淘宝分布式文件系统核心储存引擎学习总结
淘宝分布式文件系统核心储存引擎学习总结
-
- 一.项目介绍
-
- 1.什么是分布式系统
- 2.什么是TFS系统
-
- 什么是 HA 架构
- 什么是平滑扩容
- 3.采用大文件储存数据
- 4.索引文件
- 5.将索引文件映射到内存
-
- mmap()函数
- 二.基本数据结构介绍
-
- 1.块文件信息结构体
- 2.索引信息结构体
- 3.小文件信息结构体
- 三.内存映射类——MMapFile
-
- 1.主要功能
- 2.基本方法
- 四.文件操作类——FileOperation
-
- 1.主要功能
- 2.基本方法
- 3.代码解析
- 五.文件内存映射操作类——MMapFileOperation
-
- 1.主要功能
- 2.基本方法
- 六.索引处理类——IndexHandle
-
- 1.主要功能
- 2.基本方法
- 3.具体函数解析
-
- 1.hash_find() 方法
- 2.hash_insert() 方法
- 3. write_segment_meta()方法
- 4.read_segment_meta()方法
- 5.int dalete_segment_meta()
- 七.源码获取
前言:水平有限,只能把自己了解的部分写出来,整个的架构还有一些不清楚的地方。
一.项目介绍
1.什么是分布式系统
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像是单个相关系统
在大数据时代,当一台主机已经无法存储海量数据了,同时一台主机也无法满足海量数据所带来的庞大计算量时,该怎么办呢?你可能会想到,可以扩展主机的容量,增强主机的计算能力。使之能够满足需求。这是一种方法,但一台主机的容量与计算能力受硬件限制终究是有上限的,不可能无限增加下去。且这样做有一个弊端,就是所有功能都集中在一台主机上,一旦这台主机出故障,那么主机对外的所有服务都将瘫痪。
于是人们想到,一台主机办不到的事,那就使用多台主机,并使用某种框架将多台主机联系起来,使它们可以相互通信,让它们在逻辑上成为一个主体,可以看成是一台主机。这样就能处理大量数据了。多台主机集合成的整体就可以看成是一个分布式系统
从功能上分,分布式系统又可分为分布式文件系统,分布式缓存系统与分布式数据库等。
什么是分布式文件系统呢?
摘自百度百科:
分布式文件系统(Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单的理解为一台计算机)相连;或是若干不同的逻辑磁盘分区或卷标组合在一起而形成的完整的有层次的文件系统。DFS为分布在网络上任意位置的资源提供一个逻辑上的树形文件系统结构,从而使用户访问分布在网络上的共享文件更加简便。单独的 DFS共享文件夹的作用是相对于通过网络上的其他共享文件夹的访问点 [1] 。
2.什么是TFS系统
摘自百度百科:
TFS(Taobao File System)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
什么是 HA 架构
HA 即 high available 的缩写,意为高可用。即两台服务器互为热备,一主一从,当主服务器出现故障,备份服务器立即切换为主服务器开始提供服务,保证向外的服务不会中断。HA 架构保障的是分布式系统的高可用性。
什么是平滑扩容
当提供数据服务的设备已无法满足当前的数据需求时,需要增加设备以提高容量,这就叫扩容。
扩容可以采用停机扩容,也可以采用平滑扩容。停机扩容即先暂停服务器对外提供的服务,等完成扩容再恢复。在停机扩容期间,用户是无法获取服务器服务的。
平滑扩容则不同,在平滑扩容期间,对外的服务照常进行。对用户来说,并不会察觉到任何异常。保障了系统的高可用性。
TFS的架构分为很多部分,这篇文章主要介绍 TFS 系统的储存引擎架构。
3.采用大文件储存数据
TFS系统是针对海量非结构化的数据设计的,它不视一个较小的,单独的,非结构化的数据为一个基本的储存管理单位,而是将小的数据集合成一个大的数据块,大的文件(一般是64MB),简称为块,并将其存放在一个文件中。
使用大文件的目的:
- 一是为了防止对磁盘的频繁读取,提高效率
- 二是为了防止频繁读取产生的内存碎片
- 三是为了减少过多的 Inode 节点对磁盘空间的占用
每一个主块文件都有若干扩展块(用来储存溢出的数据),还有一个对应的索引文件。主块文件,扩展文件与索引文件在逻辑上可以看成是一个整体。
主块文件各自拥有一个唯一的整数编号,它们之间通过整数编号进行区分。
4.索引文件
每一个主块文件都是由很多小文件组成的,那么怎么在主块文件快速中找到这些小文件呢?
