4.2.1 Kafka 架构与实战, 介绍及优势, 应用场景, 基本架构, 核心概念, 单机安装配置, SpringBoot下实战, 服务端参数配置
目录
第一部分 Kafka架构与实战
1.1 概念和基本架构
1.1.1 Kafka介绍
1.1.2 Kafka优势
1.1.3 Kafka应用场景
1.1.4 基本架构
1.1.5 核心概念
1.1.5.1 Producer
1.1.5.2 Consumer
1.1.5.3 Broker
1.1.5.4 Topic
1.1.5.5 Partition
1.1.5.6 Replicas
1.1.5.7 Offset
1.1.5.8 副本
1.1.5.8.1 AR (Assigned Repllicas)
1.1.5.8.2 ISR(In-Sync Replicas)
1.1.5.8.3 OSR (Out-Sync Relipcas)
1.1.5.8.4 HW (High Watermark)
1.1.5.8.5 LEO (Log End Offset)
1.2 Kafka安装与配置
1.2.1 Java环境为前提
1.2.2 Zookeeper的安装配置
1.2.3 Kafka的安装与配置
1.2.4 生产与消费
1.3 Kafka开发实战
1.3.1 消息的发送与接收
生产消息流程:
消息消费流程:
1.3.2 SpringBoot Kafka
1.4 服务端参数配置
1.4.1 zookeeper.connect
1.4.2 listeners
内外网隔离配
1.4.3 broker.id
1.4.4 log.dir
第一部分 Kafka架构与实战
1.1 概念和基本架构
1.1.1 Kafka介绍
最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。廉价商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个分区内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展(服务不停)
两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,可以通过轮询实现消息的推送。
1. Kafka在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
2. Kafka集群中按主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区。
3. 每个记录由一个键,一个值和一个时间戳组成。
Kafka具有四个核心API:
1. Producer API:允许应用程序将记录流发布到一个或多个Kafka主题。
2. Consumer API:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
3. Streams API:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多个输出主题的输出流,从而有效地将输入流转换为输出流。
4. Connector API:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产者或使用者。例如,关系数据库的连接器可能会捕获对表的所有更改。
1.1.2 Kafka优势
1. 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的性能。
2. 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
3. 持久化数据存储:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢失。
- 零拷贝
- 顺序读,顺序写
- 利用Linux的页缓存
4. 分布式系统,易于向外扩展。所有的Producer、Broker和Consumer都会有多个,均为分布式的。无需停机即可扩展机器。多个Producer、Consumer可能是不同的应用。
5. 可靠性 - Kafka是分布式,分区,复制和容错的。
6. 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡。
7. 支持online和offline的场景。
8. 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言。
1.1.3 Kafka应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的Log,通过Kafka以统一接口服务的方式开放给各种Consumer;
消息系统:解耦生产者和消费者、缓存消息等;
用户活动跟踪:Kafka经常被用来记录Web用户或者App用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到Kafka的Topic中,然后消费者通过订阅这些Topic来做实时的监控分析,亦可保存到数据库;
