TinyWebServer
遇到的问题
1. Reactor和Proactor
当下开源软件能做到网络高性能的原因就是 I/O 多路复用吗?
是的,基本是基于 I/O 多路复用,用过 I/O 多路复用接口写网络程序的同学,肯定知道是面向过程的方式写代码的,这样的开发的效率不高。
于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor 模式。
这里的反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
I/O 复用结合线程池,这就是 Reactor 模式基本设计思想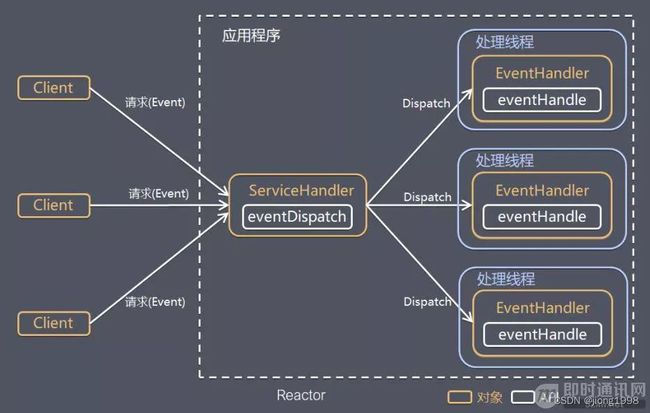
即 I/O 多了复用统一监听事件,收到事件后分发(Dispatch 给某进程),是编写高性能网络服务器的必备技术之一。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单 Reactor 单线程;
- 单 Reactor 多线程;
- 主从 Reactor 多线程。
具体的三种典型实现
1.1 单 Reactor 单线程
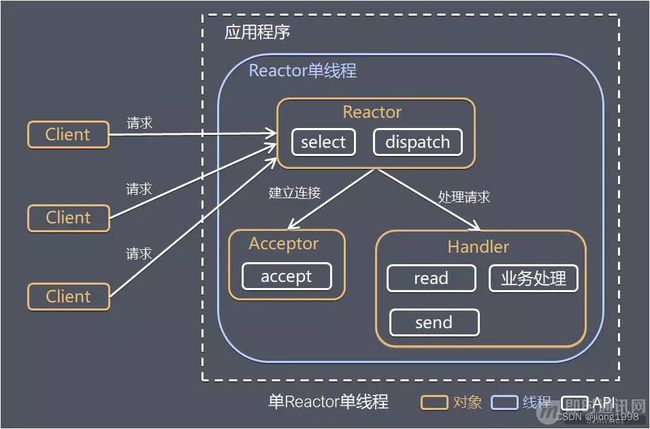
其中,Select 是前面 I/O 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个阻塞对象监听多路连接请求,其他方案示意图类似。
方案说明:
- Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发;
- 如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理;
- 如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应;
- Handler 会完成 Read→业务处理→Send 的完整业务流程。
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
可靠性问题,线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
使用场景:客户端的数量有限,业务处理非常快速,比如 Redis,业务处理的时间复杂度 O(1)。
1.2 单 Reactor 多线程
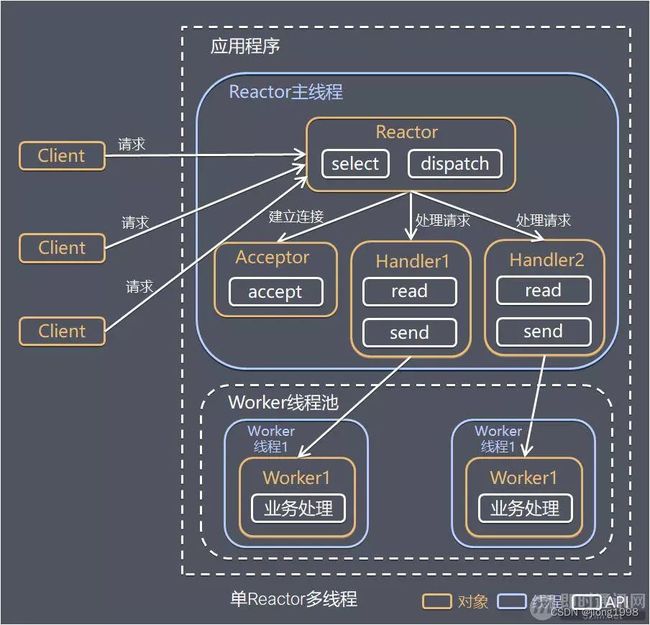
方案说明:
- Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发;
- 如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后续的各种事件;
- 如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应;
- Handler 只负责响应事件,不做具体业务处理,通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
- Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
- Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:可以充分利用多核 CPU 的处理能力。
缺点:多线程数据共享和访问比较复杂;Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
1.3 主从 Reactor 多线程
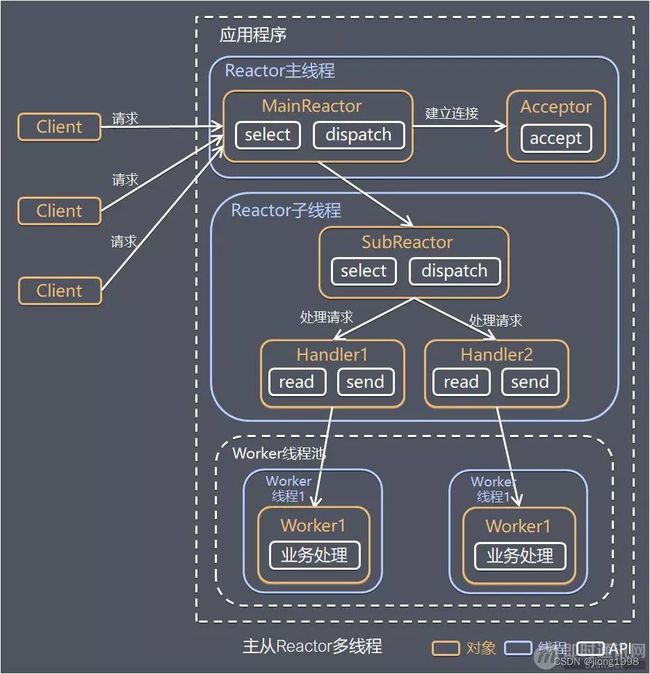
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