答案是使用索引。索引通过索引文件实现。索引文件的结构被定义成了一个由文件实现的哈希链表,它的结构形似一个哈希链表,但因为是由文件实现的,所以在某些地方与由程序实现的哈希链表不同。
下图为一个程序中的哈希链表示意图:
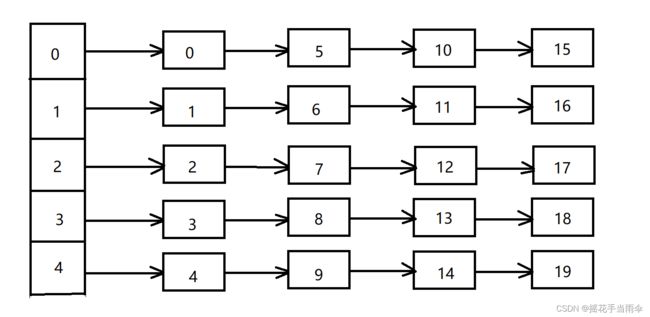
正常的哈希链表头部是一个指针数组,数组中存放的是指针,指向该哈希桶的第一个元素。各节点中除了有存放 value 的变量,还有一个 next 指针,指向该桶的下一个元素。
在TFS中,每一个小文件就相当于哈希链表中的一个节点,每个小文件拥有一个 id 作为它的键唯一标识它,采用取余法作为哈希函数,即 键 % 哈希桶数量 得到的就是哈希桶的数组索引,表示它储存在为该数组索引的哈希桶内。
特别需要注意的是程序中的哈希链表都是通过指针链接的,指针中储存的是地址,而索引文件实现的哈希链表是通过储存在 int 变量里的文件偏移来链接的。
5.将索引文件映射到内存
对操作系统相关知识熟悉的人应该知道,CPU 访问内存要比访问磁盘快成千上万倍。所以为了快速找到小文件在主块文件中的位置,我们可以将索引文件映射进内存,在内存中操作索引文件,以便更快地找到小文件位置,将数据读取出来。
我们使用 void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset) 函数进行内存映射。
这种思路让我想到操作系统里的快表,也是将关键信息储存在更快的,更靠近 CPU 的储存设备,以提高效率。
mmap()函数
理解下文内容前,需要先对操作系统的虚拟内存有一定了解。
引用与参考来源:《深入理解计算机系统》
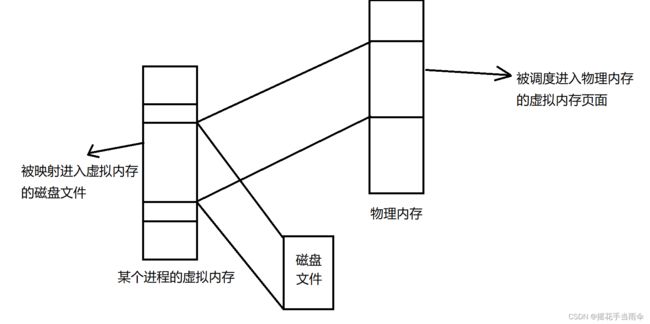
Linux 通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射。
mmap 函数有两种映射方式。一种是映射 Linux 文件系统中的普通文件:即将文件内容复制进入虚拟内存所在区域。但这些虚拟页面没有实际交换进入物理内存,直到 CPU 第一次引用到页面,操作系统才会将所需页面调度进入物理内存。
另一种方式是映射一个匿名文件到虚拟内存中。匿名文件是由内核创建的,包含的全是二进制零。通过这种方式映射得到的虚拟内存页面在调度进入内存时,磁盘与内存之间是没有数据交换的。
二.基本数据结构介绍
1.块文件信息结构体
用来记录块文件信息,每一个主块文件对应一个块id,对应一个块文件信息结构体。
struct BlockInfo{
int block_id_ = 0; //块文件编号
int version_; //版本号
int file_count_; //当前已保存文件总数
int size_; //当前已保存文件数据总大小
int del_file_count_; //已删除的文件数量
int del_size_; //已删除的文件数据总大小
int seq_no_; //下一个可分配的文件编号
};
2.索引信息结构体
便于索引文件插入或找到小文件信息的结构体。
struct IndexHeade{
BlockInfo block_info_; //块信息,储存主块的信息,每一个主块文件有且只有一个索引文件
int bucket_size_ = 0; //哈希桶大小,储存哈希桶个数
int data_file_offset_; //储存主块文件已使用空间的偏移
int index_file_size_; //储存索引文件可用来储存小块文件的起始位置
int free_head_offset_; //储存可重用的链表节点个数
};
3.小文件信息结构体
记录主块文件中的小文件在主块文件中的起始偏移的结构体,并且作为哈希链表中的链表节点使用。
struct MetaInfo{
int fileid_; //块id
struct{
int inner_offset_; //记录小文件在主块文件中的起始偏移
int size_; //小文件大小
} location_;
