### 入门案例
第一个:创建maven工程并导入坐标
第二个:创建实体类和dao接口
第三步:创建Mybatis的主配置文件
SqlMapConfig.xml
第四步:创建映射配置文件
IUserDao.xml
环境创建的注意事项:
第一个:
创建IUserDao.xml和IUserDao.java时名称是为了和我们之前的知识保持一致,在Mybatis中它把持久层的操作接口名称和映射文件也叫做:Mapper
第二个:
第三个:mybatis的映射配置文件位置必须和dao接口的包结构相同
第四个:映射配置文件mapper标签namespace属性的取值必须是dao接口的全限定类名。
第五个:映射配置文件的操作配置(select),id 属性的取值必须是dao接口的方法名。
**当我们遵从了第三,四,五点之后,我门在开发中就无须在写dao的实现类。**
##### MybatisTest
```java
public class MybatisTest {
@Test
public static void main(String[] args) throws Exception {
InputStream in= Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory=builder.build(in);
SqlSession session=factory.openSession();
IUserDao userDao=session.getMapper(IUserDao.class);
List
for(User user:users){
System.out.println(user);
}
session.close();
in.close();
}
}
```
##### IUserDao
```java
package com.itheima.dao;
import com.itheima.domain.User;
import java.util.List;
public interface IUserDao {
List
}
```
##### User.java
```java
package com.itheima.domain;
import java.io.Serializable;
import java.util.Date;
public class User implements Serializable {
private Integer id;
private String username;
private Date birthday;
private String sex;
private String address;
}
```
##### IUserDao.xml
```xml
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
select * from mybatis;
```
#####sqlMapConfig.xml
src/main/resources/sqlMapConfig.xml
```xml
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
```
##### pom.xml
```xml
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
```
### 注解实现案例
将IUserDao.xml删除
在IUserDao种使用注解
```java
public interface IUserDao {
@Select("select * from mybatis")
List
}
```
将sqlMapConfig中
将resource="com/itheima/dao/IUserDao.xml"改成class="com.itheima.dao.IUserDao"
```xml
```
### 自己写DAO实现类
UserDaoImpl.java实现类
```java
package com.itheima.dao.impl;
import com.itheima.dao.IUserDao;
import com.itheima.domain.User;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import java.util.List;
public class UserDaoImpl implements IUserDao {
private SqlSessionFactory factory;
public UserDaoImpl(SqlSessionFactory factory){
this.factory=factory;
}
public List
//使用工厂创建SqlSession对象
SqlSession session = factory.openSession();
//使用Sqlsession对象执行查询所有方法
List
session.close();
return list;
}
}
```
Test.java
```java
import com.itheima.dao.IUserDao;
import com.itheima.dao.impl.UserDaoImpl;
import com.itheima.domain.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class MybatisTest {
@Test
public static void main(String[] args) throws Exception {
//读取配置文件
InputStream in= Resources.getResourceAsStream("sqlMapConfig.xml");
//创建sqlsessionfactory工厂
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory=builder.build(in);
IUserDao userDao = new UserDaoImpl(factory);
/*
实现类做的工作定义了userDao的方法
SqlSession session=factory.openSession();
List
*/
//使用代理对象执行方法
List
//使用代理对象执行方法
for(User user:users){
System.out.println(user);
}
//释放资源
in.close();
}
}
```
mybatis允许我们自己来写实现类但是,**mybatis的通过映射机制为我们自动创建实现类,项目中完全不用自己创建。**
```java
List
```
实现类中的这句代码,让我们知道IUserDao.xml的namespace+id才能确定唯一的mysql语句,也就是那个dao(namespace)中的哪个方法(id)
### 案例分析
读配置文件
```cmd
InputStream in= Resources.getResourceAsStream("sqlMapConfig.xml");
```
> 读配置文件使用相对路径或者绝对路径都存在问题一般情况下都不使用