方案说明:
- Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件;
- Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理;
-
- SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件;
- 当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应;
- Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
- Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
- Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持。
参考:
https://blog.csdn.net/u013256816/article/details/115388239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166657834916800186537364%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=166657834916800186537364&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-2-115388239-null-null.142v59control,201v3control_1&utm_term=reactor&spm=1018.2226.3001.4187
2. epoll中epoll_ctl监控的事件额外补充
2.1 EPOLLSHOT的使用
EPOLLSHOT的作用主要用于多线程中
epoll在某次循环中唤醒一个事件,并用某个工作进程去处理该fd,此后如果不注册EPOLLSHOT,在该fd时间如果工作线程处理的不及时,主线程仍会唤醒这个事件,并另派线程池中另一个线程也来处理这个fd。
为了避免这种情况,需要在注册时间时加上EPOLLSHOT标志,EPOLLSHOT相当于说,某次循环中epoll_wait唤醒该事件fd后,就会从注册中删除该fd,也就是说以后不会epollfd的表格中将不会再有这个fd,也就不会出现多个线程同时处理一个fd的情况。处理完以后如果需要,要重新挂树。
2.2 EPOLLRDHUP的使用
在内核2.6.17(不含)以前版本,要想知道对端是否关闭socket,上层应用只能通过调用recv来判断是否为0才能知道,在2.6.17以后,这种场景上层只需要判断EPOLLRDHUP即可,无需在调用recv这个系统调用。
结论:
- 客户端直接调用close,会触犯EPOLLRDHUP事件
- 通过EPOLLRDHUP属性,来判断是否对端已经关闭,这样可以减少一次系统调用。在2.6.17的内核版本之前,只能再通过调用一次recv函数来判断
代码示例:
//服务器端
epoll_event event;
event.fd = connfd;
event.events = EPOLLIN | EPOLLET | EPOLLSHOT | EPOLLRDHUP;
epoll_ctl(epollfd, EPOLL_CTL_ADD, connfd, &events);
3. 为什么要使⽤线程池?
当你需要限制你应⽤程序中同时运⾏的线程数时,线程池⾮常有⽤。因为启动⼀个新线程会带来性能开销,每个线程也会为其堆栈分配⼀些内存 等。为了任务的并发执⾏,我们可以将这些任务任务传递到线程池,⽽不是为每个任务动态开启⼀个新的线程。
4. 怎么知道线程池的线程数量?