int next_mate_offset_; //记录在同一个哈希桶中的下一个小文件结构体的偏移量,类似于链表中的next指针
};
首先明确一点,因为索引文件是要进行内存映射的,并且映射内存区与索引文件保存一致,所以各种数据的相对位置在索引文件中与在映射内存区是一样的。对索引文件的修改会同步到对应的内存中。对内存的修改也会同步到索引文件中。
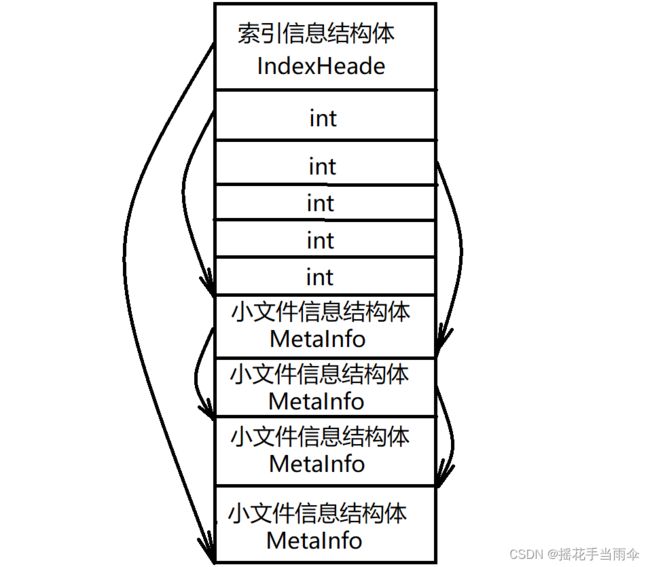
每当在主块文件中储存一个小文件时,都应该创建一个MeatInfo结构体标识该小文件,并且初始化它的各项参数。同时应该将这个结构体插入哈希链表中,即储存在该主块文件对应的索引文件中。索引文件头部储存的是索引信息结构体,接下来应该储存哈希桶索引。哈希桶索引之后是小文件信息结构体。
举个例子,如果我要创建一个哈希桶个数为 1000 的哈希链表,则在索引文件头部储存完索引信息结构体之后,还应该分配 1000 * 4 个字节的空间用作哈希链表索引。每四个字节当作一个 int 型整数,用来储存该哈希桶的第一个节点在索引文件中的起始偏移。如果一个小文件id为 5,则其数组索引为 5 % 1000 等于 5 ,所以这个小文件结构体就应该储存在索引为 5 的哈希桶中,即第五个 int 型整数对应的哈希桶。如果该索引为 0 ,则说明该桶中还不存在元素,所以在储存完小文件结构体之后,还应该把该桶的数组索引置为第一个元素的起始偏移。如果不为 0 ,说明该桶中已存在元素,则找到该桶中的最后一个节点,在储存完新的小文件结构体之后将原本的最后一个节点的 next_mate_offset_ 指向新插入节点的偏移。
这样讲可能不够直观,看一张图以便理解:
假设 IndexHeade 结构体占44个字节,MetaInfo 占 16 个字节,int 为 4 个字节,哈希桶数量为5个。
还是上面这张图,把关键数据显示出来。
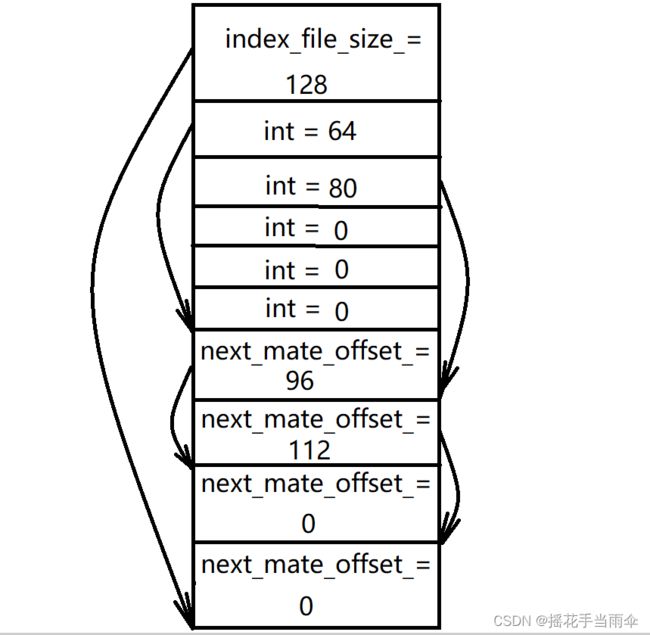
这里还存在一个小问题,我们知道了某个小文件信息结构体在索引文件中的偏移,那么我怎么把它取出来并使用它呢。
这个其实很简单,只需要创建一个临时的结构体,再使用 memcpy() 函数将映射内存区数据复制到该结构体中就能使用了。
三.内存映射类——MMapFile
1.主要功能
实现内存映射的相关操作,封装内存映射相关函数。
2.基本方法
- 构造函数——MMapFile(),有多个重载,其中一个要传入两个参数,第一个参数是一个结构体,该结构体中有进行内存映射时的一系列参数,第二个参数是文件操作符
- 执行内存映射——map_file()
- 重新执行内存映射(常用来扩容)——remap_file()
- 得到内存映射首地址——get_data()
- 得到内存映射大小——get_size()
- 解除内存映射——munmap_file()
- 将内存映射的内容同步到文件——ensure_file_size()
- 保持磁盘文件内容与内存映射区内容一致——sync_file()
四.文件操作类——FileOperation
1.主要功能
实现文件的基本操作,作为文件映射操作类的基类。
2.基本方法
- 构造函数——FileOperation(),传入两个参数一个是要打开的文件名另一个是打开文件的选项
- 关闭文件——close_file()
- 打开文件——open_file()
- 同步内存中所有已修改的文件数据到磁盘——flush_data()
- 读取文件中数据——pread_file()
- 将数据写入文件中——pwrite_file()
- 得到文件数据大小——get_file_size()
- 改变文件指针位置——seek_file()
- 得到文件操作符——get_fd()
3.代码解析
分析下面一段代码,虽然大部分是防御性编程,看起来似乎是有很多不必要的代码。但生产环境中的实战代码与我们平时写的代码是不一样的,在生产环境中,尤其是服务器端的代码,很多在平时编程中不会出现的情况在生产环境中都有可能出现。所以应该尽可能周全的考虑到所有可能的情况,并设置足够多的输出信息,确保任务日志足够完善。这样在出错时便于我们排查出错误。
