端口,默认为9440。
- compression表示是否开启数据压缩功能,默认为true。
2、自定义分片与副本
集群配置支持自定义分片和副本的数量,这种形式需要使用shard标签代替先前的node,除此之外的配 置完全相同。在这种自定义配置的方式下,分片和副本的数量完全交由配置者掌控。其中,shard表示逻辑 上的数据分片,而物理上的分片则用replica表示。如果在1个shard标签下定义N(N>=1)组replica,则该shard 的语义表示1个分片和N-1个副本。
- 不包含副本的分片
效果与先前介绍的cluster1集群相同.
// 2个分片、0个副本 <yandex> <zookeeper-servers> <cluster1> <shard> <replica> <host>linux01host> <port>9000port> replica> shard> <shard> <replica> <host>linux02host> <port>9000port> replica> shard> cluster1> zookeeper-servers>yandex>
- N个分片和N个副本
// 1个分片、1个副本 <yandex> <zookeeper-servers> <cluster1> <shard> <replica> <host>linux01host> <port>9000port> replica> <replica> <host>linux02host> <port>9000port> replica> shard> cluster1> zookeeper-servers>yandex>
**查询:**完成上述配置之后,可以查询系统表验证集群配置是否已被加载
SELECT cluster, host_name FROM system.clusters;
分布式DDL
在副本中,我们利用ReplicatedMergeTree操作副本表,需要登陆到2台机器上,分别操作,麻烦。在引入集群配置后,在ck中可以执行分布式DDL。
- 语法
// cluster_name对应了配置文件中的集群名称,这里也就是cluster1CREATE/DROP/RENAME/ALTER TABLE ON CLUSTER cluster_name
ReplicatedMergeTree中示例,可以替换成分布式DDL
// 一个分片,1个副本ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'linux01');ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'linux02');
CREATE TABLE test_1 ON CLUSTER cluster1( id String,price Float64,create_time DateTime) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_1','{replica}') PARTITION BY toYYYYMM(create_time)ORDER BY id
利用宏变量,用{shard}和{replica}两个动态宏变量代替了硬编码方式。具体是在config.xml配置变量
// linux01<macros> <shard>01shard> <replica>linux01replica>macros>// linux02<macros> <shard>02shard> <replica>linux02replica>macros>
- 原理
与ReplicatedMergeTree类似,分布式DDL语句在执行的过程中也需要借助ZooKeeper的协同能力,以实现日志分发。在默认情况下,分布式DDL在ZooKeeper内使用的根路径为:
/clickhouse/task_queue/ddl
该路径由config.xml内的distributed_ddl配置指定:
<distributed_ddl> <path>/clickhouse/task_queue/ddlpath>distributed_ddl>
Distributed引擎
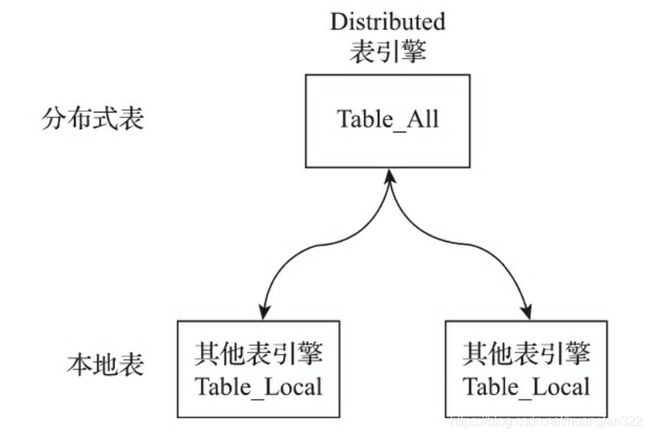
结构
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,而是作为数据分片的透明代理,能够 自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
-
本地表:通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引 擎,一张本地表对应了一个数据分片。_
-
