pytorch 音频分类
They’ve been some really interesting applications of style transfer. It basically aims to take the ‘style’ from one image and change the ‘content’ image to meet that style.
它们是样式转移的一些非常有趣的应用程序 。 它的基本目的是从一个图像中获取“样式”,并更改“内容”图像以适应该样式。
But so far it hasn’t really been applied to audio. So I explored the idea of applying neural style transfer to audio. To be frank, the results were less than stellar but I’m going to keep working on this in the future.
但是到目前为止,它还没有真正应用于音频。 因此,我探索了将神经样式转换应用于音频的想法。 坦率地说,结果还不算很出色,但将来我会继续努力。
For this exercise, I’m going to be using clips from the joe rogan podcast. I’m trying to make Joe Rogan, from the Joe Rogan Experience, sound like Joey Diaz, from the Church of Whats Happening Now. Joe Rogan already does a pretty good impression of joey diaz. But I’d like to improve his impression using deep learning.
在本练习中,我将使用joe rogan播客的剪辑。 我试图使来自“ 乔罗根体验 ”( Joe Rogan Experience)的乔•罗 根 ( Joe Rogan )听起来像是“ 现在发生了一切的教堂”中的 乔伊迪亚兹 ( Joey Diaz) 。 乔·罗根(Joe Rogan)已经给乔伊·迪亚兹(joey diaz)留下了很好的印象 。 但是我想通过深度学习来改善他的印象。

First I’m going to download the youtube videos. There’s a neat trick mentioned on github that allows you to download small segments of youtube videos. That’s handy cause I don’t want to download the entire video. You’ll need youtube-dl and ffmpeg for this step.
首先,我要下载youtube视频。 github上提到了一个巧妙的技巧,可让您下载一小段youtube视频。 这很方便,因为我不想下载整个视频。 此步骤需要youtube-dl和ffmpeg 。
损失函数 (Loss Functions)
There are two types of loss for this
有两种类型的损失
- Content loss. Lower values for this means that the output audio sounds like joe rogan. 内容丢失。 较低的值表示输出音频听起来像joe rogan。
- Style loss. Lower values for this means that the output audio sounds like joey diaz. 风格流失。 较低的值表示输出音频听起来像joey diaz。
Ideally we want both content and style loss to be minimised.
理想情况下,我们希望同时减少内容和样式损失。
内容丢失 (Content loss)
The content loss function takes in an input matrix and a content matrix. The content matrix corresponds to joe rogan’s audio. Then it returns the weighted content distance: between the input matrix and the content matrix. This is implemented using a torch module. It can be calculated using nn.MSELoss.
内容损失函数接受输入矩阵和内容矩阵。 内容矩阵对应于joe rogan的音频。 然后,它返回输入矩阵和内容矩阵之间的加权内容距离: 这是落实使用炬模块。 可以使用nn.MSELoss进行计算。
This implementation of content loss was largely borrowed from here.
内容丢失的这种实现很大程度上是从这里借来的。
风格损失 (Style loss)
When looking at the style we really just want to extract the way in which joey diaz speaks. We don’t really want to extract the exact words he says. But we want to get the tone, the intonation, the inflection, etc. from his speech. For that we’ll need to get the gram matrix.
在查看样式时,我们真的只想提取joey diaz说话的方式。 我们真的不想提取他所说的确切词。 但是我们想从他的讲话中获得语气,语调,曲折等。 为此,我们需要获取gram矩阵。
To calculate this we get the first slice in the input matrix and flatten it. Flattening this slice in the matrix removes a lot of audio information. Then we take another slice from the input matrix and flatten it. We take the dot product of the flattened matrices.
为了计算这一点,我们获得输入矩阵中的第一个切片并将其展平。 将此矩阵中的片段展平会删除大量音频信息。 然后,我们从输入矩阵中获取另一个切片并将其展平。 我们取平坦矩阵的点积。
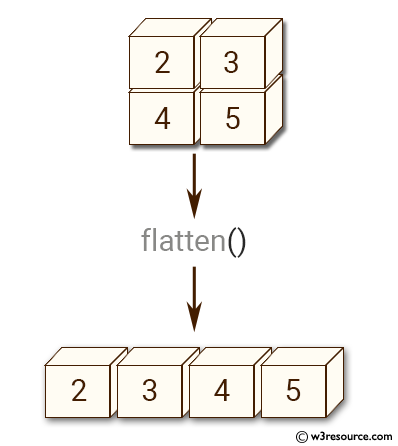
A dot product is a measure of how similar the two matrices are. If the matrices are similar then the we’ll get a really large result. If they are very different we’ll get a very small result.
