【redis学习篇】哨兵架构详解
一、哨兵架构概要
-
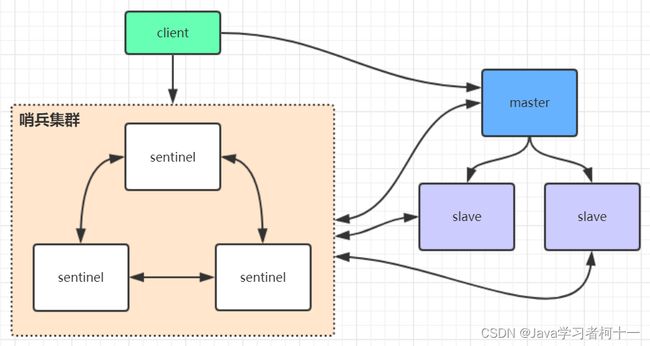
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。
-
sentinel实时监视主从集群,能实时知道哪个节点是主节点,哪些是从节点,哨兵架构下client端
第一次会访问sentinel,sentinel会将master信息推送给客户端,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点 -
当redis的主节点挂了,sentinel会在从节点中选取一个主节点 ,并且将新的redis主节点推送给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
搭建实例采用三个哨兵形成集群,三个数据节点(一主两从)方式搭建,如下图所示:

- Redis 主从架构就好比一个武当,掌门人就是 Master。掌门人如果挂了,需要从武当七侠里面 「选举」 能人担当掌门人。
- 这就需要一个部门能 「监控」 掌门人的生死和武当其他弟子的生命状态,并且能够通过 「投票」 从武当弟子中选举一个能者担任新掌门
- 接着再举行新闻 「发布」 会向世界宣布新掌门的信息。这个「部门」就是哨兵。
哨兵在选举新掌门会遇到以下几个问题:
- 如何判断掌门真的挂了,有可能假死;
- 到底选择哪一个武当子弟作为新掌门?
- 通过新闻发布会将新掌门的相关信息通知到所有武当弟子(slave 和 master)和整个武林(客户端)
哨兵部门主要负责的任务是:监控整个武当、选择新掌门,通知整个武当和整个武林。
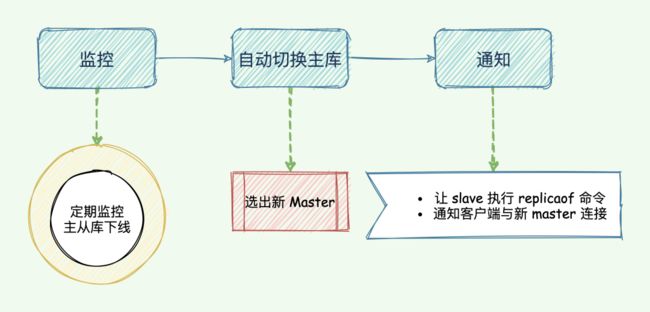
哨兵机制的主要任务
哨兵是 Redis 的一种运行模式,它专注于对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性。结合 Redis 的 官方文档,可以知道 Redis 哨兵具备的能力有如下几个:
- 监控:持续监控 master 、slave 是否处于预期工作状态。
- 自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。
- 通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
哨兵也是一个 Redis 进程,只是不对外提供读写服务,通常哨兵要配置成单数,为啥呢?且听「码哥字节」慢慢分析。
那到底「哨兵」这个神秘部门是如何实现这三个能力的?
我们先从全局观看哨兵,简要的了解整个运作流程,接着再针对每一个任务详细分析。首先从监控开始
监控
Sentinel 只是武当弟子中的特殊部门,在默认情况下,Sentinel 通过飞鸽传书以每秒一次的频率向所有武当弟子、掌门与哨兵(包括 Master、Slave、其他 Sentinel 在内)发送 PING 命令,如果 slave 没有在在规定时间内响应 PONG 命令给「哨兵」的 PING 命令,「哨兵」就认为这哥们 可能 嗝屁了,就会将他记录为「下线状态」;
假如 master 掌门没有在规定时间响应 「哨兵」的 PING 命令,哨兵就判定掌门下线,开始执行「自动切换 master 掌门」的流程。
哨兵如何判断「掌门」嗝屁呢?掌门诈尸咋办?