>
> 使用的方法主要有两种:
>
> 1.使用类加载器,它只能读取类路径的配置文件
>
> ```java
> //类加载器
> Properties pro =new Properties();
> pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
> ```
>
> 2.使用ServletContext对象的getRealPath(),获取项目部署的路径
>
> ```java
> //getRealPath()
> ServletContext context = this.getServletContext();
> String realPath = context.getRealPath("new.txt");
> ```
```cmd
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
```
### Mybatis分析
```xml
```
```xml
```
com/itheima/dao/IUserDao.xml
```xml
select * from mybatis
```
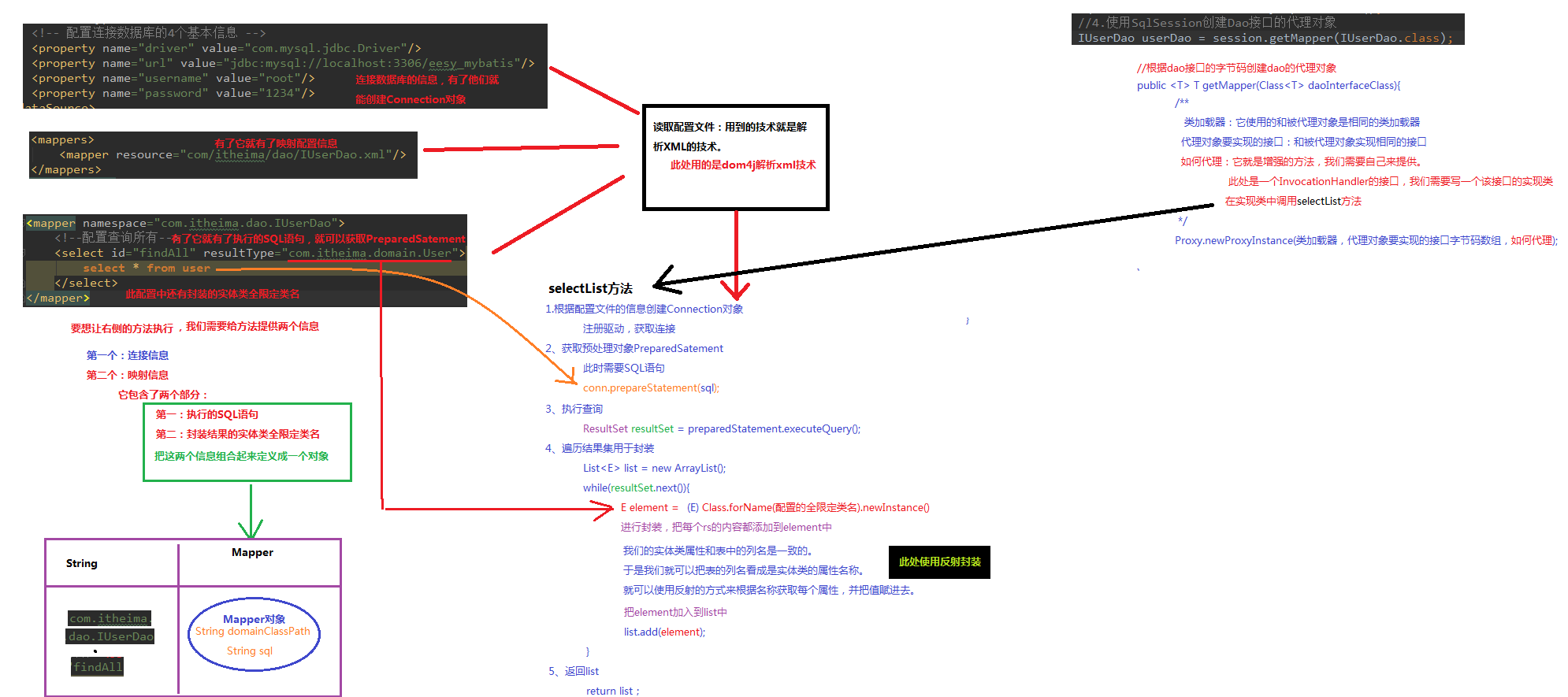
### CRUD
执行完插入数据操作,不会自动提交事务。
```cmd
DEBUG - Opening JDBC Connection
DEBUG - Created connection 2108763062.
DEBUG - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@7db12bb6]
DEBUG - ==> Preparing: insert into mybatis(username,birthday,sex,address) values(?,?,?,?)
DEBUG - ==> Parameters: newone(String), 2020-03-07 13:44:35.841(Timestamp), male(String), 北京1(String)
DEBUG - <== Updates: 1
DEBUG - Rolling back JDBC Connection <--[com.mysql.cj.jdbc.ConnectionImpl@7db12bb6]
DEBUG - Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@7db12bb6]
DEBUG - Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@7db12bb6]
DEBUG - Returned connection 2108763062 to pool.
```
需要添加一行代码
```java
session.commit();
```
结果为
```
DEBUG - Opening JDBC Connection
DEBUG - Created connection 760357227.
DEBUG - Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2d52216b]
DEBUG - ==> Preparing: insert into mybatis(username,birthday,sex,address) values(?,?,?,?)
DEBUG - ==> Parameters: newone(String), 2020-03-07 13:48:38.379(Timestamp), male(String), 北京1(String)
DEBUG - <== Updates: 1
DEBUG - Committing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2d52216b]
DEBUG - Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2d52216b]
DEBUG - Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2d52216b]
DEBUG - Returned connection 760357227 to pool.
```
补充:
[Mybatis的SqlSession运行原理](https://www.cnblogs.com/jian0110/p/9452592.html)
SqlSession是Mybatis最重要的构建之一,可以简单的认为Mybatis一系列的配置目的是生成类似 JDBC生成的Connection对象的SqlSession对象,这样才能与数据库开启“沟通”,通过SqlSession可以实现增删改查(当然现在更加推荐是使用Mapper接口形式)
Mybatis:
```java
SqlSession session=factory.openSession();
//使用Mapper接口
IUserDao userDao=session.getMapper(IUserDao.class);
List
```
自己写实现类:
```JAVA
SqlSession session = factory.openSession();
//使用Sqlsession对象执行查询所有方法,直接使用Sqlsession
List
session.close();
```
JDBC:
```java
Class.forName("com.mysql.cj.jdbc.Driver");
//3.获取数据库连接
Connection conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/mydate?serverTimezone=UTC","root","root");
//4.定义sql语句
String sql="delete from student2 where id =1";
//5.获取执行sql语句的对象statement
Statement stmt=conn.createStatement();
//6.执行sql,接受返回结果
int count=stmt.executeUpdate(sql);
//7.处理结果
System.out.println(count);
//8.释放资源
stmt.close();
conn.close();
```
### Mybatis的参数深入
我们在上一章节中已经介绍了SQL语句传参,使用标签的parameterType属性来设定。该属性的取值可以是基本类型,引用类型(例如:String类型),还可以是实体类类型(POJO类)。同时也可以使用实体类的包装类,本章节将介绍如何使用实体类的包装类作为参数传递。
基本类型和String我们可以直接写类型名称,也可以使用包名.类名的方式,例如:java.lang.String。 实体类类型,目前我们只能使用全限定类名。 究其原因,是mybaits在加载时已经把常用的数据类型注册了别名,从而我们在使用时可以不写包名,而我们的是实体类并没有注册别名,所以必须写全限定类名。在今天课程的最后一个章节中将讲解如何注册实体类的别名.