点积是两个矩阵相似程度的度量。 如果矩阵相似,那么我们将得到非常大的结果。 如果它们非常不同,我们将获得非常小的结果。
So for example, let’s say that the first flattened matrix corresponded with pitch. And let’s say that the second flattened matrix corresponded with volume. If we get a high dot product, then it’s saying that when volume is high pitch is also high. Or in other words when joey talks very loudly his voice increases in pitch.
因此,例如,假设第一个展平的矩阵与音高相对应。 假设第二个扁平化矩阵与体积相对应。 如果我们得到的是高点积,那就意味着当音量高时音高也很高。 换句话说,当乔伊大声说话时,他的声音变高。
The dot products can give us very large numbers. We normalize them by dividing each element by the total number of elements in the matrix.
点积可以给我们很大的数目。 我们通过将每个元素除以矩阵中元素的总数来对其进行归一化。
转换Wav成矩阵 (Convert Wav to Matrix)
To convert the waveform audio to a matrix that we can pass to pytorch I’ll use librosa. Most of this code was borrowed from Dmitry Ulyanov's github repo and Alish Dipani's github repo.
要将波形音频转换成可以传递给pytorch的矩阵,我将使用librosa 。 大部分代码是从Dmitry Ulyanov的github存储库和Alish Dipani的github存储库中借用的。
We get the Short-time Fourier transform from the audio using the librosa library. The window size for this is 2048, which is also the default setting. There is scope here for replacing the code with code from torchaudio. But this works for now.
我们使用librosa库从音频中获得了短时傅立叶变换。 此窗口的大小是2048 ,这也是默认设置。 这里有用torchaudio中的代码替换代码的范围。 但这暂时有效。
创建CNN (Create CNN)
This CNN is very shallow. It consists of 2 convolutions and a ReLU in between them. I originally took the CNN used here but I’ve made a few changes.
这个CNN非常浅。 它由2个卷积和它们之间的ReLU组成。 我本来是在这里使用的CNN ,但做了一些更改。
- Firstly, I added content loss. This wasn’t added before and is obviously very useful. We’d like to know how close (or far away) the audio sounds to the original content. 首先,我增加了内容损失。 这是以前没有添加的,显然非常有用。 我们想知道音频听起来与原始内容有多近(或远)。
Secondly, I added a ReLU to the model. It’s pretty well established that nonlinear activations are desired in a neural network. Adding a ReLU improved the model significantly.
其次,我在模型中添加了ReLU。 它很好建立的是非线性的激活在神经网络所需。 添加ReLU可以显着改善模型。
Increased the number of steps. From
2500to20000增加了步骤数。 从
2500到20000Slightly deepened the network. I added a layer of
Conv1d. After this layer style loss and content loss is calculated. This improved the model as well, but adding ReLU resulted in the largest improvement by far.网络略有加深。 我添加了一层
Conv1d。 在此层之后,将计算样式损失和内容损失。 这也改进了模型,但是添加ReLU带来了迄今为止最大的改进。
I personally found that my loss values — particularly for style loss — were very low. So low they were almost 0. I recitifed this by multiplying by a style_weight and a content_weight. This seems like a crude solution. But according to fastai you care about the direction of the loss and its relative size. So I think it's alright for now.
我个人发现我的损失值(尤其是样式损失)非常低。 如此之低,他们几乎为0 。 我通过将style_weight和content_weight相乘来说明这一点。 这似乎是一个粗略的解决方案。 但是根据fastai,您关心损失的方向及其相对大小。 所以我认为目前还可以。
运行样式转换 (Run style transfer)
Now I’ll run the style transfer. This will use the optim.Adam optimizer. This piece of code was taken from the pytorch tutorial for neural style transfer. For each iteration of the network the style loss and content loss is calculated. In turn that is used to get the gradients. The gradients are mulitplied by the learning rates. That in turn updates the input audio matrix. In pytorch the optimizer requries a closure function.
现在,我将运行样式转换。 这将使用optim.Adam优化程序。 这段代码来自pytorch教程,用于神经样式转换 。 对于网络的每次迭代,都会计算样式损失和内容损失。 依次用于获取渐变。 梯度乘以学习率。 依次更新输入音频矩阵。 在pytorch中,优化器需要关闭函数。
重构音频 (Reconstruct the Audio)
Finally the audio needs to be reconstructed. To do that the librosa inverse short-time fourier transform can be used.
最后,音频需要重建。 为此,可以使用librosa逆短时傅立叶逆变换。
Then we write to an audio file and use the jupyter notebook extension to play the audio in the notebook.
然后,我们写入音频文件,并使用jupyter笔记本扩展名在笔记本中播放音频。
The notebook for this can be found on Github
可以在Github上找到用于此目的的笔记本
Originally published at https://spiyer99.github.io on August 2, 2020.
最初于 2020年8月2日 发布在 https://spiyer99.github.io 。
翻译自: https://towardsdatascience.com/neural-style-transfer-for-audio-in-pytorch-e1de972b1f68
pytorch 音频分类