整理背问到的面试题
目录
1.为什么采用redis而不是用hashmap?
2.同一个类中的两个方法都用synchronized修饰,线程是如何调用的?
3.spring是如何控制多线程并发问题的 ?
4.hashmap的底层结构
HashMap由数组+链表+红黑树进行数据的存储
HashMap和Hashtable的区别
HashMap 和 HashSet区别
HashSet如何检查重复
HashMap 的长度为什么是2的幂次方
HashMap为什么线程不安全
5.分布式锁,如何处理分布式问题
6.如何确保消息的幂等性(结合实际业务场景)
7.时间复杂度问题和空间复杂度问题
8.List遍历快速和安全失败
9.红黑树、平衡二叉树、数据结构相关知识
10.数组在jvm中是如何存储的
1.为什么采用redis而不是用hashmap?
hashmap是本地缓存而redis是分布式缓存
缓存一致性:因为hashmap是存储在内存中的。如果服务部署了多台实例,每一台实例在内存中都会存储一份缓存,这样会导致缓存一级性的问题,而redis是分布式缓存,只存取一份缓存信息确保了缓存一致性。
存储容量:redis可以存放几个g的缓存信息,但是hashmap是存储在内存中的 只能申请到有限的内存容量。
数据持久化:如果服务机宕机了,那么hashmap里面存储的缓存数据也会丢失。而redis不会,redis可以通过以下两种机制将信息持久化到磁盘中(RDB【默认】、AOF)
【扩展一下】:RDB和AOF两种redis持久化的机制
RDB(read DataBase):读快照,根据配置文件中的save设置的参数,按周期的将redis内存中的数据同步到磁盘中(dump.rdb),是redis默认的同步机制。
- 优点: 性能高,采用异步fork线程同步数据到磁盘中,不会影响主线程的读写操作。只会生成一个dump.rdb 的文件恢复快,相对于数据集大时,比 AOF 的启动效率更高。
- 缺点:因为是按周期同步,如果这个周期内redis宕机了,那么这一段时间内的数据也会丢失。
AOF(append only file): 每一次进行redis写入数据时,都会把这个数据同步到文件中,在redis重启时,通过该文件来恢复数据。
- 优点:数据安全性高,可以通过配置appendfsync属性,设置为always,这样每次写redis时,都会将数据写入到文件中。
- 缺点:AOF文件比RDB文件大,恢复起来耗时高。数据集大的时候,比 rdb 启动效率低。
2.同一个类中的两个方法都用synchronized修饰,线程是如何调用的?
锁方法(对象锁——每个实例都有的)
(同一个对象调用的前提)方法a、方法b都用synchronized修饰,线程a调用a方法拿到这个对象的
锁,那么线程b调用b方法是否能成功?
不能,因为synchronized修饰方法时候,锁是加在对象上的,正对同一个对象只有一把锁,如果线程a,获取到对象锁访问a方法,那么线程b想用调用b方法的时候就必须等待a线程是否锁。但是可以调用该对象的其他的非同步的方法。或者如果不是一个对象实例的话,也可以调用到。
锁类(synchronized修饰静态方法——类锁)
实际上就是调用该类的对象锁。因为静态方法是所有线程共享的,内存数据只有一份的,用synchronized修饰的静态方法,所有的线程访问时都需要线获取类的对象锁。
3.spring是如何控制多线程并发问题的 ?
1、可以将成员变量声明在方法内。
2、将成员变量放在ThreadLocal之中。
(ThreadLocal
成员变量放在ThreadLocal之中,传进来的参数是跟随线程的,所以也是线程安全的。
3、将bean设置为多例模式。(@Scope("prototype"))
多例模式,bean线程之间不共享就不会发生线程安全问题。会影响性能,不推荐
spring默认创建的bean是单例的
4、使用同步锁(会影响系统的吞吐量)
synchronized 修饰方法。
4.hashmap的底层结构
HashMap是基于哈希表的Map接口的非同步实现。元素以键值对的形式存放,并且允许null键和null值,因为key值唯一(不能重复),因此,null键只有一个。另外,hashmap不保证元素存储的顺序,是一种无序的,和放入的顺序并不相同(此类不保证映射的顺序,特别是它不保证该顺序恒久不变)。HashMap是线程不安全的。
jdk1.8相关属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 默认的初始容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //加载因子
static final int TREEIFY_THRESHOLD = 8; //链表长度的阈值,当超过8时,会进行树化(不绝对,如下面源码分析)
static final int UNTREEIFY_THRESHOLD = 6; //当树中只有6个或以下,转化为链表
transient int size; //HashMap的大小
int threshold; //判断是否扩容的阈值
Note:HashMap的扩容操作是一项很耗时的任务,所以如果能估算Map的容量,最好给它一个默认初始值,避免进行多次扩容。HashMap的线程是不安全的,多线程环境中推荐是ConcurrentHashMap
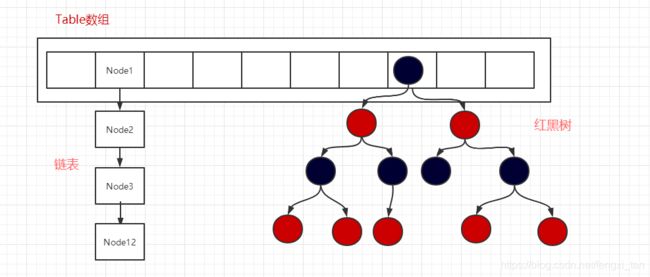
HashMap由数组+链表+红黑树进行数据的存储
HashMap采用table数组存储Key-Value的,每一个键值对组成了一个Node节点(JDK1.7为Entry实体,因为jdk1.8加入了红黑树,所以改为Node)。Node节点实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Node节点,以此来解决Hash冲突的问题。