**POJO**(Plain Ordinary Java Object)简单的Java对象,实际就是普通JavaBeans,是为了避免和EJB混淆所创造的简称。
使用POJO名称是为了避免和[EJB](https://baike.baidu.com/item/EJB)混淆起来, 而且简称比较直接. 其中有一些属性及其getter setter方法的类,没有业务逻辑,有时可以作为[VO](https://baike.baidu.com/item/VO)(value -object)或[dto](https://baike.baidu.com/item/dto/16016821)(Data Transform Object)来使用.当然,如果你有一个简单的运算属性也是可以的,但不允许有业务方法,也不能携带有connection之类的方法。
**OGNL** *对象导航图语言* 是Object-Graph Navigation Language的缩写,它是一种功能强大的表达式语言,通过它简单一致的表达式语法,可以存取对象的任意属性,调用对象的方法,遍历整个对象的结构图,实现字段类型转化等功能。它使用相同的表达式去存取对象的属性。这样可以更好的取得数据。

直接使用birthday就获取了domain.User对象的birthday参数相当于调用了user.getBirthday()
OGNL可以让我们用非常简单的表达式访问对象层,例如,当前环境的根对象为user1,则表达式person.address[0].province可以访问到user1的person属性的第一个address的province属性。
### Mybatis中的返回值深入-解决实体类属性和数据库列名不对应的两种方式
为了解决查询结果的列名和实体类的属性名对应不上的问题
可以在查询数据库的时候对查询数据起别名。

或者在mybatis中进行配置resultMap
#### resultMap
```xml
select * from mybatis;
```
### mybatis配置的设置
properties中可以用属性名resource=加载路径
```xml
属性值中同样可以使用url来引用配置文件
```
```xml
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
```
### 别名:typeAliases标签和package属性
```xml
```
```xml
```
### Mybatis连接池pool
> 我们在前面的WEB课程中也学习过类似的连接池技术,而在Mybatis中也有连接池技术,但是它采用的是自己的连接池技术。在Mybatis的SqlMapConfig.xml配置文件中,通过
容器其实就是一个集合对象,该集合必须是线程安全的,不能两个线程拿到同一个连接,集合还必须实现队列的特性,先进先出。
#### 连接池类型
SqlMapConfig.xml中的dataSource标签type就是连接池的属性
**type的取值**
POOLED 使用连接池的数据源
UNPOOLED 不使用连接池的数据源 ,采用传统的获取连接的方式,虽然也实现了Javax.sql.DataSource接口,但是并没有使用池的思想。
JNDI采用服务器提供的JNDI技术实现,来获取DataSource对象,不同的是服务器所能拿到的DataSource不一样
> MyBatis在初始化时,根据
>
> type=”POOLED”:MyBatis会创建PooledDataSource实例
>
> type=”UNPOOLED” : MyBatis会创建UnpooledDataSource实例
>
> type=”JNDI”:MyBatis会从JNDI服务上查找DataSource实例,然后返回使用
注意:如果不是web或者maven的war工程,是不能使用的。tomcat服务器,采用的连接池就是dbcp连接池
```xml
```
运行结果
```cmd
DEBUG - ==> Preparing: select * from mybatis;
DEBUG - ==> Parameters:
DEBUG - <== Total: 10
DEBUG - Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@543295b0]
DEBUG - Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@543295b0]
DEBUG - Returned connection 1412601264 to pool.《--归还连接到连接池》
```
#### Mybatis中DataSource的存取
MyBatis是通过工厂模式来创建数据源DataSource对象的,MyBatis定义了抽象的工厂接口:org.apache.ibatis.datasource.DataSourceFactory,通过其getDataSource()方法返回数据源DataSource。
下面是DataSourceFactory源码,具体如下:
```java
package org.apache.ibatis.datasource;
import java.util.Properties;import javax.sql.DataSource;
public interface DataSourceFactory {
void setProperties(Properties props);
DataSource getDataSource();
}
```
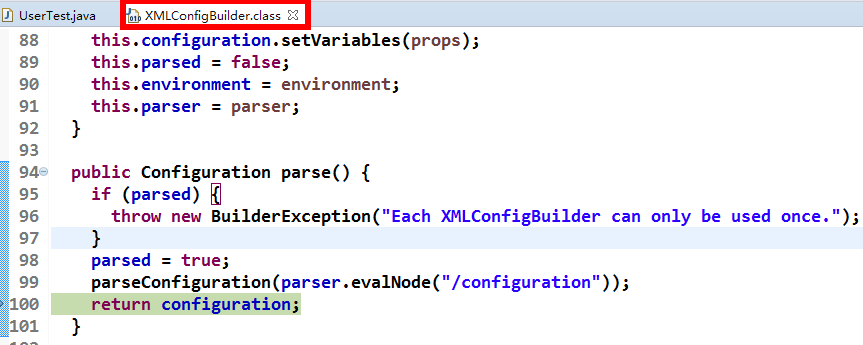
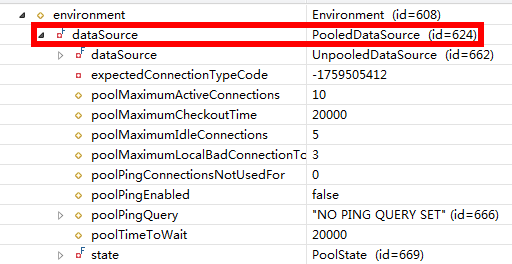
MyBatis创建了DataSource实例后,会将其放到Configuration对象内的Environment对象中, 供以后使用。 具体分析过程如下:
1.先进入XMLConfigBuilder类中,可以找到如下代码
2.分析configuration对象的environment属性,结果如下:
#### Mybatis中连接的获取过程分析
```
当我们需要创建SqlSession对象并需要执行SQL语句时,这时候MyBatis才会去调用dataSource对象来创建java.sql.Connection对象。也就是说,java.sql.Connection对象的创建一直延迟到执行SQL语句的时候。
@Test
public void testSql() throws Exception {
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
SqlSession sqlSession = factory.openSession();
List
System.out.println(list.size());
}
只有当第4句sqlSession.selectList("findUserById"),才会触发MyBatis在底层执行下面这个方法来创建java.sql.Connection对象。 如何证明它的加载过程呢? 我们可以通过断点调试,在PooledDataSource中找到如下popConnection()方法,如下所示: 分析
分析源代码,得出PooledDataSource工作原理如下:
```
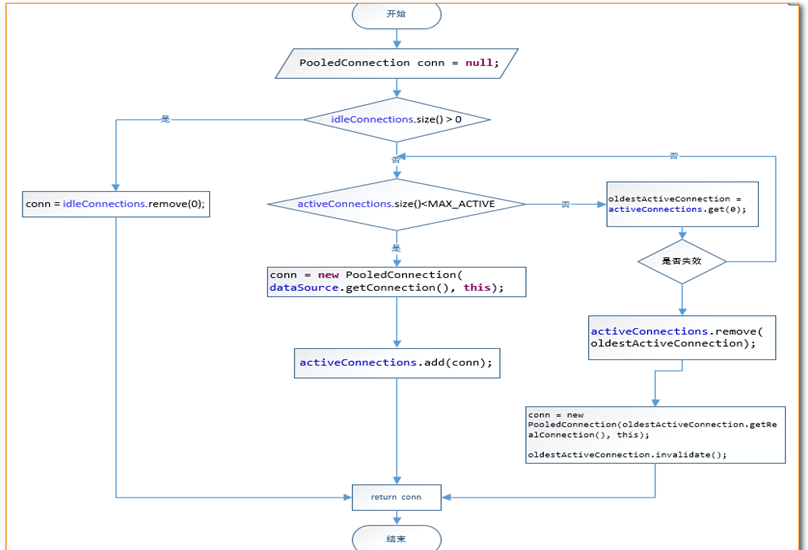
#### 事务提交
为什么CUD过程中必须使用sqlSession.commit()提交事务?主要原因就是在连接池中取出的连接,都会将调用connection.setAutoCommit(false)方法,这样我们就必须使用sqlSession.commit()方法,相当于使用了JDBC中的connection.commit()方法实现事务提交。
在创建session对象的时候采用openSession()