为了防止掌门「假死」,「哨兵」设计了「主观下线」和「客观下线」两种暗号。
1.1 主观下线
- 哨兵利用 PING 命令来检测掌门、 slave 的生命状态。如果是无效回复,哨兵就把这个哥们标记为「主观下线」。检测到的是武当小弟,也就是 slave 角色。那么就直接标记「主观下线」。
因为 master 掌门还在,slave 的嗝屁对整个武当影响不大。依然可以对外开会,比武论剑、吃香喝辣
- 如果检测到是 master 掌门完蛋,这时候哨兵不能这么简单的标记「主观下线」,开启新掌门选举。
因为有可能出现误判,掌门并没有嗝屁,一旦启动了掌门切换,后续的选主、通知开发布会,slave 花时间与新 master 同步数据都会消耗大量资源。
-
所以「哨兵」要 「降低误判」 的概率,误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。
-
既然一个人容易误判,那就 「多个人一起投票」 判断。哨兵机制也是类似的,采用多实例组成的集群模式进行部署,这就是哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
-
同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
1.2 客观下线
-
判断 master 是否下线不能只有一个「哨兵」说了算,只有 「过半」 的哨兵判断 master 已经「主观下线」,这时候才能将 master 标记为「客观下线」,也就是说这是一个客观事实,掌门真的嗝屁了,华佗再世也治不好了。
-
只有 master 被判定为「客观下线」,才会进一步触发哨兵开始主从切换流程。
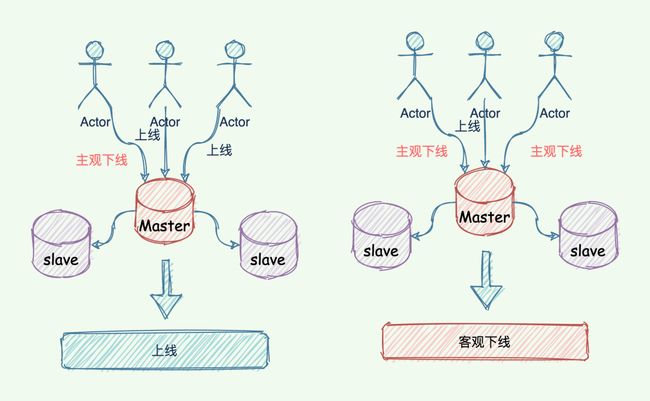
1.3 主观下线与客观下线的区别
简单来说,主观下线是哨兵自己认为节点宕机,而客观下线是不但哨兵自己认为节点宕机,而且该哨兵与其他哨兵沟通后,达到一定数量的哨兵都认为该哥们嗝屁了。
这里的「一定数量」是一个法定数量(Quorum),是由哨兵监控配置决定的,解释一下该配置:
# sentinel monitor <master-name> <master-host> <master-port> <quorum>
举例如下:
sentinel monitor mymaster 127.0.0.1 6379 2 这条配置项用于告知哨兵需要监听的主节点:
- sentinel monitor:代表监控。
- mymaster:代表主节点的名称,可以自定义。
- 192.168.11.128:代表监控的主节点 ip,6379 代表端口。
- 2:法定数量,代表只有两个或两个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
「客观下线」的标准就是,当有 N 个哨兵实例时,要有 N/2 + 1 个实例判断 master 为「主观下线」,才能最终判定 Master 为「客观下线」,其实就是过半机制。
1.4 自动切换主库
既然判断 master 客观下线了,那就要从选出一个新掌门人了。
「哨兵」的第二个任务,选择新 master 掌门。需要从武当弟子中按照一定规则选择一个牛逼人物作为新掌门,完成选任掌门后,新 master 带领众弟子一起吃香喝辣。
按照一定的 「筛选条件」 + 「打分」 策略,选出「最强王者」担任掌门,也就是通过一些条件海选过滤一些「无能之辈」,接着将通过海选的靓仔全都打分排名,将最高者选为新 master。
如图所示:

网络经常断开的也不可取,你想,即使变成 master,可是很快网络出了故障,又得重新选择新 master,这不闹着玩么,得排除掉!