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
流式处理:比如Spark Streaming和Storm。
1.1.4 基本架构
消息和批次
Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”。消息由字节数组组成。
消息有键,键也是一个字节数组。当消息以一种可控的方式写入不同的分区时,会用到键。
为了提高效率,消息被分批写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。
把消息分成批次可以减少网络开销。批次越大,单位时间内处理的消息就越多,单个消息的传输时间就越长。批次数据会被压缩,这样可以提升数据的传输和存储能力,但是需要更多的计算处理。
模式
消息模式(schema)有许多可用的选项,以便于理解。如JSON和XML,但是它们缺乏强类型处理能力。Kafka的许多开发者喜欢使用Apache Avro。Avro提供了一种紧凑的序列化格式,模式和消息体分开。当模式发生变化时,不需要重新生成代码,它还支持强类型和模式进化,其版本既向前兼容,也向后兼容。
数据格式的一致性对Kafka很重要,因为它消除了消息读写操作之间的耦合性。
主题和分区
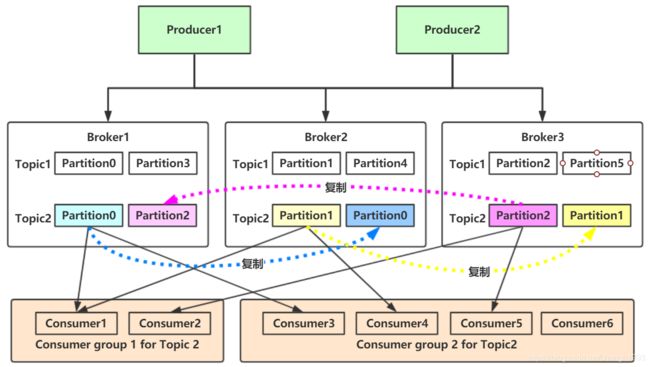
Kafka的消息通过主题进行分类。主题可比是数据库的表或者文件系统里的文件夹。主题可以被分为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。
生产者和消费者
生产者创建消息。消费者消费消息。
一个消息被发布到一个特定的主题上。
生产者在默认情况下把消息均衡地分布到主题的所有分区上:
1. 直接指定消息的分区
2. 根据消息的key散列取模得出分区
3. 轮询指定分区。
消费者通过偏移量来区分已经读过的消息,从而消费消息。
消费者是消费组的一部分。消费组保证每个分区只能被一个消费者使用,避免重复消费。
broker和集群
一个独立的Kafka服务器称为broker。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘上的消息。单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
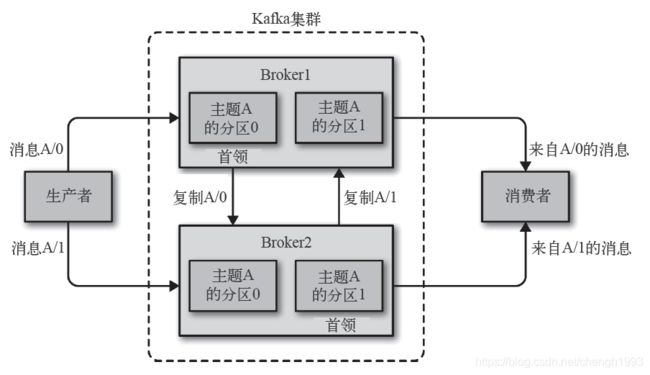
每个集群都有一个broker是集群控制器(自动从集群的活跃成员中选举出来)。
控制器负责管理工作:
- 将分区分配给broker
- 监控broker(zk的分布式锁)
集群中一个分区属于一个broker,该broker称为分区首领。
一个分区可以分配给多个broker,此时会发生分区复制。
分区的复制提供了消息冗余,高可用。副本分区不负责处理消息的读写。
1.1.5 核心概念
1.1.5.1 Producer
生产者创建消息。
该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的 segment 文件中。
一般情况下,一个消息会被发布到一个特定的主题上。
1. 默认情况下通过轮询把消息均衡地分布到主题的所有分区上。
2. 在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。
3. 生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
1.1.5.2 Consumer
消费者读取消息。
1. 消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。
2. 消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,Kafka 会把它添加到消息里。在给定的分区中,消息偏移量唯一。消费者把每个分区最后读取的消息偏移量保存在Zookeeper 或Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
3. 消费者是消费组的一部分。群组保证每个分区只能被一个消费者使用。
4. 消费者失效,同组里的其他消费者可以接管失效消费者的工作,再平衡,分区重新分配。
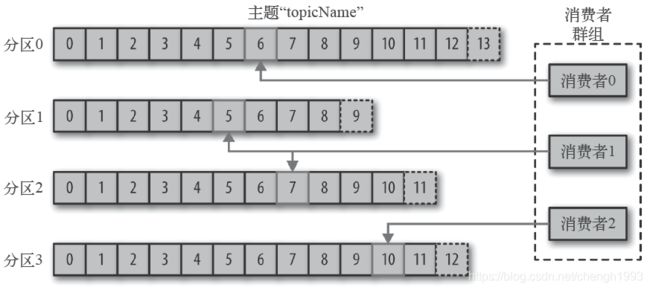
1.1.5.3 Broker
一个独立的Kafka 服务器被称为broker。
broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
1. 如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
2. 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