线程池中的线程数量最直接的限制因素是中央处理器(CPU)的处理器(processors/cores)的数量 N :如果你的CPU是4-cores的,对于CPU密集型 的任务(如视频剪辑等消耗CPU计算资源的任务)来说,那线程池中的线程数量最好也设置为4(或者+1防⽌其他因素造成的线程阻塞);对于 IO密集型的任务,⼀般要多于CPU的核数,因为线程间竞争的不是CPU的计算资源⽽是IO,IO的处理⼀般较慢,多于cores数的线程将为CPU 争取更多的任务,不⾄在线程处理IO的过程造成CPU空闲导致资源浪费,公式: 最佳线程数 = CPU当前可使⽤的Cores数 * 当前CPU的利⽤率 * (1 + CPU等待时间 / CPU处理时间) (还有回答⾥⾯提到的Amdahl准则可以了解⼀下)
5. http请求报文中get和post的区别
- 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
- GET请求参数会被完整保留在浏览器历史记录⾥,⽽POST中的参数不会被保留。
- GET请求在URL中传送的参数是有⻓度限制。(⼤多数)浏览器通常都会限制url⻓度在2K个字节,⽽(⼤多数)服务器最多处理64K⼤⼩的 url。
- GET产⽣⼀个TCP数据包;POST产⽣两个TCP数据包。对于GET⽅式的请求,浏览器会把http header和data⼀并发送出去,服务器响应200 (返回数据);⽽对于POST,浏览器先发送header,服务器响应100(指示信息—表示请求已接收,继续处理)continue,浏览器再发送 data,服务器响应200 ok(返回数据)。
6. 智能指针
7. pthread_create陷阱
如果把类的函数当作回调函数传入pthread_create会报错,编译不通过,原因是this指针会作为默认的参数被传进函数中。
所以要把类的成员函数当作回调函数时,需要设置为静态成员函数(静态成员函数没有this指针,但是静态成员函数只能访问静态成员变量)。
代码笔记
1. 使用了epoll为什么还要线程池?
这里,服务器通过epoll这种I/O复用技术(还有select和poll)来实现对监听socket(listenfd)和连接socket(客户请求)的同时监听。注意I/O复用虽然可以同时监听多个文件描述符,但是它本身是阻塞的,并且当有多个文件描述符同时就绪的时候,如果不采取额外措施,程序则只能按顺序处理其中就绪的每一个文件描述符,所以为提高效率,我们将在这部分通过线程池来实现并发(多线程并发),为每个就绪的文件描述符分配一个逻辑单元(线程)来处理。
2. 服务器程序需要处理的三类事件
服务器程序通常需要处理三类事件:I/O事件,信号及定时事件。有两种事件处理模式:
- Reactor模式:要求主线程(I/O处理单元)只负责监听⽂件描述符上是否有事件发⽣(可读、可写),若有,则⽴即通知⼯作线程(逻辑单 元),将socket可读可写事件放⼊请求队列,交给⼯作线程处理。
- Proactor模式:将所有的I/O操作都交给主线程和内核来处理(进⾏读、写),⼯作线程仅负责处理逻辑,如主线程读完成 后 users[sockfd].read() ,选择⼀个⼯作线程来处理客户请求 pool->append(users + sockfd) 。
3. 为什么⽤epoll
Linux下有三种IO复⽤⽅式:epoll,select和poll,为什么⽤epoll,它和其他两个有什么区别呢
- 对于select和poll来说,所有⽂件描述符都是在⽤户态被加⼊其⽂件描述符集合的,每次调⽤都需要将整个集合拷⻉到内核态;epoll则将整个 ⽂件描述符集合维护在内核态,每次添加⽂件描述符的时候都需要执⾏⼀个系统调⽤。
- select使⽤线性表描述⽂件描述符集合,⽂件描述符有上限;poll使⽤链表来描述;epoll底层通过红⿊树来描述,并且维护⼀个ready list,将 事件表中已经就绪的事件添加到这⾥,在使⽤epoll_wait调⽤时,仅观察这个list中有没有数据即可。
- select和poll的最⼤开销来⾃内核判断是否有⽂件描述符就绪这⼀过程:每次执⾏select或poll调⽤时,它们会采⽤遍历的⽅式,遍历整个⽂件 描述符集合去判断各个⽂件描述符是否有活动;epoll则不需要去以这种⽅式检查,当有活动产⽣时,会⾃动触发epoll回调函数通知epoll⽂件 描述符,然后内核将这些就绪的⽂件描述符放到之前提到的ready list中等待epoll_wait调⽤后被处理。
