HBase基础原理知识(为什么使用HBase + HBase结构(ZooKeeper、RegionServer等) + 架构图),非常适合初学者和基础不清晰的朋友
HBase学习
这些基础知识可以说是HBase学习必不可少的知识,因为我没有学扎实吃了不少亏。
希望读者可以耐心看完,真的很好理解!没有想象的那么困难!
随着学习的深入我也会慢慢更新文章的内容,如果对你有帮助的话可以点个关注❤️
初识HBase
1、为什么使用HBase
基于Hadoop衍生出来的HBase存储,可以实现高吞吐量的数据集应用程序。HBase采用Key/Value的存储方式,即使数据量增大,也几乎不会导致查询性能的下降。
HBase并不快,只是当数据量很大的时候它慢的不明显
数据分析是HBase的弱项,因为它基本不支持表的关联,group by或order by的实现非常复杂。
所以当你的大体情况符合以下任意一种情况:
- 主要需求是数据分析,比如报表
- 单表数据不超过千万
建议使用Mysql之类的产品,避免脑细胞死的过多
当你的情况是:
- 单表数据超过千万,并发还挺高
- 数据分析需求较弱,或者不需要那么灵活或者实时
使用HBase不会让你失望
2、HBase的基本架构
部署架构
从HBase部署架构来说,HBase有两种服务器:Master服务器和RegionServer服务器
一般的HBase集群有一个Master服务器和多个RegionServer服务器。Master服务器负责维护表的结构信息,实际数据都存储在RegionServer服务器上
HBase特殊性:客户端获取数据由客户端直接连接RegionServer,当Master挂掉后依然可以查询数据,就是不能建新表。
RegionServer是直接负责存储数据的服务器,存储在Hadoop的HDFS上,如图:
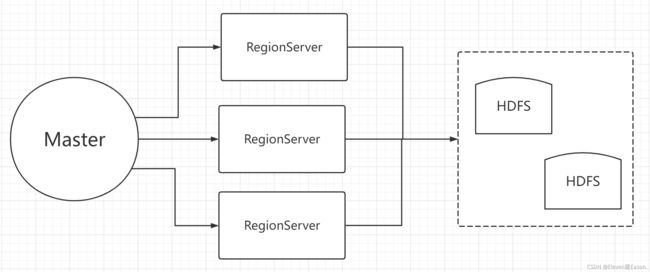
Region非常依赖ZooKeeper服务,可以说没有ZooKeeper就没有HBase。ZooKeeper就像管家一样管理了HBase所有RegionServer的信息,包括具体的数据段存放在哪个RegionServer上。
客户端每次与HBase连接,都是先和ZooKeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer。
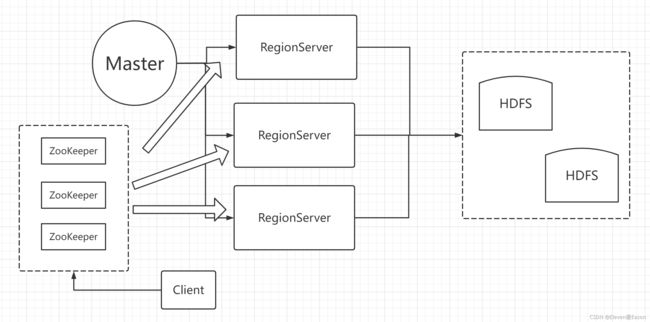
这是HBase的整体架构。
Region是什么?
Region就是一段数据的集合。HBase一般有一个到多个Region。
- region不能跨服务器,一个RegionServer上有一个或多个Region。
- 数据量大的时候HBase会拆分Region
- HBase进行负载均衡时也可能会从一台RegionServer上把Region移动到另一台RegionServer上
- Region是基于HDFS的,它的所有数据存取操着都是调用了HDFS的客户端接口来实现的
RegionServer是什么?
存放Region的容器,直观点来说就是服务器上的一个服务,一般来说一个服务器就装一个RegionServer。
当客户端从ZooKeeper获取RegionServer的地址后,会直接从RegionServer获取数据
Master是什么?
和它的名字不太一样,它不是HBase的领导,相反,它有点像是个打杂的。Master只负责各种协调工作,比如建表、删表、移动Region、合并等操作。这些操作的共性是需要跨越RegionServer,由哪个RegionServer来执行都不合适,所以就将这些操作放在了Master上。
这种结构的好处是大大降低了集群对Master的依赖。如果Master宕机了,集群依然可以正常的运行,依然可以存储和删除数据。
存储架构
这里卡了我很久,对传统数据库存储方式的根深蒂固让我无法一下子接受,需要一点时间才能体会到HBase存储的精髓。
HBase的最基本存储单位是列(column),一个列和多个列形成一行(row)。与传统数据库不同的是,它的行和列可以完全不一样!