下面函数的功能是读取文件中的数据并保存在参数buf中,nbytes是要读取数据的字节大小,offset是文件起始的偏移量。这个函数可以看成是了结合生产环境具体情况后对 pread64 函数的封装。
int FileOperation::pread_file(char* buf, const int32_t nbytes, const int64_t offset)
{
int32_t left = nbytes;
int64_t read_offset = offset;
int32_t read_len = 0;
char* p_tmp = buf;
int i = 0;
while (left > 0) //设置循化是因为可能不能一次全部读完,如果要分多次,每读取一部分数据就让left减去读取的数据,直至left等于0则表示全部读取完成
{
++i; //每读取一次计数加一,防止重复读取
if (i >= MAX_DISK_TIMES) //如果失败多次,停止读取,防止任务阻塞。如果因为硬件设备或其它原因导致读取不可能成功而又不设置结束条件的话,则会造成多任务阻塞,一直占用资源,这在资源紧张的服务器环境下是不能被接受的
{
break;
}
if (check_file() < 0) //检查文件是否存在
return -errno;
if ((read_len = ::pread64(fd_, p_tmp, left, read_offset)) < 0) //读取文件中数据,存放在p_tmp中
{
read_len = -errno; //保存errno,防止被其他线程修改
if (EINTR == -read_len || EAGAIN == -read_len) //如果是这俩种错误,则重新读取
{
continue; /* call pread64() again */
}
else if (EBADF == -read_len) //重新读取
{
fd_ = -1;
continue;
}
else //返回错误编号
{
return read_len;
}
}
else if (0 == read_len) //读取到全部数据,跳出循环
{
break; //reach end
}
left -= read_len; //读取到部分数据,再次读取
p_tmp += read_len;
read_offset += read_len;
}
if (0 != left) //读取错误,返回错误编号
{
return EXIT_DISK_OPER_INCOMPLETE;
}
return TFS_SUCCESS; //宏,表示成功
}
五.文件内存映射操作类——MMapFileOperation
1.主要功能
文件内存映射操作类继承自文件操作类,所以它拥有文件操作类的基本方法。并且持有一个内存映射类指针,用来进行内存映射。
它的主要功能是可以借助内存映射指针完成指定文件的内存映射。并且能使用继承自父类的方法读取文件内数据与往文件内写入数据。
2.基本方法
- 构造函数——MMapFileOperation(),需要传入两个参数,一个是要打开操作的文件名,另一个是打开文件时的参数
- 读取文件中数据——pread_file()(虚函数)
- 将数据写入文件中——pwrite_file()(虚函数)
- 执行内存映射——mmap_file()
- 解除内存映射——munmap_file()
- 得到内存映射首地址—— void* get_map_data() const
- 保持磁盘文件与共享内存区内容一致——flush_file()
- 以及从文件操作类继承的一些方法,不一一列举了
解释一下文件内存映射操作类的基本用法,首先实例化一个对象,它的构造函数需传入文件名与打开文件时的选项,如果带上O_CREAT选项则表示若此文件不存在则创建它。然后调用mmap_file()函数,该函数会对文件操作符fd_进行检测,如果它不是一个合法的值,则重新打开文件,给fd_赋值,确保fd_是一个合法值。然后该函数会检测实例化的对象持有的内存映射类指针是否是一个合法值,如果不是则实例化一个内存映射类对象并进行内存映射。如果是合法值则返回。