- select和poll都只能⼯作在相对低效的LT模式下,⽽epoll同时⽀持LT和ET模式。
4. EWOULDBLOCK作用
在使⽤ET模式时,必须要保证该⽂件描述符是⾮阻塞的(确保在没有数据可读时,该⽂件描述符不会⼀直阻塞);并且每次调⽤ read 和 write 的 时候都必须等到它们返回 EWOULDBLOCK (确保所有数据都已读完或写完)。
5. 主线程与工作线程的职责
主线程为异步线程,负责监听文件描述符,接收socket新连接,若当前监听的socket发生了读写事件,然后将任务插入到请求队列。工作线程从请求队列中取出任务,完成读写数据的处理。
6. 同步I/O模拟proactor模式
由于异步I/O并不成熟,实际中使用较少,这里将使用同步I/O模拟实现proactor模式。
同步I/O模型的工作流程如下(epoll_wait为例):
- 主线程往epoll内核事件表注册socket上的读就绪事件。
- 主线程调用epoll_wait等待socket上有数据可读
- 当socket上有数据可读,epoll_wait通知主线程,主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
- 主线程调用epoll_wait等待socket可写。
- 当socket上有数据可写,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
7. GET与POST的区别
注意:GET和POST的区别:
- 用户向搜索引擎搜关键字时,若使用的是POST的请求类型,会将搜索的内容写入实体体中,而不写入URL中
- 但是如果你使用的请求类型GET,则会把请求的URL中包含搜索的内容,不填入实体体中。
- GET产生一个TCP数据包;POST产生两个TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100(指示信息—表示请求已接收,继续处理)continue,浏览器再发送data,服务器响应200 ok(返回数据)。
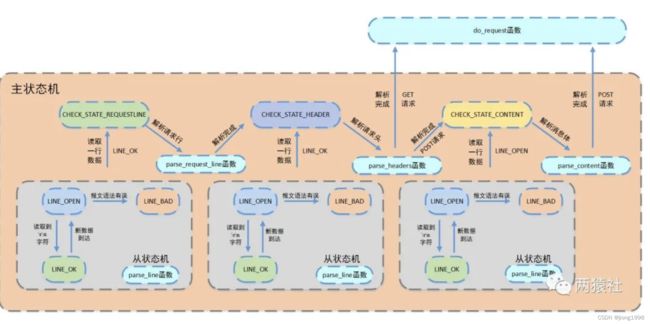
7. 状态机
7.1 状态机基本概念
项目中使用主从状态机的模式进行解析:
从状态机(parse_line)负责读取报文的一行,主状态机负责对该行数据进行解析,主状态机内部调用从状态机,从状态机驱动主状态机。每解析一部分都会将整个请求的m_check_state状态改变,状态机也就是根据这个状态来进行不同部分的解析跳转的:
其实就是自顶向下中学的状态机。
为什么在网络编程中需要状态机?因为写出大量的if else使得代码无比丑且高冗余
8. socketpair
socketpair是用来创建管道套接字。
在该项目中,创建管道是给信号事件使用的,然后可以把管道套接字也给epoll监控,使得信号事件与其他文件描述符都可以通过epoll来监测,从而实现统一处理。
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, m_pipefd);
8.1 socketpair函数介绍
socketpair()函数用于创建一对无名的、相互连接的套接子。
如果函数成功,则返回0,创建好的套接字分别是sv[0]和sv[1];否则返回-1,错误码保存于errno中。
函数原型:
- int socketpair(int d, int type, int protocol, int sv[2]);
函数参数:
- 参数1(domain):表示协议族,在Linux下只能为AF_LOCAL或者AF_UNIX。(自从Linux 2.6.27后也支持SOCK_NONBLOCK和SOCK_CLOEXEC)
- 参数2(type):表示协议,可以是SOCK_STREAM或者SOCK_DGRAM。SOCK_STREAM是基于TCP的,而SOCK_DGRAM是基于UDP的
- 参数3(protocol):表示类型,只能为0
- 参数4(sv[2]):套节字柄对,该两个句柄作用相同,均能进行读- 写双向操作
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
如何使用?