筛选条件
- 从库当前在线状态,下线的直接丢弃;
- 评估之前的网络连接状态 down-after-milliseconds * 10:如果从库总是和主库断连,而且断连次数超出了一定的阈值(10 次),我们就有理由相信,这个从库的网络状况并不是太好,就可以把这个从库筛掉了。
打分
过滤掉不合适的 slave 之后,则进入打分环节。打分会按照三个规则进行三轮打分,规则分别为:
- slave 优先级,通过 slave-priority 配置项,给不同的从库设置不同优先级(后台有人没办法),优先级高的直接晋级为新 master 掌门。
- slave_repl_offset与 master_repl_offset进度差距(谁的武功与之前掌门的功夫越接近谁就更牛逼),如果都一样,那就继续下一个规则。其实就是比较 slave 与旧 master 复制进度的差距;
- slave runID,在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库。(论资排辈,根据 runID 的创建时间来判断,时间早的上位);
通知
重新选举新 master 掌门这种事情,何等大事,怎能不告知天下。再者其他 slave 弟子也要知道新掌门是谁,一起追随新掌门吃香喝辣大保健。
最后一个任务,「哨兵」将新 「master 掌门」的连接信息发送给其他 slave 武当弟子,并且让 slave 执行 replacaof 命令,和新「master 掌门」建立连接,并进行数据复制学习新掌门的所有武功。
除此之外,「哨兵」还需要将新掌门的 **「连接信息」**通知整个武林(客户端),使得让所有想拜访、讨教的人能找到新任掌门,这样诸多事宜才能交给新掌门做决定(将读写请求转移到新 master)。
哨兵的主要任务与实现目标
二、 哨兵leader选举流程
-
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。
-
每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。
-
如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。
-
哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。
-
不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。
三、 redis哨兵架构搭建步骤
1、复制一份sentinel.conf文件
cp sentinel.conf sentinel-26379.conf
2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.3/data"
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster这个名字随便取,客户端访问时会用到
3、启动sentinel哨兵实例
src/redis-sentinel sentinel-26379.conf
4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已经识别出了redis的主从
5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
6、sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的最下面),我们查看下如下配置文件sentinel-26379.conf,如下所示:
sentinel known-replica mymaster 192.168.0.60 6380 #代表redis主节点的从节点信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表redis主节点的从节点信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵节点
7、当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel文件里的集群元数据信息会变成如下所示:
sentinel known-replica mymaster 192.168.0.60 6379 #代表主节点的从节点信息
sentinel known-replica mymaster 192.168.0.60 6381 #代表主节点的从节点信息
sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵节点
8、同时还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380
sentinel monitor mymaster 192.168.0.60 6380 2
9、当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点加入集群
四、 整合spring boot 测试
哨兵的Spring Boot整合Redis连接代码见示例项目:redis-sentinel-cluster
- 引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
- springboot项目核心配置
server:
port: 8080
spring:
redis:
database: 0
timeout: 3000
sentinel: #哨兵模式
master: mymaster #主服务器所在集群名称
nodes: 192.168.0.60:26379,192.168.0.60:26380,192.168.0.60:26381
lettuce:
pool:
max-idle: 50
min-idle: 10
max-active: 100
max-wait: 1000
- 测试代码
@RestController
public class IndexController {
private static final Logger logger = LoggerFactory.getLogger(IndexController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到
* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,
* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的masterip
*
* @throws InterruptedException
*/
@RequestMapping("/test_sentinel")
public void testSentinel() throws InterruptedException {
int i = 1;
while (true){
try {
stringRedisTemplate.opsForValue().set("zhuge"+i, i+"");
System.out.println("设置key:"+ "zhuge" + i);
i++;
Thread.sleep(1000);
}catch (Exception e){
logger.error("错误:", e);
}
}
}
}