明白这一点后,我们现在一起尝试不进行手动提交,一样实现CUD操作。
```java
@Before//在测试方法执行之前执行
public void init()throws Exception{
//1.读取配置文件
in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.创建构建者对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//3.创建SqlSession工厂对象
factory = builder.build(in);
//4.创建SqlSession对象
session = factory.openSession(true);
//5.创建Dao的代理对象
userDao = session.getMapper(IUserDao.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws Exception{
//7.释放资源
session.close();
in.close();
}
所对应的DefaultSqlSessionFactory类的源代码:
```

```java
public class DefaultSqlSessionFactory implements SqlSessionFactory {
private final Configuration configuration;
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration = configuration;
}
public SqlSession openSession() {
return this.openSessionFromDataSource(this.configuration.getDefaultExecutorType(), (TransactionIsolationLevel)null, false);
}
public SqlSession openSession(boolean autoCommit) {//这里设置为true即可实现事务的自动提交
return this.openSessionFromDataSource(this.configuration.getDefaultExecutorType(), (TransactionIsolationLevel)null, autoCommit);
}
```
### Mybatis的动态SQL语句
Mybatis的映射文件中,前面我们的SQL都是比较简单的,有些时候业务逻辑复杂时,我们的SQL是动态变化的,此时在前面的学习中我们的SQL就不能满足要求了。
##### < if>标签
我们根据实体类的不同取值,使用不同的SQL语句来进行查询。比如在id如果不为空时可以根据id查询,如果username不同空时还要加入用户名作为条件。这种情况在我们的多条件组合查询中经常会碰到。
```xml
select * from mybatis where 1=1
and username like #{username}
and address like #{address}
```
注意:
```java
select * from mybatis where and username like #{username}
```
```java
@Test
public void testFindByUser() {
User u = new User(); u.setUsername("%王%");
u.setAddress("%顺义%");
//6.执行操作
List
for(User user : users) {
System.out.println(user);
}
}
```
##### where标签
```xml
select * from mybatis
and username like #{username}
and address like #{address}
```
##### < foreach>标签
传入多个id查询用户信息,用下边两个sql实现:
```java
SELECT * FROM USERS WHERE username LIKE '%张%' AND (id =10 OR id =89 OR id=16)
SELECT * FROM USERS WHERE username LIKE '%张%' AND id IN (10,89,16)
```
QueryVo1.java
```java
package domain;
import java.io.Serializable;
import java.util.List;
public class QueryVo1 implements Serializable {
private List
public List
return ids;
}
public void setIds(List
this.ids = ids;
}
}
```
```xml
select * from mybatis
#{i}
```
测试:
```java
@Test
public void testfindInIds(){
QueryVo1 vo1 = new QueryVo1();
List
ids.add(8);
ids.add(9);
ids.add(10);
ids.add(14);
vo1.setIds(ids);
List
System.out.println(inIds);
```
拼接sql语句
```cmd
DEBUG - ==> Preparing: select * from mybatis WHERE id in ( ? , ? , ? , ? )
DEBUG - ==> Parameters: 8(Integer), 9(Integer), 10(Integer), 14(Integer)
DEBUG - <== Total: 4
```
### Mybatis中简化编写的SQL片段
定义代码片段
```xml
```
引用代码片段
```xml
#{item}
```
# 多表查询
## 一对一
account表和user表
想要查询account信息且对应的包含user信息
```
public class Account implements Serializable {
```
方式一:名称直接对应
方式二:使用resultMap
```xml
select a.*,u.username,u.address from account a,user u where a.uid =u.id;
```
## 多对多
> Role.java
```java
package com.itheima.domain;
import java.io.Serializable;
import java.util.List;
/**
* @author 黑马程序员
* @Company http://www.ithiema.com
*/
public class Role implements Serializable {
private Integer roleId;
private String roleName;
private String roleDesc;
//多对多的关系映射:一个角色可以赋予多个用户
}
```
> IRoleDao.xml
```xml
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
select u.*,r.id as rid,r.role_name,r.role_desc from role r
left outer join user_role ur on r.id = ur.rid
left outer join user u on u.id = ur.uid
```
> RoleTest.java
```java