完成了文件的内存映射后,就可以读取文件数据或者往文件中写入数据。因为进行内存映射时设置的参数是保持文件与内存映射内存区的同步,所以对文件的修改会同步到对应的内存中。对内存的修改也会同步到文件中。
六.索引处理类——IndexHandle
1.主要功能
持有文件内存映射操作类指针,用来进行文件的内存映射,文件读写等功能。
实际上我们生成索引文件所需要的所有操作都只需要一个索引处理类对象就能完成。
下图表示上述四个类之间的关系:
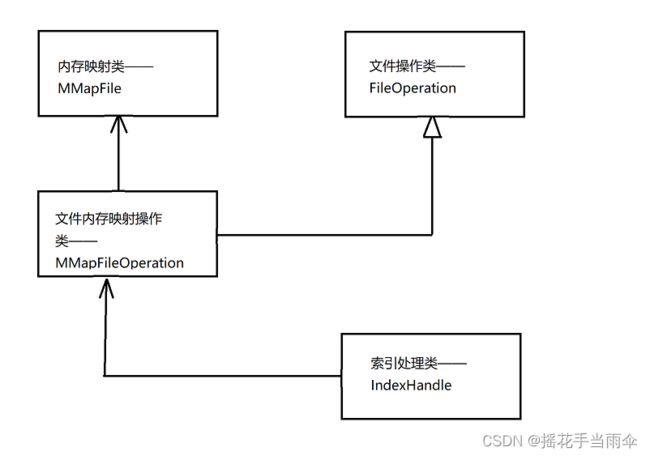
其中

代表持有某个类对象或该类对象指针(显然持有指针更节省空间)。

表示继承自某个类。
2.基本方法
- create()——初始化 IndexHeader 结构体的各种属性,并把它加载到索引文件中。
- load()——检测各项属性是否正确,进行内存映射。
- hash_find()——哈希查找,在索引文件中找到键值为 key(key 作为形参在函数调用时传入) 的节点
- hash_insert()——在索引文件中插入键值为 key 的节点。
- hash_compare()——比较 key 值是否与当前结构体 key 值一样(该函数第一个参数为 key 值,第二个参数为 MetaInfo 结构体)。
- write_segment_meta()——将节点写入索引文件。
- read_segment_meta()——从索引文件中找到节点。
- dalete_segment_meta()——删除索引文件中节点。
- update_block_info()——更新 BlockInfo 结构体信息。
- 以及其它一些获取 IndexHandle 结构体各种属性的方法。
3.具体函数解析
下面解析的几个函数,都是这个储存引擎的重点,可以这么说,理解了下面几个函数的原理及实现也就理解了这整个储存引擎的原理。
1.hash_find() 方法
int hash_find(const int key, int& current_offset, int& previous_offset);
主要用于在哈希链表中查找节点,它接收三个参数,第一个是要查找节点的 key 值,第二个是储存要查找的节点在索引文件中的偏移,第三个是储存要查找节点的上一个节点在索引文件中的偏移(因为我们操作的是哈希链表,所以获得要操作的节点的上一个节点是很有必要的)。
//根据key值找到索引节点,设置它当前的文件偏移与上一个节点的文件偏移
int IndexHandle::hash_find(const int key, int& current_offset, int& previous_offset)
{
// find bucket slot
int slot = static_cast<int> (key) % bucket_size(); //计算哈希索引
previous_offset = 0;
MetaInfo meta_info;
int ret = TFS_SUCCESS;
// find in the list
int tmp = bucket_slot()[slot];
//bucket_slot()[slot]
for (int pos = bucket_slot()[slot]; pos != 0;) //for 循化,遍历链表节点,找到节点
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&meta_info), sizeof(MetaInfo), pos); //将数据读入meta_info
if (TFS_SUCCESS != ret)
return ret;
if (hash_compare(key, meta_info.get_key())) //如果找到当前key,则当前元素存在,不用再插入
{
current_offset = pos; //用current_offset储存要查找节点的偏移
return TFS_SUCCESS; //查找成功,返回
}