3. 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
broker 是集群的组成部分。每个集群都有一个broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
控制器负责管理工作,包括将分区分配给broker 和监控broker。
在集群中,一个分区从属于一个broker,该broker 被称为分区的首领。多个相同分区的也有自己的主从关系.
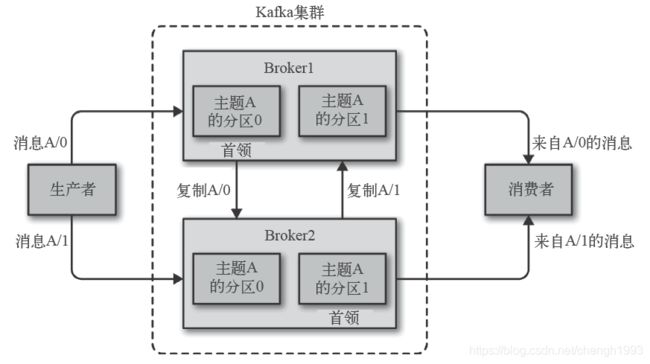
1.1.5.4 Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
物理上不同Topic的消息分开存储。
主题就好比数据库的表,尤其是分库分表之后的逻辑表。
1.1.5.5 Partition
1. 主题可以被分为若干个分区,一个分区就是一个提交日志。
2. 消息以追加的方式写入分区,然后以先入先出的顺序读取。
3. 无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
4. Kafka 通过分区来实现数据冗余和伸缩性。
5. 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
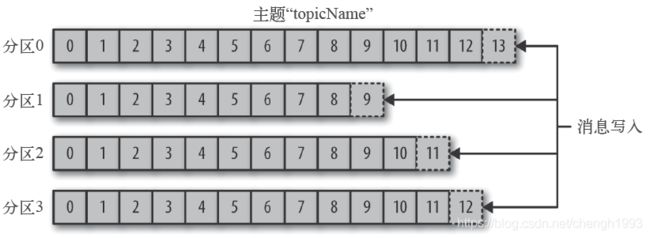
1.1.5.6 Replicas
Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
副本有以下两种类型:
首领副本(读写)
每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本。
跟随者副本(备份)
首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领发生崩溃,其中的一个跟随者会被提升为新首领。
1.1.5.7 Offset
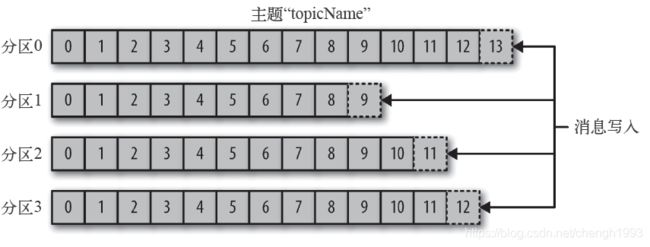
生产者Offset
消息写入的时候,每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区的最新最大的offset。
有些时候没有指定某一个分区的offset,这个工作kafka帮我们完成。
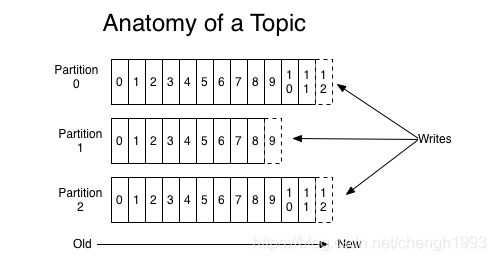
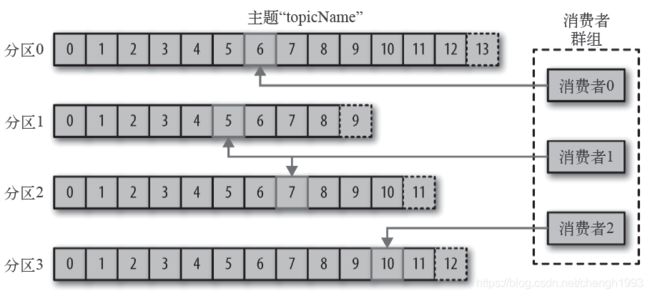
消费者Offset
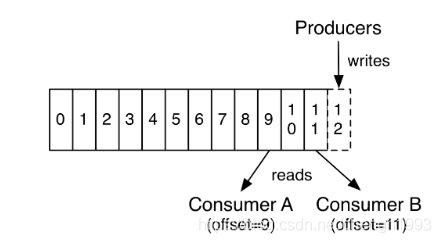
这是某一个分区的offset情况,生产者写入的offset是最新最大的值是12,而当Consumer A进行消费时,从0开始消费,一直消费到了9,消费者的offset就记录在9,Consumer B就纪录在了11。等下一次他们再来消费时,他们可以选择接着上一次的位置消费,当然也可以选择从头消费,或者跳到最近的记录并从“现在”开始消费。
1.1.5.8 副本
Kafka通过副本保证高可用。副本分为首领副本(Leader)和跟随者副本(Follower)。
跟随者副本包括同步副本和不同步副本,在发生首领副本切换的时候,只有同步副本可以切换为首领副本。
1.1.5.8.1 AR (Assigned Repllicas)
分区中的所有副本统称为AR(Assigned Repllicas)。
AR=ISR+OSR
1.1.5.8.2 ISR(In-Sync Replicas)
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度”是指可以忍受的滞后范围,这个范围可以通过参数进行配置。
1.1.5.8.3 OSR (Out-Sync Relipcas)
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas)。在正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
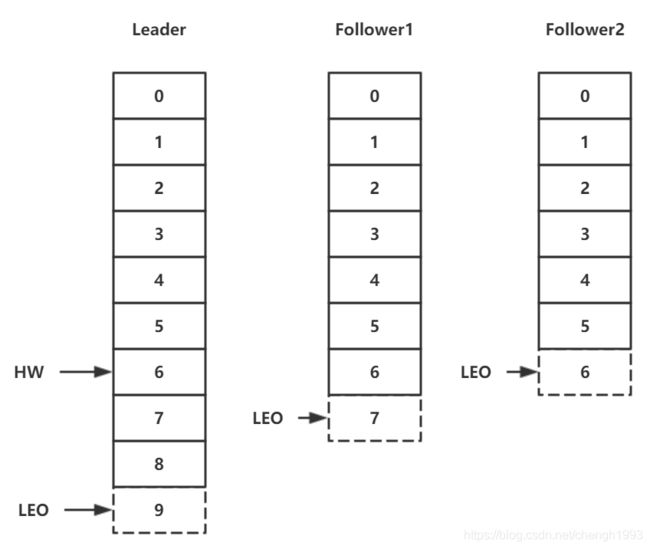
1.1.5.8.4 HW (High Watermark)
HW是High Watermark的缩写, 俗称高水位,它表示了一个特定消息的偏移量(offset),消费者只能拉取到这个offset之前的消息。
1.1.5.8.5 LEO (Log End Offset)
LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset。
1.2 Kafka安装与配置
1.2.1 Java环境为前提
1、上传jdk-8u261-linux-x64.rpm到服务器并安装:
rpm -ivh jdk-8u261-linux-x64.rpm
2、配置环境变量:
vim /etc/profile