分布式表:通常以_all为后缀进行命名。分布式表只能使用Distributed表引擎,它与本地表形成一对多 的映射关系,日后将通过分布式表代理操作多张本地表。
定义
ENGINE = Distributed(cluster, database, table [,sharding_key])
- cluster:集群名称,与集群配置中的自定义名称相对应。在对分布式表执行写入和查询的过程中,它会使用集群的配置信息来找到相应的host节点。
- database和table:分别对应数据库和表的名称,分布式表使用这组配置映射到本地表。
- sharding_key:分片键,选填参数。在数据写入的过程中,分布式表会依据分片键的规则,将数据分布 到各个host节点的本地表。
创建
Distributed表运用的是读时检查的机制,对创建分 布式表和本地表的顺序并没有强制要求。
CREATE TABLE test_shard_2_all ON CLUSTER sharding_simple ( id UInt64)ENGINE = Distributed(sharding_simple, default, test_shard_2_local,rand())CREATE TABLE test_shard_2_local ON CLUSTER sharding_simple ( id UInt64)ENGINE = MergeTree() ORDER BY idPARTITION BY id
操作影响
- INSERT和SELECT查询:Distributed将会以分布式的方式作用于local本 地表。
- CREATE、DROP、RENAME和ALTER:只会修改Distributed表自身,并不会修改local本地表。
分片规则
分片键要求返回一个整型类型的取值,包括Int系列和UInt系列。如果不声明分片键,那么分布式表只能包含一个分片,这意味着只能映射一张本地表,否则,在写入数据时将会异常。
--按照随机数划分Distributed(cluster, database, table ,rand())--按照用户id的散列值划分Distributed(cluster, database, table , intHash64(userid))
- 分片权重
在集群的配置中,有一项weight(分片权重)的设置:
<sharding_simple> <shard> <weight>10weight> ...... shard> <shard> <weight>20weight> ...... shard> ...
weight默认为1,虽然可以将它设置成任意整数,但官方建议应该尽可能设置成较小的值。分片权重会 影响数据在分片中的倾斜程度,一个分片权重值越大,那么它被写入的数据就会越多。
- slot(槽)
slot可以理解成许多小的水槽,如果把数据比作是水的话,那么数据之水会顺着这些水槽流进每个数据 分片。slot的数量等于所有分片的权重之和,假设集群cluter1有两个Shard分片,第一个分片的 weight为10,第二个分片的weight为20,那么slot的数量则等于30。slot按照权重元素的取值区间,与对应的分片形成映射关系。在这个示例中,如果slot值落在[0,10)区间,则对应第一个分片;如果slot值落在[10,20] 区间,则对应第二个分片。
- 选择函数
选择函数用于判断一行待写入的数据应该被写入哪个分片,整个判断过程大致分成两个步骤:
(1)它会找出slot的取值,其计算公式如下:
其中,shard_value是分片键的取值;sum_weight是所有分片的权重之和;slot等于shard_value和 sum_weight的余数。假设某一行数据的shard_value是10,sum_weight是30(两个分片,第一个分片权重为 10,第二个分片权重为20),那么slot值等于10(10%30=10)。
(2)基于slot值找到对应的数据分片。当slot值等于10的时候,它属于[10,20)区间,所以这行数据会对 应到第二个Shard分片。
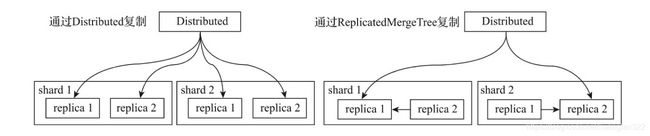
副本复制
如果在集群的配置中包含了副本,那么除了分片写入流程,还会触发副本数据的复制流程。数据在多个副本之间,有两种复制实现方式:
- 借助Distributed表引擎,由它将数据写入副本,Distributed节点需要同时负责分片和副本的写入
- 在集群的shard配置中增加internal_replication参数并将其设置为true(默认为false),那么 Distributed表在该shard中只会选择一个合适的replica并对其写入数据。此时,如果使用ReplicatedMergeTree 作为本地表的引擎,则在该shard内,多个replica副本之间的数据复制会交由ReplicatedMergeTree自己处理