package com.itheima.test;
import com.itheima.dao.IRoleDao;
import com.itheima.domain.Role;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
/**
* @author 黑马程序员
* @Company http://www.ithiema.com
*/
public class RoleTest {
private InputStream in;
private SqlSession sqlSession;
private IRoleDao roleDao;
@Before//用于在测试方法执行之前执行
public void init()throws Exception{
//1.读取配置文件,生成字节输入流
in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.获取SqlSessionFactory
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
//3.获取SqlSession对象
sqlSession = factory.openSession(true);
//4.获取dao的代理对象
roleDao = sqlSession.getMapper(IRoleDao.class);
}
@After//用于在测试方法执行之后执行
public void destroy()throws Exception{
//提交事务
// sqlSession.commit();
//6.释放资源
sqlSession.close();
in.close();
}
/**
* 测试查询所有
*/
@Test
public void testFindAll(){
List
for(Role role : roles){
System.out.println("---每个角色的信息----");
System.out.println(role);
System.out.println(role.getUsers());
}
}
}
```
# 延迟加载
通过前面的学习,我们已经掌握了Mybatis中一对一,一对多,多对多关系的配置及实现,可以实现对象的关联查询。实际开发过程中很多时候我们并不需要总是在加载用户信息时就一定要加载他的账户信息。此时就是我们所说的延迟加载
> 延迟加载: 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载.
>
> 好处:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
>
> 坏处: 因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗时间,所以可能造成用户等待时间变长,造成用户体验下降。
实现:
我们使用了resultMap来实现一对一,一对多,多对多关系的操作。主要是通过association、collection实现一对一及一对多映射。association、collection具备延迟加载功能。
## 一对一的延迟加载
```java
package domain;
import java.io.Serializable;
public class Account implements Serializable {
private Integer id;
private Integer uid;
private Double money;
//单个User不是User的集合
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
...
}
```
添加配置信息到SqlMapConfig.xml
```xml
```
**使用association实现延迟加载**
```xml
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
select * from account
select * from user where id = #{uid}
```
测试类
```java
public void test() throws Exception {
List
}
```
结果
```cmd
DEBUG - ==> Preparing: select * from account
DEBUG - ==> Parameters:
DEBUG - <== Total: 8
```
> 这里没有查询User, 当我们使用打印account时就会自动查询User属性
## 一对多的延迟加载
```java
public class User implements Serializable {
private Integer id;
private String username;
private Date birthday;
private String address;
private String sex;
private List
public List
return accountList;
}
...
}
```
**使用collection实现延迟加载**
```xml
select * from user
select * from account where uid=#{id}
```
测试类
```java
@Test
public void testFindAccountByUserId(){
List
for(User i:allUser){
System.out.println("user:"+i.getId()+"账户-----------------------------------");
List
for(Account j:accountList){
System.out.println("账户id"+j.getId());
System.out.println("账户所属user"+j.getUser().getId());
}
}
}
```
# Mybatis中的缓存
什么是缓存
存在于内存中的临时数据。
为什么使用缓存
减少和数据库的交互次数,提高执行效率。
什么样的数据能使用缓存,什么样的数据不能使用
适用于缓存:
经常查询并且不经常改变的。
数据的正确与否对最终结果影响不大的。
不适用于缓存:
经常改变的数据
数据的正确与否对最终结果影响很大的。
例如:商品的库存,银行的汇率,股市的牌价。
Mybatis中的一级缓存和二级缓存
> 像大多数的持久化框架一样,Mybatis也提供了缓存策略,通过缓存策略来减少数据库的查询次数,从而提高性能。 Mybatis中缓存分为一级缓存,二级缓存。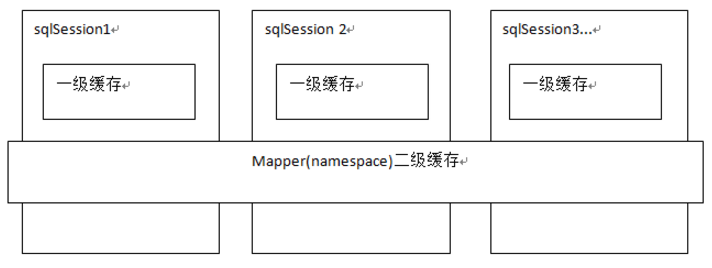
## 一级缓存:
它指的是Mybatis中SqlSession对象的缓存。
当我们执行查询之后,查询的结果会同时存入到SqlSession为我们提供一块区域中。
该区域的结构是一个Map。当我们再次查询同样的数据,mybatis会先去sqlsession中
查询是否有,有的话直接拿出来用。
当SqlSession对象消失时,mybatis的一级缓存也就消失了。
```java
SqlSession session1 = factory.openSession();
IUserDao mapper1=session1.getMapper(IUserDao.class);
List
System.out.println(byId);
List
System.out.println(byId2);
session1.close();
is.close();
```
结果:同一个Session查询了2次但查询数据库1次
```cmd
DEBUG - ==> Preparing: select * from user where id = ?
