Python机器学习iris数据集KNN模型评估
KNN模型评估
- 一、分类问题介绍
- 二、K近邻分类模型(KNN)
-
- 1.模型介绍
- 2.KNN模型训练
- 3.KNN模型评估
-
- 评估1:将整个数据集用于训练与测试
- 评估2:分离训练数据与测试数据
一、分类问题介绍
分类:根据数据集目标的特征或属性,划分到已有的类别中。
特点:定性输出(输出的是代表某个类别),适用离散变量的预测,监督学习。
常用分类算法:K近邻(KNN)、逻辑回归、决策树、朴素贝叶斯
举例:
- Email:是否为垃圾邮件?
- 动物:识别图片动物是猫还是狗
- iris花:鸢尾花识别
iris数据集介绍
二、K近邻分类模型(KNN)
1.模型介绍
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的K个近邻(也就是上面所说的K个近邻),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
举例:
K=3,绿色圆点的最近的3 个邻居是2个红色小三角形和1个蓝色小正方形,判定绿色的待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近5个邻居是2个红色三角形和3个蓝色的正方形,判定绿色的待分类点属于蓝色的正方形一类。

2.KNN模型训练
分类任务:根据花的特征数据预测其所属的品种
使用分类模型:K近邻(k=1),K近邻(k=5)
加载 Iris 数据集并训练KNN模型
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
from sklearn.neighbors import KNeighborsClassifier
#假设k = 5
knn_5 = KNeighborsClassifier(n_neighbors= 5 )
knn_5.fit(x,y)
#假设k = 1
knn_1 = KNeighborsClassifier(n_neighbors= 1 )
knn_1.fit(x,y)
3.KNN模型评估
评估1:将整个数据集用于训练与测试
使用相同的数据集进行测试并通过对比预测结果与实际结果来评估模型表现
准确率
正确预测的比例
然而,训练数据与预测数据相同导致一下问题:
- 训练模型的最终目标是为了预测新数据对应的结果
- 最大化训练准确率通常会导致模型复杂化(比如增加维度),因此将降低模型的通用性。
- 过度复杂模型容易导致训练数据的过度拟合(绿色线)
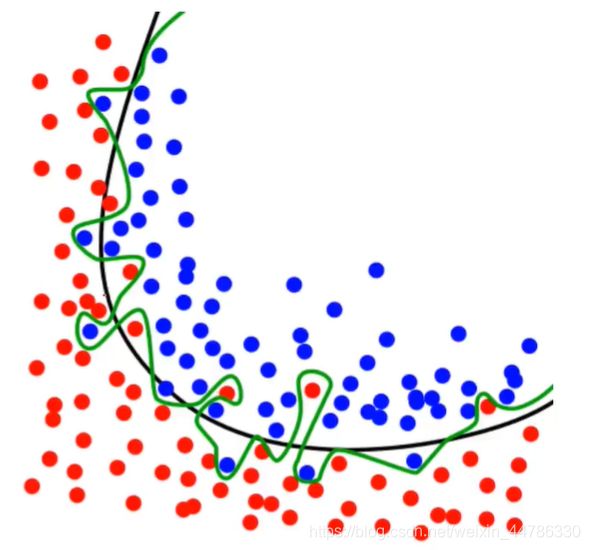
整体的数据集评估
from sklearn.metrics import accuracy_score
#k = 5,预测结果
y_pred = knn_5.predict(x)
#准确率:实际结果y 与 预测结果y_pred
print(accuracy_score(y,y_pred))
#若k = 1,它的准确率
y_pred = knn_1.predict(x)
print(accuracy_score(y,y_pred))
那么得到的k=5时的准确率好还是k=1时的准确率好呢?
所以我们要分离数据
评估2:分离训练数据与测试数据
- 把数据分成 训练集 和 测试集
- 使用 训练集 数据进行模型训练
- 使用 测试集 数据进行预测,从而评估模型表现

作用:
- 实现在不同的数据集上进行模型训练与预测
- 建立数据模型的目的是对新数据的预测,基于测试数据计算的准确率能更有效地评估模型表现
目标:确定合适的参数(组),提高模型预测准确率
方法:
1. 分离数据集
#分离前查看数据维度
print(x.shape)
print(y.shape)
#数据分离
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.4)
#分离后数据维度的确认
print(x_test.shape,x_train.shape)
print(y_test.shape,y_train.shape)2. 分离后数据集的训练和评估
#训练 训练集数据 和 测试集数据
knn_5_s = KNeighborsClassifier(n_neighbors= 5)
knn_5_s.fit(x_train,y_train)
y_train_pred = knn_5_s.predict(x_train)
y_test_pred = knn_5_s.predict(x_test)
#分离后模型预测和实际的结果
print(y_train_pred)
print(y_train)
print(y_test_pred)
print(y_test)
#分离后训练集预测准确率
print(accuracy_score(y_train,y_train_pred))
#分离后测试集预测准确率
print(accuracy_score(y_test,y_test_pred))3. 确认合适的k值(1-25)
#遍历所有可能的参数组合 k:1-25
k_range = list(range(1,26))
print(k_range)
#训练所有参数的模型以及预测结果和准确率的计算
score_train = []
score_test = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors= k )
knn.fit(x_train,y_train)
y_train_pred = knn.predict(x_train)
y_test_pred = knn.predict(x_test)
score_train.append(accuracy_score(y_train,y_train_pred))
score_test.append(accuracy_score(y_test,y_test_pred))
#每个参数k模型对应的训练集的所有准确率
for k in k_range:
print(k,score_train[k-1])
#每个参数k模型对应的测试集的所有准确率
for k in k_range:
print(k,score_test[k-1])4. 通过图形展示参数(组)与准确率的关系,确定合适的参数(组)
#图形展示
import matplotlib.pyplot as plt
# -*- coding: utf-8 -*-
%matplotlib inline
#展示K值与训练集预测准确率的关系
plt.plot(k_range,score_train)
plt.xlabel('K(KNN model)')
plt.ylabel('Training Accuracy')

#展示K值与测试集预测准确率的关系
plt.plot(k_range,score_test)
plt.xlabel('K(KNN model)')
plt.ylabel('Testing Accuracy')
- 训练集准确率 随着模型的复杂而提高
- 测试集准确率 在模型过于简单或过于复杂的情况下更低
- KNN模型中,模型的复杂度 由 k值决定 (K 越小,模型复杂度越高)
5. 使用合适的k值对新数据进行预测
从上面的准确率数据和图表中选取最合适的k值作为最佳模型进行预测
knn_8 = KNeighborsClassifier(n_neighbors= 8)
knn_8.fit(x_train,y_train )
knn_8.predict([[1,2,3,4]])
得到一个数组返回是 “1” ,也就是说花萼长度为1、花萼宽度为2、花瓣长度为3、花瓣宽度为4的鸢尾花,它的属种预测为:iris-virginica