# 生效
source /etc/profile# 验证
java -version

1.2.2 Zookeeper的安装配置
1、上传zookeeper-3.4.14.tar.gz到服务器
2、解压到/opt:
tar -zxf zookeeper-3.4.14.tar.gz -C /opt
cd /opt/zookeeper-3.4.14/conf# 复制zoo_sample.cfg命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg# 编辑zoo.cfg文件
vim zoo.cfg
3、修改Zookeeper保存数据的目录,dataDir:
- dataDir=/var/lagou/zookeeper/data
4、编辑/etc/profile:
- 设置环境变量ZOO_LOG_DIR,指定Zookeeper保存日志的位置;
- ZOOKEEPER_PREFIX指向Zookeeper的解压目录;
- 将Zookeeper的bin目录添加到PATH中:

5、使配置生效:
source /etc/profile
6、验证:

1.2.3 Kafka的安装与配置
1、上传kafka_2.12-1.0.2.tgz到服务器并解压:
tar -zxf kafka_2.12-1.0.2.tgz -C /opt/lagou/servers/
2、配置环境变量并生效:
vim /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/lagou/servers/kafka_2.12-1.0.2
export $PATH:$KAFKA_HOME/bin
3、配置/opt/kafka_2.12-1.0.2/config中的server.properties文件:
Kafka连接Zookeeper的地址,此处使用本地启动的Zookeeper实例,连接地址是localhost:2181,后面的 myKafka 是Kafka在Zookeeper中的根节点路径:

配置zk节点
#zookeeper.connect=localhost:2181
zookeeper.connect=localhost:2181/myKafka
配置kafka存储持久化数据日志目录
#log.dirs=/tmp/kafka-logs
log.dirs=/opt/lagou/servers/kafka_2.12-1.0.2/logs/kafka-logsmkdir /opt/lagou/servers/kafka_2.12-1.0.2/logs/kafka-logs
4、启动Zookeeper:
zkServer.sh start
5、确认Zookeeper的状态:

6、启动Kafka:
进入Kafka安装的根目录,执行如下命令:

启动成功,可以看到控制台输出的最后一行的started状态:
![]()
7、查看Zookeeper的节点:

8、此时Kafka是前台模式启动,要停止,使用Ctrl+C。
如果要后台启动,使用命令:
kafka-server-start.sh -daemon config/server.properties
![]()
查看Kafka的后台进程:
ps aux | grep kafka
停止后台运行的Kafka:

1.2.4 生产与消费
1、kafka-topics.sh 用于管理主题。
# 列出现有的主题
[root@node1 ~]# kafka-topics.sh --list --zookeeper localhost:2181/myKafka# 创建主题,该主题包含一个分区,该分区为Leader分区,它没有Follower分区副本。
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic topic_1 --partitions 1 --replication-factor 1# 创建主题,该主题包含5个分区,该分区为Leader分区,它没有Follower分区副本。
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic topic_2 --partitions 5 --replication-factor 1

# 查看所有主题
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --list

# 查看指定主题的详细信息
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic topic_1

# 查看指定主题的详细信息
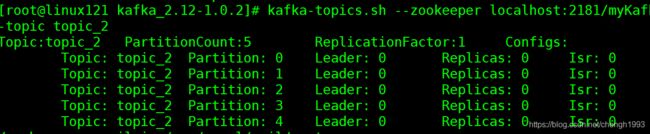
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic topic_2
# 删除指定主题
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic topic_1
2、kafka-console-producer.sh用于生产消息:
# 开启生产者
[root@node1 ~]# kafka-console-producer.sh --topic topic_1 --broker-list localhost:9092

3、kafka-console-consumer.sh用于消费消息:
# 开启消费者 , 连接上一台, 就会通过这台服务器访问其他服务器
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1
生产者输入消息, 然后


# 开启消费者方式二,从头消费,不按照偏移量消费
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1 --from-beginning
再打开, 之前的就看不到了
再次关闭使用上面的启动方式, 就能看见之前的



