Flume--图解架构
图解架构
- Flume的架构
-
- 0、Flume使用
- 1、Multiplexing the flow
-
- ==需求1:将同一份数据进行采集hive.log,发送三个不同的地方==
- ==需求2:动态读取两个文件来实现采集到HDFS==
- 2、Consolidation
-
- 需求:
- 实现
Flume的架构
总结
- Multiplexing the flow
一个agent中有多个source、channel、sink
- Consolidation
多个agent合并,两层架构
0、Flume使用
- 定义一个properties文件
- 在文件中定义:collect、aggregate、moving
- Flume的 一个程序叫做一个Agent
- 在properties文件中定义Agent
- 每个Agent都必须包含三大基础组件
1、Multiplexing the flow
- 特点:
一个agent中有多个source、channel、sink
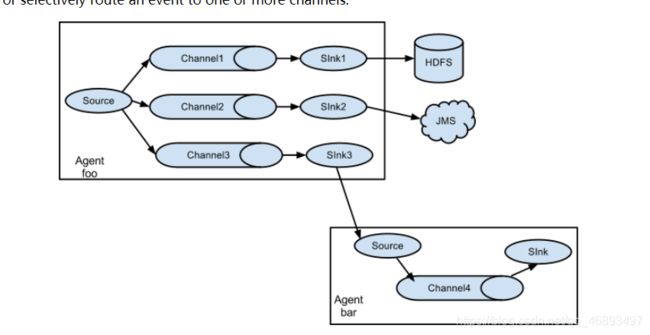
需求1:将同一份数据进行采集hive.log,发送三个不同的地方
- Flume日志放一份
- HDFS上放一份
- 本地文件系统再放一份
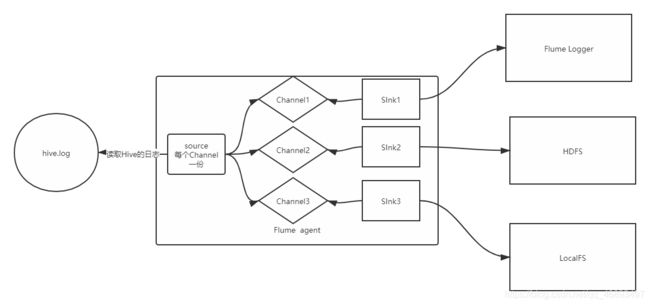
- 实现
- 复制一个程序
cp hive-mem-size.properties mutiple1.properties
- 创建目录
cd /export/datas/flume/
mkdir fileroll
- 修改程序
# define sourceName/channelName/sinkName for the agent
a1.sources = s1
a1.channels = c1 c2 c3
a1.sinks = k1 k2 k3
# define the s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/servers/hive-1.1.0-cdh5.14.0/logs/hive.log
# define the c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# define the c2
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# define the c3
a1.channels.c3.type = memory
a1.channels.c3.capacity = 1000
a1.channels.c3.transactionCapacity = 100
# def the k1
a1.sinks.k1.type = logger
# def the k2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /flume/hdfs/mutiple
a1.sinks.k2.hdfs.filePrefix = hiveLog
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.rollSize = 10240
a1.sinks.k2.hdfs.rollInterval = 0
a1.sinks.k2.hdfs.rollCount = 0
# def the k3
a1.sinks.k3.type = file_roll
a1.sinks.k3.sink.directory = /export/datas/flume/fileroll
#source、channel、sink bond
a1.sources.s1.channels = c1 c2 c3
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
a1.sinks.k3.channel = c3
- 运行测试
bin/flume-ng agent -c conf/ -f userCase/mutiple1.properties -n a1 -Dflume.root.logger=INFO,console
- 问题:
我们这个需求中只是希望将数据放到3个目标地而已,三个sink负责实现,为什么要有三个channel?用一个channel能不能实现呢?不能
- 为什么?