previous_offset = pos; //保存当前节点的上一个节点的文件偏移
pos = meta_info.get_next_meta_offset(); //如果未找到,则继续找,类似与 next = pointer->next
}
return EXIT_META_NOT_FOUND_ERROR; //查找失败,返回
}
2.hash_insert() 方法
int hash_insert(const int slot, const int previous_offset, const MetaInfo& meta);
如果要插入一个节点,首先会先查找该节点是否存在在哈希链表内,如果存在则不用再次插入,如果不存在则插入。所以在执行 hash_insert() 方法之前会先调用 hash_find() 方法进行查找,然后根据hash_find() 方法的返回值决定怎么继续执行。
hash_find() 方法与hash_insert() 方法结合起来使用可以实现将新的小文件信息结构体写入索引文件。
这个函数接收三个参数,第一个是哈希索引,第二个在是执行 hash_find() 方法后储存在 previous_offset 中的要查找节点的上一个节点的值。如果它为零则证明当前哈希桶没有元素。不为零则可以用来链接节点。第三个参数接收要插入的小文件信息结构体。
int IndexHandle::hash_insert(const int slot, const int previous_offset, const MetaInfo& meta)
{
int ret = TFS_SUCCESS;
MetaInfo tmp_meta_info;
//memset(reinterpret_cast(&tmp_meta_info), 0, sizeof(MetaInfo));
int current_offset = 0; //可以插入节点的起始偏移
// get insert offset
// reuse the node in the free list
if (0 != index_header()->free_head_offset_) //如果有可重用的链表节点
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&tmp_meta_info), META_INFO_SIZE,
index_header()->free_head_offset_); //取出可重用的第一个节点
if (TFS_SUCCESS != ret)
return ret;
current_offset = index_header()->free_head_offset_;
index_header()->free_head_offset_ = tmp_meta_info.get_next_meta_offset(); //将 free_head_offset_ 的值修改为可重用节点的下一个节点
}
else // expand index file
{
current_offset = index_header()->index_file_size_;
index_header()->index_file_size_ += META_INFO_SIZE; //因为要插入节点,所以索引文件当前偏移要假一个 MetaInfo 节点大小
}
MetaInfo meta_info(meta);
ret = file_op_->pwrite_file(reinterpret_cast<const char*> (&meta_info), META_INFO_SIZE, current_offset); //插入要插入节点
if (TFS_SUCCESS != ret)
return ret;
// previous_offset the last elem in the list, modify node
if (0 != previous_offset) //如果哈希桶的第一个元素不为空,则串联起哈希链表