cd /opt/lagou/servers/kafka_2.12-1.0.2/logs/kafka-logs/
ls
1.3 Kafka开发实战
1.3.1 消息的发送与接收
新建maven工程, 导入依赖
UTF-8
UTF-8
1.8
1.8
1.8
org.apache.kafka
kafka-clients
1.0.2
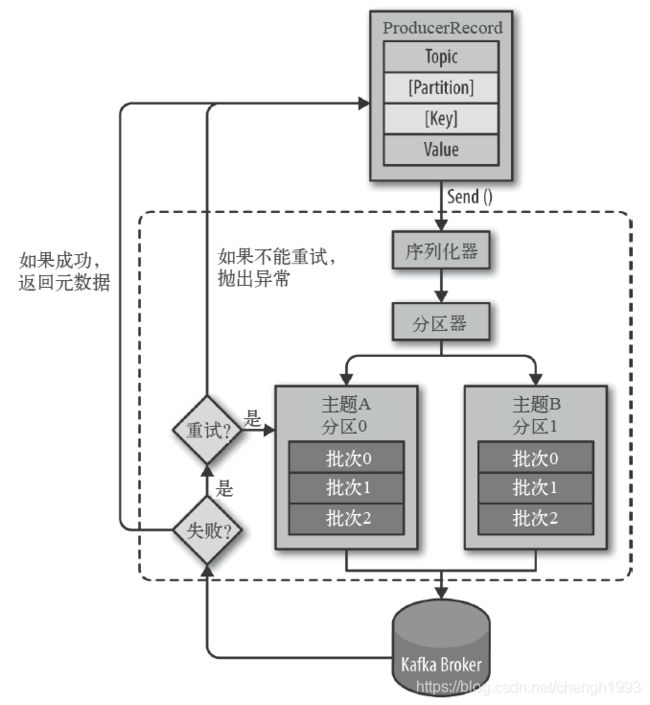
生产消息流程:
生产者主要的对象有: KafkaProducer , ProducerRecord 。
其中 KafkaProducer 是用于发送消息的类, ProducerRecord 类用于封装Kafka的消息。
KafkaProducer 的创建需要指定的参数和含义:
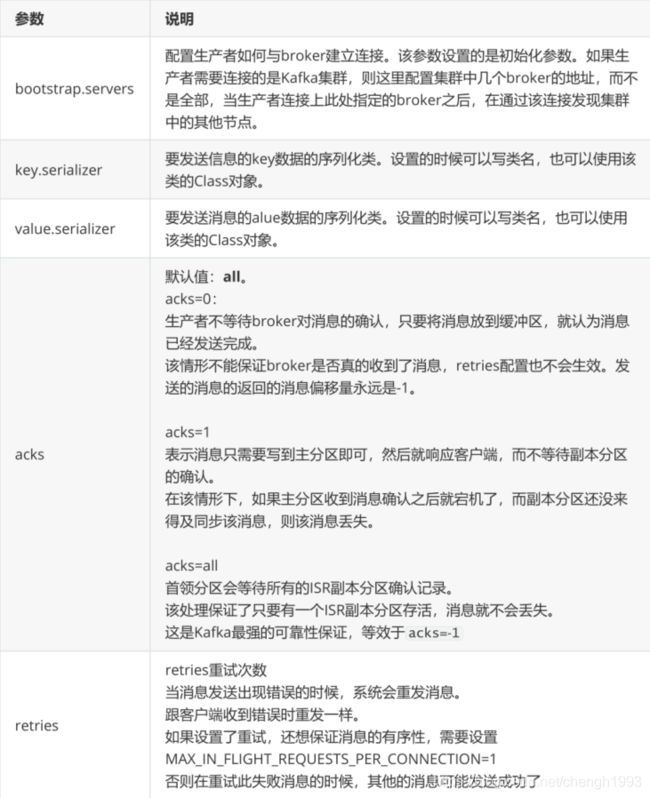
其他参数可以从 org.apache.kafka.clients.producer.ProducerConfig 中找到。后面的内容会介绍。
消费者生产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
同步确认效率低,异步确认效率高,但是需要设置回调对象。
生产者:
package com.lagou.kafka.demo.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.internals.RecordHeader;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class MyProducer1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Map configs = new HashMap<>();
// 指定初始连接用到的broker地址
configs.put("bootstrap.servers", "192.168.80.121:9092");
// 指定key的序列化类
configs.put("key.serializer", IntegerSerializer.class);
// 指定value的序列化类
configs.put("value.serializer", StringSerializer.class);
// 下面可以设置也可以不设置
//configs.put("acks", "all");
//configs.put("reties", "3");
KafkaProducer producer = new KafkaProducer(configs);
// 用于设置用户自定义的消息头字段
List headers = new ArrayList<>();
headers.add(new RecordHeader("biz.name", "producer.demo".getBytes()));
// 使用ProducerRecord封装消息
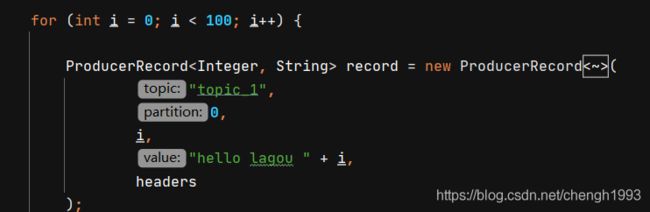
ProducerRecord record = new ProducerRecord(
"topic_1",
0,
0,
"hello lagou 0",
headers
);
// =========================下面在代码中要注掉========================================
// 消息的同步确认
final Future future = producer.send(record);
// 记录的元数据
final RecordMetadata metadata = future.get();
System.out.println("消息的主题:" + metadata.topic());
System.out.println("消息的分区号:" + metadata.partition());
System.out.println("消息的偏移量:" + metadata.offset());
// ============================================================================
// 消息的异步确认
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("消息的主题:" + metadata.topic());
System.out.println("消息的分区号:" + metadata.partition());
System.out.println("消息的偏移量:" + metadata.offset());
} else {
System.out.println("异常消息:" + exception.getMessage());
}
}
});
// 关闭生产者
producer.close();
}
}