一个Channel中只存储了一份数据如果多个sink都到一个channel中取数据,那么所有的sink共享一份数据
- 切记:如果多个sink想每个sink得到一份完整的数据,必须一个sink对应一个channel
需求2:动态读取两个文件来实现采集到HDFS
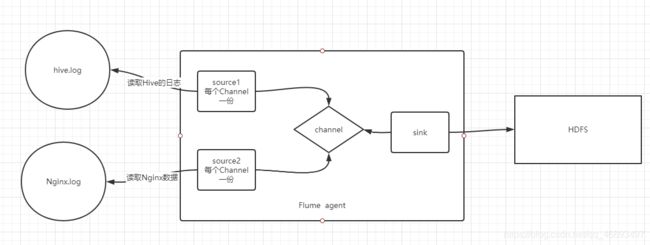
- hive.log
- nginx.log
- 复制一份程序
cp hive-mem-hdfs.properties mutiple2.properties
- 创建一个nginx.log用于测试
touch /export/datas/flume/nginx.log
- 修改程序
# define sourceName/channelName/sinkName for the agent
a1.sources = s1 s2
a1.channels = c1
a1.sinks = k1
# define the s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/servers/hive-1.1.0-cdh5.14.0/logs/hive.log
# define the s2
a1.sources.s2.type = exec
a1.sources.s2.command = tail -f /export/datas/flume/nginx.log
# define the c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# def the k1
a1.sinks.k1.type = hdfs
#指定写入HDFS哪个目录中
a1.sinks.k1.hdfs.path = /flume/hdfs/sources
#指定生成的文件的前缀
a1.sinks.k1.hdfs.filePrefix = hiveLog
#指定生成的文件的后缀
a1.sinks.k1.hdfs.fileSuffix = .log
#指定写入HDFS的文件的类型:普通的文件
a1.sinks.k1.hdfs.fileType = DataStream
#source、channel、sink bond
a1.sources.s1.channels = c1
a1.sources.s2.channels = c1
a1.sinks.k1.channel = c1
- 运行测试
bin/flume-ng agent -c conf/ -f userCase/mutiple2.properties -n a1 -Dflume.root.logger=INFO,console
2、Consolidation
多个agent合并

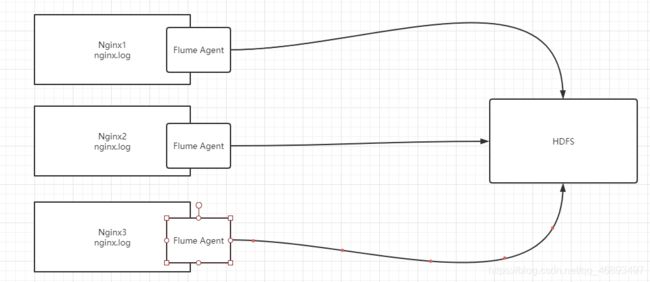
- 应用场景:日志有多台机器都需要进行采集,10台Nginx服务器,用于存储用户行为数据
- 如果我们要实现采集,每一台Nginx都要安装Flume实现采集,给定两种方案
- 方案一:10台Nginx上的10个Flume程序都直接进数据写入HDFS
-
方案二:10台Nginx上的10个Flume将数据发送给另外一个Flume,这个Flume负责将数据汇总发送给HDFS
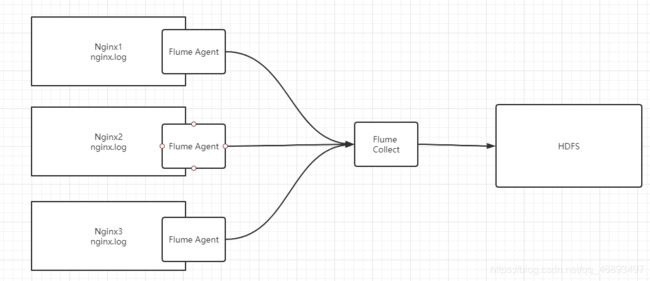
-
优先选择方案二
- 为什么?
多台Flume并发多线程写入HDFS,会导致HDFS磁盘IO和网络的IO剧增,写负载会非常高- 将所有Flume采集到的数据发送给Flume的collect层,来实现
减轻HDFS的负载 - 新的问题:如果10台都写入一个flume collect,导致这一台Flume collect负载过高怎么办?
- 如果有10台,构建2台flume collect
-
如何将Flume的数据发送给另外一个Flume呢?
- 实现将第一层Flume的sink的数据发送给第二层Flume的source
- 通过网络协议来实现
- 这里就出现了两种Flume的程序
- 第一种:
采集层:采集数据文件,发送到Flume的第二层 - 第二种:
收集层:采集所有Flume发过来的数据,发送到HDFS
- 第一种:
需求:
- 第一台和第二台机器作为第一层,采集日志文件,发送给第三台机器
- 第三台机器作为第二层,采集第一台和第二台发送过来的数据,发送到HDFS上
实现
- 创建测试的文件:在第一台和第二台机器上创建
touch /export/datas/nginx.log
- 复制一个程序
cp hive-mem-hdfs.properties collect.properties
- 编辑修改程序
##################################a1:第一台和第二台采集日志发送到第三台机器
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# define the s1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /export/datas/nginx.log
# define the c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# def the k1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node-03
a1.sinks.k1.port = 45454
#source、channel、sink bond
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
############################################a2:将第一台和第二台发送过来的数据写入HDFS
a2.sources = s1
a2.channels = c1
a2.sinks = k1
# define the s1
a2.sources.s1.type = avro
a2.sources.s1.bind = node-03
a2.sources.s1.port = 45454
# define the c1
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# def the k1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = /flume/hdfs/collect
a2.sinks.k1.hdfs.filePrefix = hiveLog
a2.sinks.k1.hdfs.fileSuffix = .log
a2.sinks.k1.hdfs.fileType = DataStream
#source、channel、sink bond
a2.sources.s1.channels = c1
a2.sinks.k1.channel = c1
- 将程序分发给另外两台机器的flume
cd /export/servers/flume-1.6.0-cdh5.14.0-bin/userCase
scp collect.properties node-01:$PWD
scp collect.properties node-02:$PWD
- 测试运行
- 一定要先启动第三台机器的collect,先开放45454端口
bin/flume-ng agent -c conf/ -f userCase/collect.properties -n a2 -Dflume.root.logger=INFO,console
- 再启动第一台和第二台的采集程序
bin/flume-ng agent -c conf/ -f userCase/collect.properties -n a1 -Dflume.root.logger=INFO,console
- 测试往第一台和第二台机器上的日志文件中写入数据,观察是否都写入了HDFS