DEBUG - ==> Parameters: 14(Integer)
DEBUG - <== Total: 1
[User{id=14, username='newone', birthday=Sat Mar 07 08:00:00 CST 2020, address='北京1', sex='male'}]
[User{id=14, username='newone', birthday=Sat Mar 07 08:00:00 CST 2020, address='北京1', sex='male'}]
```
**分析**
一级缓存是SqlSession范围的缓存,当调用SqlSession的修改,添加,删除,commit(),close()等方法时,就会清空一级缓存。
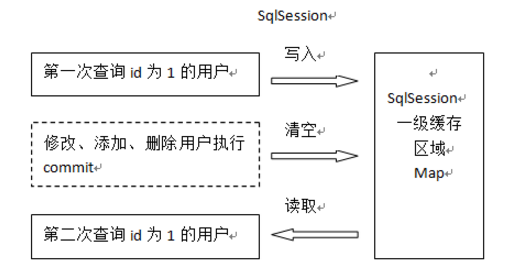
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
```java
@Test
public void testSecondLevelCache(){
SqlSession session1 = factory.openSession();
IUserDao mapper1=session1.getMapper(IUserDao.class);
User user1 = mapper1.findById(14);
System.out.println(user1);
User user16 = mapper1.findById(16);
//session.close()或者session.clearCache()都会请理缓存
//2.更新用户信息
user16.setUsername("update user clear cache");
user16.setAddress("北京市海淀区");
mapper1.updateUser(user16);
//3.再次查询id为14的用户
User user2 = mapper1.findById(14);
System.out.println(user2);
System.out.println(user1 == user2);
}
```
## 二级缓存:
它指的是Mybatis中SqlSessionFactory对象的缓存。由同一个SqlSessionFactory对象创建的SqlSession共享其缓存。
二级缓存的使用步骤:
第一步:让Mybatis框架支持二级缓存(在SqlMapConfig.xml中配置)
```xml
因为cacheEnabled的取值默认就为true,所以这一步可以省略不配置。为true代表开启二级缓存;为false代表不开启二级缓存
```
第二步:让当前的映射文件支持二级缓存(在IUserDao.xml中配置)
```xml
```
第三步:让当前的操作支持二级缓存(在select标签中配置)
```xml
select * from user where id = #{uid}
将UserDao.xml映射文件中的
注意:针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存。
```
**分析:**
二级缓存是mapper映射级别的缓存,多个SqlSession去操作同一个Mapper映射的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
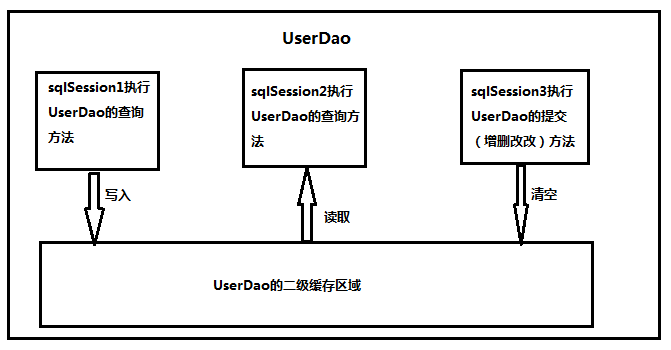
sqlSession1去查询用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果SqlSession3去执行相同 mapper映射下sql,执行commit提交,将会清空该 mapper映射下的二级缓存区域的数据。
sqlSession2去查询与sqlSession1相同的用户信息,首先会去缓存中找是否存在数据,如果存在直接从缓存中取出数据
```java
@Test
public void testSecondLevelCache(){
SqlSession sqlSession1 = factory.openSession();
IUserDao dao1 = sqlSession1.getMapper(IUserDao.class);
User user1 = dao1.findById(14);
System.out.println(user1);
sqlSession1.close();//一级缓存消失
SqlSession sqlSession2 = factory.openSession();
IUserDao dao2 = sqlSession2.getMapper(IUserDao.class);
User user2 = dao2.findById(14);//先查询二级缓存
System.out.println(user2);
sqlSession2.close();
}
}
```
# 注解开发
## 常见的注解
@Insert:实现新增
@Update:实现更新
@Delete:实现删除
@Select:实现查询
@Result:实现结果集封装
@Results:可以与@Result一起使用,封装多个结果集
@ResultMap:实现引用
@Results定义的封装
@One:实现一对一结果集封装
@Many:实现一对多结果集封装
@SelectProvider: 实现动态SQL映射
@CacheNamespace:实现注解二级缓存的使用
## CRUD
DAO接口
```java
public interface IUserDao {
/**
* 查询所有用户
* @return
*/
@Select("select * from user")
List
/**
* 保存用户
* @param user
*/
@Insert("insert into user(username,address,sex,birthday)values(#{username},#{address},#{sex},#{birthday})")
void saveUser(User user);
/**
* 更新用户
* @param user
*/
@Update("update user set username=#{username},sex=#{sex},birthday=#{birthday},address=#{address} where id=#{id}")
void updateUser(User user);
/**
* 删除用户
* @param userId
*/
@Delete("delete from user where id=#{id} ")
void deleteUser(Integer userId);
/**
* 根据id查询用户
* @param userId
* @return
*/
@Select("select * from user where id=#{id} ")
User findById(Integer userId);
/**
* 根据用户名称模糊查询
* @param username
* @return
*/
// @Select("select * from user where username like #{username} ")
@Select("select * from user where username like '%${value}%' ")