消息消费流程:
Kafka不支持消息的推送, 可以自己实现
Kafka采用的是消息的拉取(poll方法)
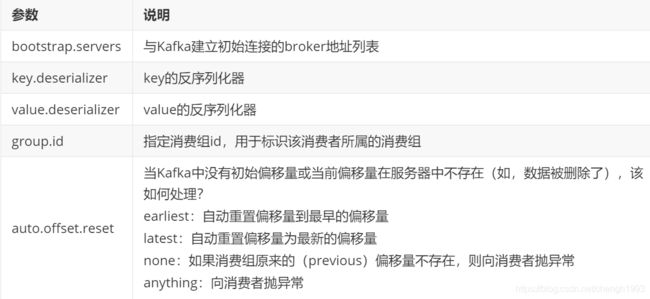
消费者主要的对象由: KafkaConsumer用于消费消息的类,
KfakaConsumer的创建需要指定的参数和含义:
消费者:
package com.lagou.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Consumer;
public class MyConsumer1 {
public static void main(String[] args) {
// 准备一个存参数的集合
Map configs = new HashMap<>();
// linux121对应于192.168.80.121,windows的hosts文件中手动配置域名解析
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux121:9092");
// 使用常量代替手写的字符串,配置key的反序列化器
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
// 配置value的反序列化器
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 配置消费组ID
// 下面的消费组ID, 最初设置的偏移量是lastest, 因此没有消息被消费, 重新拉取需要设置新的消费组
// 因为前一个消费组的偏移量已经被设置成最后
//configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer_demo");
configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer_demo1");
// 如果找不到当前消费者的有效偏移量,则自动重置到最开始
// latest表示直接重置到消息偏移量的最后一个
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer consumer = new KafkaConsumer(configs);
// 先订阅,再消费
consumer.subscribe(Arrays.asList("topic_1"));
// =======================下面的在运行中要注掉============================================
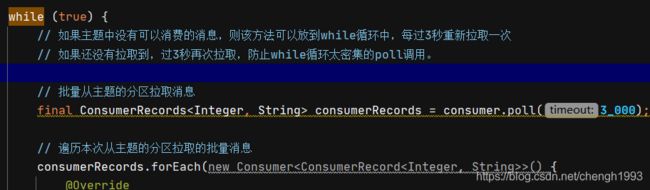
while (true) {
final ConsumerRecords consumerRecords = consumer.poll(3_000);
// }
// 如果主题中没有可以消费的消息,则该方法可以放到while循环中,每过3秒重新拉取一次
// 如果还没有拉取到,过3秒再次拉取,防止while循环太密集的poll调用。
// ===================================================================
// poll方法会批量从主题的分区拉取消息, 也可以设置成一次拉取一条
final ConsumerRecords consumerRecords = consumer.poll(3_000);
// 遍历本次从主题的分区拉取的批量消息
consumerRecords.forEach(new Consumer>() {
@Override
public void accept(ConsumerRecord record) {
System.out.println(record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
});
consumer.close();
}
}
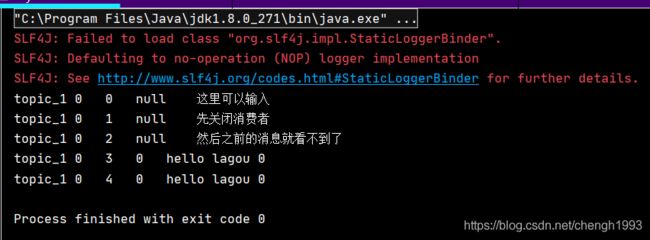
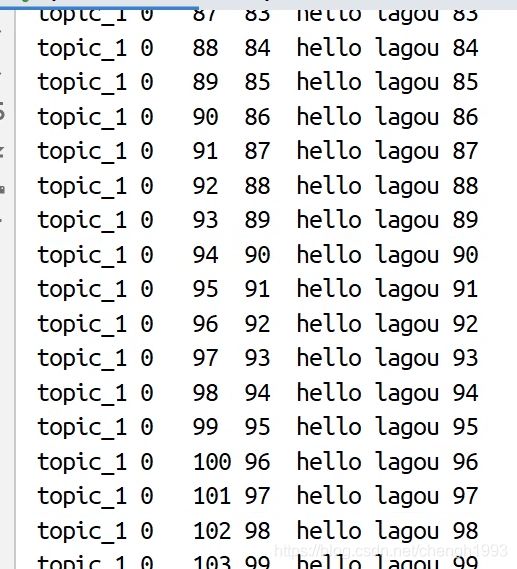
生产和消费都循环的结果是下面这样
1.3.2 SpringBoot Kafka
创建SpringBoot模块
1. pom.xml文件
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.4.2
com.lagou
demo-02-springboot-kafka
0.0.1-SNAPSHOT
demo-02-springboot-kafka
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.kafka
spring-kafka
org.springframework.boot
spring-boot-starter-test
test
org.springframework.kafka
spring-kafka-test
test
org.springframework.boot
spring-boot-maven-plugin
2. application.properties
spring.application.name=springboot-kafka-02
server.port=8080
# kafka的配置
spring.kafka.bootstrap-servers=linux121:9092
#producer配置
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 生产者每个批次最多放多少条记录
spring.kafka.producer.batch-size=16384
# 生产者一端总的可用发送缓冲区大小,此处设置为32MB
spring.kafka.producer.buffer-memory=33554432
#consumer配置
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id=springboot-consumer02
# 如果在kafka中找不到当前消费者的偏移量,则直接将偏移量重置为最早的
spring.kafka.consumer.auto-offset-reset=earliest
# 消费者的偏移量是自动提交还是手动提交,此处自动提交偏移量
spring.kafka.consumer.enable-auto-commit=true
# 消费者偏移量自动提交的时间间隔
spring.kafka.consumer.auto-commit-interval=1000
3. Demo02SpringbootApplication.java
package com.lagou.kafka.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Demo02SpringbootKafkaApplication {
public static void main(String[] args) {
SpringApplication.run(Demo02SpringbootKafkaApplication.class, args);
}
}
4. KafkaSyncProducerController.java
package com.lagou.kafka.demo.controller;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
@RestController
public class KafkaSyncProducerController {
@Autowired
private KafkaTemplate template;
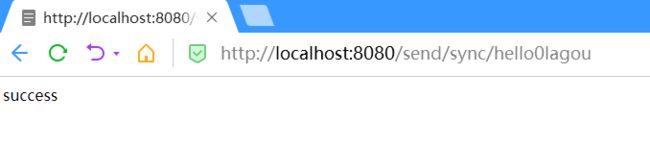
@RequestMapping("send/sync/{message}")
public String send(@PathVariable String message) {
final ListenableFuture> future =
template.send("topic-spring-01", 0, 0, message);
// 同步发送消息
try {
// 下面要同步拿到消息的结果
final SendResult sendResult = future.get();
final RecordMetadata metadata = sendResult.getRecordMetadata();
System.out.println(metadata.topic() + "\t"
+ metadata.partition()
+ "\t" + metadata.offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return "success";
}
}
5. KafkaAsyncProducerController
package com.lagou.kafka.demo.controller;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaAsyncProducerController {
@Autowired
private KafkaTemplate template;
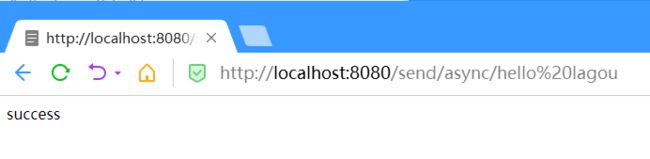
@RequestMapping("send/async/{message}")
public String send(@PathVariable String message) {
final ListenableFuture> future
= this.template.send("topic-spring-01", 0, 1, message);
// 设置回调函数,异步等待broker端的返回结果
future.addCallback(new ListenableFutureCallback>() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送消息失败:"
+ throwable.getMessage());
}
@Override
public void onSuccess(SendResult result) {
final RecordMetadata metadata = result.getRecordMetadata();
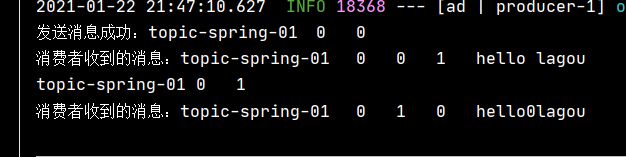
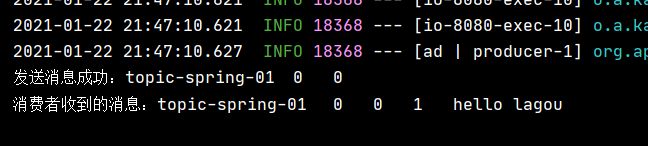
System.out.println("发送消息成功:"
+ metadata.topic()
+ "\t" + metadata.partition()
+ "\t" + metadata.offset());
}
});
return "success";
}
}
6. MyConsumer.java
package com.lagou.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class MyConsumer {
// 底层默认有一个KfakaAdmin对象, 如果发现下面的topics不存在, 则自动创建一个
@KafkaListener(topics = "topic-spring-01")
public void onMessage(ConsumerRecord record) {
System.out.println("消费者收到的消息:"
+ record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
}