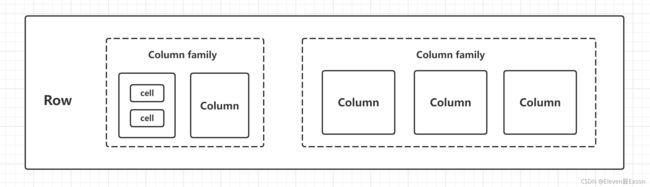
上图是HBase的存储结构,每个列有多个版本,多个版本的值存放在单元格(cell),下图是实列:

多个列可以汇总成一个列族
行键
每个行都有唯一的行键(row key)来标定这行的唯一性。这个row key完全由用户指定的一串不重复的字符串。rowkey会直接决定row的存储位置。系统永远是根据rowkey来排序(根据字典排序)。比如以下三个key
- row-1
- row-2
- row-11
排序后:
- row-1
- row-11
- row-2
如果输入的rowkey已经存在,则会更新之前存在的row,之前已经存在的值会被放到这个单元格的历史记录里面,并且不会被丢弃,只不过需要带上版本参数才能找到这个被丢弃的值。
什么是单元格?
一个列上可以存放多个版本的单元格。是数据存储的最小单元。
列族
若干个列可以组成一个列族(column family)。
同一列族内的所有列都有相同的属性,因为他们都在一个列族里,而属性都是定义在列族上的。
一个没有列族的表是没有意义的,列必须依赖列族存在。
列族存在的意义是:HBase会把相同列族的列尽量放在同一台机器上。
官方建议:列族越少越好。没有必要设置过多的列族。列族太多会极大程度的降低数据库性能;而且根据目前HBase的实现,列族定的太多,容易出BUG。
单元格
(行键:列族:列)可以确定唯一值吗?
当然不可以,因为一个单元格可能会有多个版本,我们用版本号(Version)来区分。所以唯一确定一条结果的表达式应该是(行:列族:列:版本号)。
不过版本号可以省略。不写版本号默认是最后一个版本的数据返回。
这里的版本号就是时间戳(timestamp)
Region跟行的关系
一个Region就是多个行的集合。在Region中行的排序按照行键(rowkey)字典排序
和关系数据库的对比
我们通过图片来对比
关系行数据库
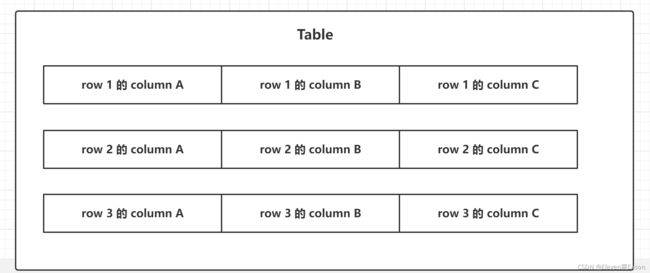
其中每个行都是不可分割的,也就是说三个列必须在一起,而且要被存储到同一台机器上,甚至是同一个文件里。
HBase表结构
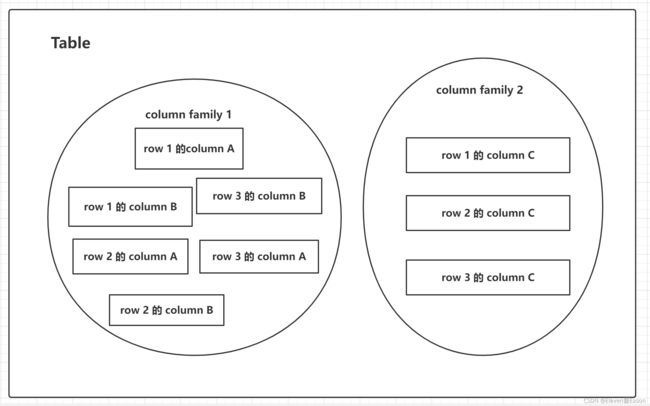
HBase中每个行都是离散的。由于列族的存在,所以一个行里不同的列甚至被分配到不同的服务器上。行的概念被减弱到只有一个抽象的存在。行键(rowkey)是行概念在HBase中唯一的体现。
2021年12月27日更新
新写了篇文章,可以加深大家对HBase的理解:HBase举例理解