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,。主要的区别有:
对Null key 和Null value的支持:HashMap可以接受为null的键值(key)和值(value),Hashtable不能接受null值,会产生空指针异常。
线程是否安全: HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的
效率: 由于Hashtable是线程安全的,所以在单线程环境下比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
初始容量大小和每次扩充容量大小的不同:HashMap初始大小为16,扩容为2的幂次方;HashTable初始为11,扩容为2n+1
底层结构:HashMap会将链表长度大于阈值是转化为红黑树(会先判断当前数组的长度是否小于 64,是则扩容,而不转化),将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashMap 和 HashSet区别
HashSet 底层就是基于 HashMap 实现的。(HashSet的对象相当于存储在HashMap的Key上,所以保证了唯一性)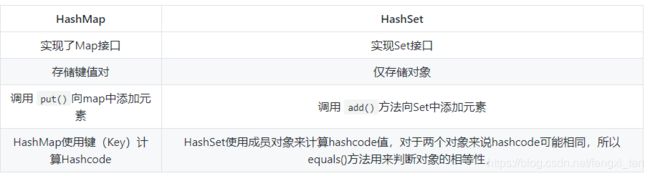
HashSet如何检查重复
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
hashCode()与equals()的相关规定:
如果两个对象相等,则hashcode一定也是相同的
两个对象相等,对两个equals方法返回true
两个对象有相同的hashcode值,它们也不一定是相等的
综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与equals的区别:
==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
==是指对内存地址进行比较 equals()是对字符串的内容进行比较
==指引用是否相同 equals()指的是值是否相同
HashMap 的长度为什么是2的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。因此,我们首先用hash对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标 hash%tab.length。但是,当数组的长度为2的幂次方时,hash%tab.length等价于hash&(tab.lenngth-1)。(取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作)。并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
HashMap为什么线程不安全
JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了,同时也伴随着数据丢失。
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
改善:
数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到HashMap#transfer(),因为JDK1.8直接在HashMap#resize()中完成了数据迁移。
HashMap线程不安全的体现:
JDK1.7 HashMap线程不安全体现在:死循环、数据丢失
JDK1.8 HashMap线程不安全体现在:数据覆盖
5.分布式锁,如何处理分布式问题
6.如何确保消息的幂等性(结合实际业务场景)
- 乐观锁
- 业务数据层面的校验(如果不支持存放乐观锁数据信息,采用这种方式)
- 其次再考虑兜底策略(需要结合实际业务场景给出解决方案)
7.时间复杂度问题和空间复杂度问题
8.List遍历快速和安全失败
fail—fast:快速失败
当异常产生时,直接抛出异常,程序终止;
fail-fast主要是体现在当我们在遍历集合元素的时候,经常会使用迭代器,但在迭代器遍历元素的过程中,如果集合的结构(modCount)被改变的话,就会抛出异常ConcurrentModificationException,防止继续遍历。这就是所谓的快速失败机制。
fail—safe:安全失败
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。由于在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。
缺点:基于拷贝内容的优点是避免了ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
9.红黑树、平衡二叉树、数据结构相关知识
10.数组在jvm中是如何存储的
数组也是相当于实力对象,实际上的值是存放在堆中,在虚拟机栈中的局部变量中会存储java的八大基础类型,以及数据的引用(reference)。而数组的引用也存放在reference中。至于如何获取堆中的数据分为两种访问形式:
1.句柄访问对象,java会在堆中划分出一部分区域作为句柄池,里面存放了对象实例的指针和对象类型指针。对象实例指针存放在堆中,对象类型指针存放在方法区里。
2.直接指针访问对象,具体指向的就是对象实例,在对象实例中存放了对象类型指针。这样做方便效率更高,但是对象移动(垃圾回收)需要一起调动,而句柄访问对象 ,只需要更改地址引用即可。