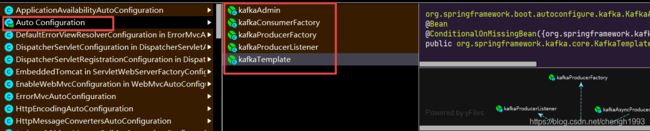
7. KafkaConfig.java
如果不添加本类, 底层会默认创建一个kafkaAdmin对象, 进行相关默认对象的注入
package com.lagou.kafka.demo.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaAdmin;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConfig {
// 下面的两个会自动创建出来
@Bean
public NewTopic topic1() {
return new NewTopic("nptc-01", 3, (short) 1);
}
@Bean
public NewTopic topic2() {
return new NewTopic("nptc-02", 5, (short) 1);
}
// 下面的配置会替换掉原有默认的Admin
@Bean
public KafkaAdmin kafkaAdmin() {
Map configs = new HashMap<>();
configs.put("bootstrap.servers", "linux121:9092");
KafkaAdmin admin = new KafkaAdmin(configs);
return admin;
}
@Bean
@Autowired
// 下面的红线不管, 运行不会报错
public KafkaTemplate kafkaTemplate(ProducerFactory producerFactory) {
// 覆盖ProducerFactory原有设置, 原有设置在application.properties
Map configsOverride = new HashMap<>();
// 从16384改为200
configsOverride.put(ProducerConfig.BATCH_SIZE_CONFIG, 200);
KafkaTemplate template = new KafkaTemplate(
producerFactory, configsOverride
);
return template;
}
}
1.4 服务端参数配置
$KAFKA_HOME/config/server.properties文件中的配置。
1.4.1 zookeeper.connect
该参数用于配置Kafka要连接的Zookeeper/集群的地址。
它的值是一个字符串,使用逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是host:port 形式的,可以在最后添加Kafka在Zookeeper中的根节点路径。
如:
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/myKafka