List
/**
* 查询总用户数量
* @return
*/
@Select("select count(*) from user ")
int findTotalUser();
}
```
注意:注解开发的时候resource相同文件路径下不能有对应的xml文件 不然报错
## 实体类属性和数据库类名的对应关系
基于注解的一对一
```java
@Select("select * from account")
@Results(id="accountMap",value = {
@Result(id=true,column = "id",property = "id"),
@Result(column = "uid",property = "uid"),
@Result(column = "money",property = "money"),
@Result(property = "user",column = "uid", one=@One(select="com.itheima.dao.IUserDao.findById",fetchType= FetchType.EAGER))
})
List
@Select("select * from user where id=#{id}")
@ResultMap("userMap")
User findById(Integer userId);
```
基于注解的一对多
```java
@Select("select * from user")
@Results(id="userMap",value={
@Result(id=true,column = "id",property = "userId"),
@Result(column = "username",property = "userName"),
@Result(column = "address",property = "userAddress"),
@Result(column = "sex",property = "userSex"),
@Result(column = "birthday",property = "userBirthday"),
@Result(column = "id",property = "accounts",
many = @Many(select = "com.itheima.dao.IAccountDao.findAccountByUid",
fetchType = FetchType.LAZY))
})
List
@Select("select * from account where uid = #{userId}")
List
```
## 基于注解的一级缓存和二级缓存
注解的默认带有一级缓存 使用方法与基于xml形式一样
### 二级缓存
1. 现在sqlMapConfig.xml中添加
```
```
2.在dao上添加注解@CacheNamespace(blocking = true)
```java
@CacheNamespace(blocking = true)
public interface IUserDao {
```
测试类
```java
public class SecondLevelCatchTest {
private InputStream in;
private SqlSessionFactory factory;
@Before
public void init()throws Exception{
in = Resources.getResourceAsStream("SqlMapConfig.xml");
factory = new SqlSessionFactoryBuilder().build(in);
}
@After
public void destroy()throws Exception{
in.close();
}
@Test
public void testFindOne(){
SqlSession session = factory.openSession();
IUserDao userDao = session.getMapper(IUserDao.class);
User user = userDao.findById(57);
System.out.println(user);
session.close();//释放一级缓存
SqlSession session1 = factory.openSession();//再次打开session
IUserDao userDao1 = session1.getMapper(IUserDao.class);
User user1 = userDao1.findById(57);
System.out.println(user1);
session1.close();
}
}
```
### #{ }与${ }的区别

。#{}表示一个占位符号 通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止sql注入。 #{}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。sql语句中使用#{}字符: 它代表占位符,相当于原来jdbc部分所学的?,都是用于执行语句时替换实际的数据。 具体的数据是由#{}里面的内容决定的。 #{}中内容的写法: 由于数据类型是基本类型,所以此处可以随意写。我们在上面将原来的#{}占位符,改成了${value}。注意如果用模糊查询的这种写法,那么${value}的写法就是固定的,不能写成其它名字。
${}表示**拼接sql串** 通过${}可以将parameterType 传入的内容拼接在sql中且不进行jdbc类型转换, ${}可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值,${}括号中只能是value。
### 序列化接口
**什么是Serializable接口**
一个对象序列化的接口,一个类只有实现了Serializable接口,它的对象才能被序列化。
**什么是序列化?**
序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
**为什么要序列化对象**
把对象转换为字节序列的过程称为对象的序列化把字节序列恢复为对象的过程称为对象的反序列化**什么情况下需要序列化?**
当我们需要把对象的状态信息通过网络进行传输,或者需要将对象的状态信息持久化,以便将来使用时都需要把对象进行序列化
那为什么还要继承Serializable。那是存储对象在存储介质中,以便在下次使用的时候,可以很快捷的重建一个副本。
或许你会问,我在开发过程中,实体并没有实现序列化,但我同样可以将数据保存到mysql、Oracle数据库中,为什么非要序列化才能存储呢?
我们来看看Serializable到底是什么,跟进去看一下,我们发现Serializable接口里面竟然什么都没有,只是个空接口
### 错误解决:
这里不是错误是警告:由于版本过高导致,将jdk版本降低到jdk1.8即可。
,由于使用mysql客户端创建的表格数据为空,没有返回查询结果
```cmd
log4j:WARN No appenders could be found for logger (org.apache.ibatis.logging.LogFactory).