- 这对套接字可以用于全双工通信,每一个套接字既可以读也可以写。例如,可以往sv[0]中写,从sv[1]中读;或者从sv[1]中写,从sv[0]中读;
- 如果往一个套接字(如sv[0])中写入后,再从该套接字读时会阻塞,只能在另一个套接字中(sv[1])上读成功;
- 读、写操作可以位于同一个进程,也可以分别位于不同的进程,如父子进程。如果是父子进程时,一般会功能分离,一个进程用来读,一个用来写。因为文件描述副sv[0]和sv[1]是进程共享的,所以读的进程要关闭写描述符, 反之,写的进程关闭读描述符。
9. 连接池
连接池的功能主要有:初始化,获取连接、释放连接,销毁连接池
10. 线程所调用的函数 process() 详细解析
void http_conn::process()
{
HTTP_CODE read_ret = process_read();
if (read_ret == NO_REQUEST)
{
modfd(m_epollfd, m_sockfd, EPOLLIN);
return;
}
bool write_ret = process_write(read_ret);
if (!write_ret)
{
close_conn();
//这里是不是要关闭定时器
}
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}
- 先调用process_read()解析请求报文。会获取到客户到底是要做什么,接着process_read()内部会根据主状态机的状态调用de_request(),做具体的业务处理与分析(如注册,登陆等等)
- 接着根据服务器处理HTTP请求的结果,会调用process_write()进行响应报文(add_status_line、add_headers等函数)的生成。在生成响应报文的过程中主要调用add_reponse()函数更新m_write_idx和m_write_buf。
- 最后会回到主循环的最后一个事件 EPOLLOUT触发,将响应报文真正的发出。
11. http响应报文的笔记
1. iovec结构体的定义与使用
struct iovec 结构体定义了一个向量元素,通常这个 iovec 结构体用于一个多元素的数组(结构体数组),对于每一个元素,iovec 结构体的字段 iov_base 指向一个缓冲区,这个缓冲区存放的是网络接收的数据(read),或者网络将要发送的数据(write)。iovec 结构体的字段 iov_len 存放的是接收数据的最大长度(read),或者实际写入的数据长度(write)。
struct iovec {
/* Starting address (内存起始地址)*/
void *iov_base;
/* Number of bytes to transfer(这块内存长度) */
size_t iov_len;
};
在 linux 中,使用这样的结构体变量作为参数的函数很多,常见的包括:
#include 示例代码,向终端(屏幕)打印字符串:i am happy:
//iovec结构体的使用
#include2. writev/readv
因为使用read()将数据读到不连续的内存、使用write()将不连续的内存发送出去,要经过多次的调用read、write。
如果要从文件中将多块分散的内存数据写到文件描述符中,会有很多麻烦,并且会多次系统调用+拷贝会带来较大的开销。
所以UNIX提供了另外两个函数—readv()和writev(),它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。
writev函数用于在一次函数调用中写多个非连续缓冲区,有时也将这该函数称为聚集写。
writev以顺序iov[0],iov[1]至iov[iovcnt-1]从缓冲区中聚集输出数据。
- 函数原型
#include - 函数参数
- iov是关于iovec的结构体数组,看上一小节
- iovcnt是结构体数组的长度
- 返回值
- 成功:返回读取/写入的fd的字节数。
- 失败:返回-1;
12. 如何编译
编译:
g++ -o main -g main.cpp timer.cpp http_conn.cpp sql_pool.cpp -I./ -I/usr/include/mysql/ -L/usr/lib64/mysql/ -lmysqlclient -pthread
整体流程
主线程负责监听listenfd,接收新的连接。
浏览器端发出http连接请求,主线程创建http对象接收请求并将所有数据读入对应buffer,将该对象插入任务队列,工作线程从任务队列中取出一个任务进行处理。即,将发生读事件的http对象指针放入请求队列。
当connfd发生了读写事件,就把任务放入请求队列(注意: 请求队列只存放connfd的任务,不存放listenfd的任务),然后工作线程从请求队列中取出任务(注意,取出任务行为触及到锁操作,请求队列是一个共享资源),完成任务的处理。
http报文解析
线程池中的工作线程从任务队列中取出一个任务进行处理。
各子线程通过process函数对任务进行处理,调用process_read函数和process_write函数分别完成报文解析与报文响应两个任务
process_read详解:
注意,报文解析用到了状态机来解决的,状态机简单来说就是看状态调用不同的函数。
写项目时的琐碎小点总结
listenfd和connfd都设置成了ET/非阻塞。
connfd都加上了EPOLLONESHOT,所以每次事件发生后,都需要重新注册该事件(除了listenfd、信号)
epoll一共注册了三种事件:
- 连接listenfd
- 数据到来connfd
- 信号pipefd[0] (统一事件源)
- EPOLLOUT
- 异常事件(EPOLLRDHUP、EPOLLHUP、EPOLLERR)