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&tmp_meta_info), META_INFO_SIZE, previous_offset);
if (TFS_SUCCESS != ret)
return ret;
tmp_meta_info.get_next_meta_offset() = current_offset;
ret = file_op_->pwrite_file(reinterpret_cast<const char*> (&tmp_meta_info), META_INFO_SIZE, previous_offset); //因为修改了上一个节点,所以将它重新写入索引文件
if (TFS_SUCCESS != ret)
return ret;
}
else //如果该桶中不存在元素,则哈希桶索引应指向该桶内第一个元素,即现在插入的元素
{
bucket_slot()[slot] = current_offset;
}
return TFS_SUCCESS;
}
3. write_segment_meta()方法
int write_segment_meta(const int key, const MetaInfo& meta);
将小文件信息结构体写入索引文件,其实就是实现了 hash_find() 与hash_insert() 两个方法的整合。
int IndexHandle::write_segment_meta(const int key, const MetaInfo& meta) //将小文件信息写入索引文件
{
int current_offset = 0, previous_offset = 0;
int ret = hash_find(key, current_offset, previous_offset); //先进行查找
if (TFS_SUCCESS == ret) // check not exists
{
return EXIT_META_UNEXPECT_FOUND_ERROR;
}
else if (EXIT_META_NOT_FOUND_ERROR != ret)
{
return ret;
}
int slot = static_cast<int> (key) % bucket_size();
return hash_insert(slot, previous_offset, meta); //插入节点
}
4.read_segment_meta()方法
int IndexHandle::read_segment_meta(const int key, MetaInfo& meta);
该函数的功能是读出指定节点,通过 hash_find() 方法可以很容易实现。
int IndexHandle::read_segment_meta(const int key, MetaInfo& meta)
{
int current_offset = 0, previous_offset = 0;
// find meta
int ret = hash_find(key, current_offset, previous_offset);
if (TFS_SUCCESS == ret) //exist
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&meta), META_INFO_SIZE, current_offset); //找到该节点,读入 meta 结构体
if (TFS_SUCCESS != ret)
return ret;
}
else
{
return ret;
}
return TFS_SUCCESS;
}
5.int dalete_segment_meta()
int dalete_segment_meta(const int key);
删除指定节点的函数,如果理解了上面函数的实现原理,这个函数可以自己实现出来,也算是一个小检测吧,检测一下自己是否真正掌握了上文的内容。
七.源码获取
TFS——文件储存引擎源码
完结撒花。