log4j:WARN Please initialize the log4j system properly.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.ibatis.reflection.Reflector (file:/C:/SoftWare/apache-maven/maven-repository/org/mybatis/mybatis/3.3.1/mybatis-3.3.1.jar) to method java.lang.Class.checkPackageAccess(java.lang.SecurityManager,java.lang.ClassLoader,boolean)
WARNING: Please consider reporting this to the maintainers of org.apache.ibatis.reflection.Reflector
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
```
不支持发行版本5
在porm中没有添加编译插件的情况下project的默认编译版本为版本5,版本过低就会报错
解决办法:
1. 在porm中指定编译插件版本为较新版本,maven会为项目指定编译版本
```cmd
```
2. 或者在setting中指定编译器版本为固定的13版这样,而不跟随project变化版本号。以后都会使用13版本作为项目的编译版本
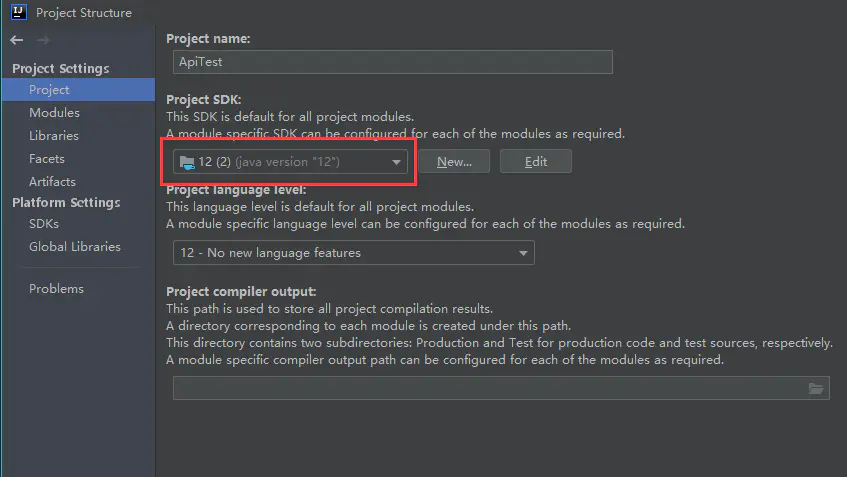
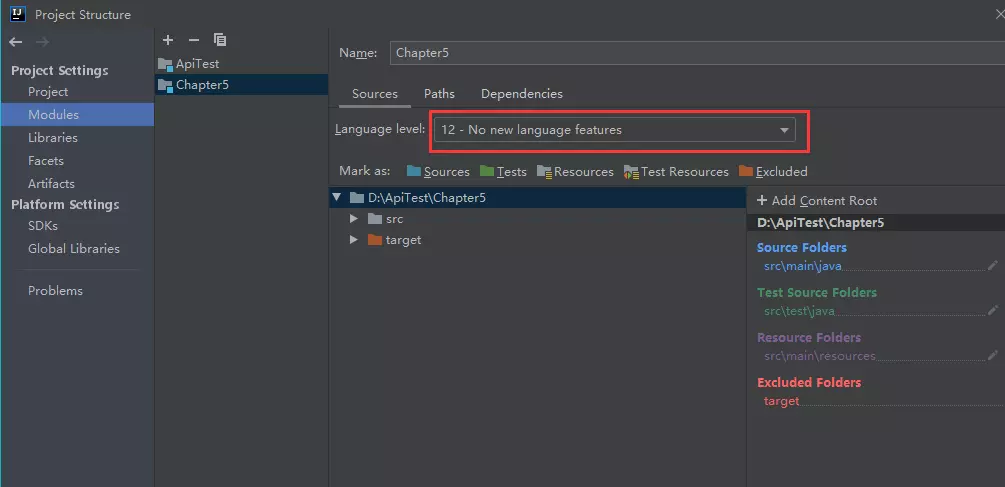
IDEA--->File--->project structure的Moduels设置jdk版本时会出现以下提示
```cmd
Module 'mybatis-generator' is imported from Maven..Any changes made in its configuration may be lost after reimporting,
```
意思是maven项目中在这里修改配置没有用的,重运行时还是以Maven中的配置为准。
可以在java compliler中直接修改编译版本为13,去掉porm中的编译器插件,这样就起作用了。但是IDEA中的配置只在本电脑有用。不推荐使用
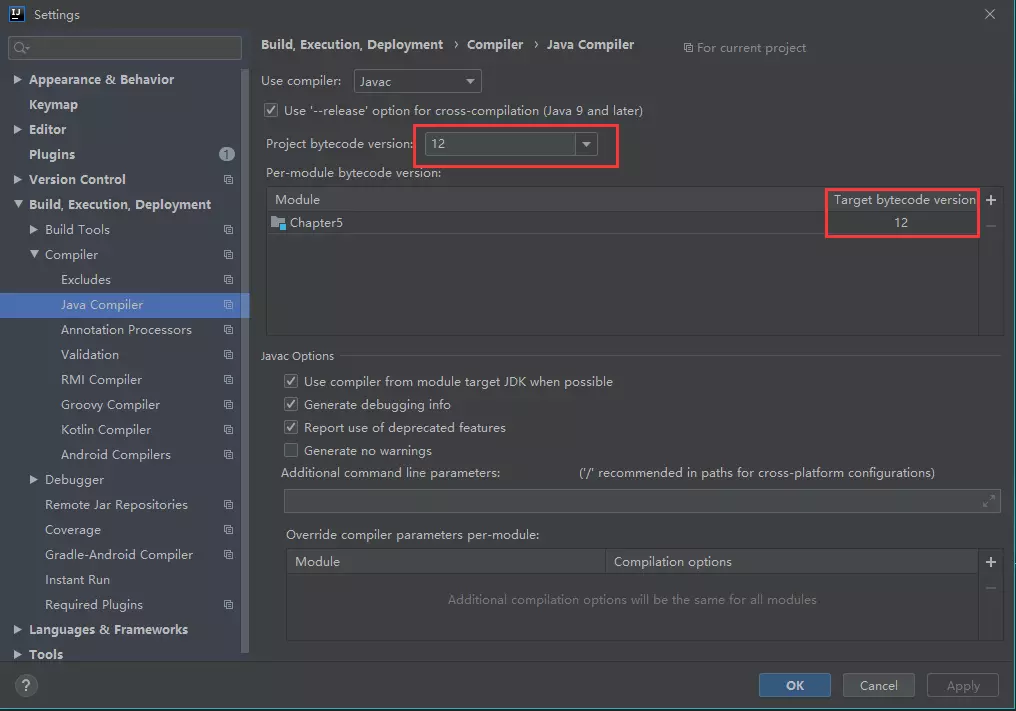
**更推荐使用maven配置,这样项目移动到其他主机也同样不会报错。**