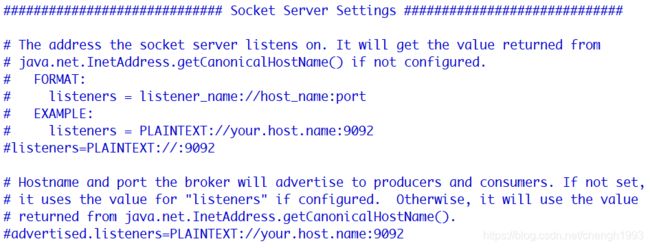
1.4.2 listeners
用于指定当前Broker向外发布服务的地址和端口。
与 advertised.listeners 配合,用于做内外网隔离。
如果进行下面的修改
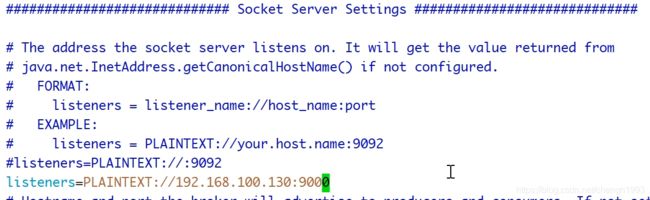
则以下的操作中的 ip及端口号也需要修改
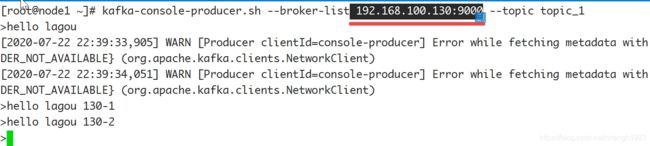

内外网隔离配置:
listener.security.protocol.map
监听器名称和安全协议的映射配置。
比如,可以将内外网隔离,即使它们都使用SSL。
listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL
每个监听器的名称只能在map中出现一次。
inter.broker.listener.name
用于配置broker之间通信使用的监听器名称,该名称必须在advertised.listeners列表中。
inter.broker.listener.name=EXTERNAL
listeners
用于配置broker监听的URI以及监听器名称列表,使用逗号隔开多个URI及监听器名称。
如果监听器名称代表的不是安全协议,必须配置listener.security.protocol.map。
每个监听器必须使用不同的网络端口。
advertised.listeners
从上面的listeners中选择一个或多个, 需要将该地址发布到zookeeper供外部客户端使用,如果客户端使用的地址与listeners配置不同。
可以在zookeeper的 get /myKafka/brokers/ids/
在IaaS环境,该条目的网络接口得与broker绑定的网络接口不同。
如果不设置此条目,就使用listeners的配置。跟listeners不同,该条目不能使用0.0.0.0网络端口。
advertised.listeners的地址必须是listeners中配置的或配置的一部分。
典型配置:
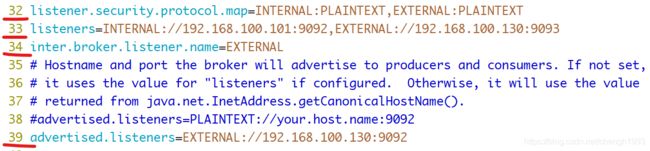
1.4.3 broker.id
该属性用于唯一标记一个Kafka的Broker,它的值是一个任意integer值。
当Kafka以分布式集群运行的时候,尤为重要。
最好该值跟该Broker所在的物理主机有关的,如主机名为 host1.lagou.com ,则 broker.id=1 ,如果主机名为 192.168.100.101 ,则 broker.id=101 等等。

1.4.4 log.dir
通过该属性的值,指定Kafka在磁盘上保存消息的日志片段的目录。
它是一组用逗号分隔的本地文件系统路径。
如果指定了多个路径,那么broker 会根据“最少使用”原则,把同一个分区的日志片段保存到同一个路径下。
broker 会往拥有最少数目分区的路径新增分区,而不是往拥有最小磁盘空间的路径新增分区。
