Hive SQL语句操作
Hive SQL语句操作
- 一、 任务描述
- 二、 任务目标
- 三、 任务环境
- 四、 任务分析
-
- 1. 大数据离线处理特点
- 2. HDFS
- 3. Yarn 框架的组件功能
- 4. Hive
- 五、 任务实施
-
- 步骤1、新建hql文件
- 步骤2、hive中执行此文件
- 步骤3、向表中插入数据
- 步骤4、Select语句查询详解
- 步骤5、使用列值进行计算
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计5113字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿
一、 任务描述
本实验任务主要完成基于Hive环境执行一些常用的Hive SQL语句操作,通过完成本实验任务,要求学生熟练掌握Hive SQL的常用语句,掌握Hive的基础和操作。
二、 任务目标
掌握Hive的数据类型
掌握hive的数据类型的使用
掌握hive的DDL语句的操作
三、 任务环境
本次环境是:Ubuntu16.04+hadoop-2.7.3.+apache-hive-1.2.2-bin
四、 任务分析
1. 大数据离线处理特点
数据量巨大且保存时间长;
在大量数据上进行复杂的批量运算;
数据在计算之前已经完全到位,不会发生变化;
能够方便的查询批量计算的结果;
不像在线计算当前呈现的各种框架和架构,离线处理目前技术上已经成熟,大家使用的均是:使用Hdfs存储数据,使用MapReduce做批量计算,计算完成的数据如需数据仓库的存储,直接存入Hive,然后从Hive 进行展现。
2. HDFS
Hdfs 是一种分布式文件系统,和任何文件系统一样Hdfs提供文件的读取,写入,删除等操作。Hdfs 是能够很好的解决离线处理中需要存储大量数据的要求Hdfs和本地文件系统的区别如下:
- Hdfs 不支持随机读写;
- Hdfs 是分布式文件系统,支持数据多备份;
Hdfs 多备份数据存放策略: 第一个副本放在和client一样的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node);第二个副本放置在与第一个节点不同的机架中的node中(随机选择);第三个副本和第二个在同一个机架,随机放在不同的node中。如果还有更多的副本就随机放在集群的node里。
MapReduce 是一种分布式批量计算框架,分为 Map 阶段和 Reduce 阶段。 MapReduce能够很好的解决离线处理中需要进行大量计算的要求。 MapReduce从出现到现在经历了第一代MapReduce v1 和 第二代MapReduce Yarn。
Yarn 框架相对于老的 MapReduce 框架有以下优势:
- Hdfs 是分布式文件系统,支持数据多备份;
-
- 减小了 JobTracker的资源消耗,之前JobTracker既负责资源分配,也负责任务监控,Yarn 将这两项任务分别交给了ResourceManager 和ApplicationMaster ,减少了之前 JobTracker 单点失败的风险;
-
- 现在大部分使用 YARN
3. Yarn 框架的组件功能
• ResourceManager: 负责资源的调度,由两个组件组成:调度器和应用管理 ApplicationsManager (ASM) ;
• ApplicationsManager (ASM) :主要用于管理AM;
• ApplicationMaster (AM) :主要用于管理其对应的应用程序,如MapReduce作业,DAG作业等;
• NodeManager (NM):主要用于管理某个节点上的task和资源;
• Container :容器中封装了机器资源,如内存,CPU, 磁盘,网络等,每个任务会被分配一个容器,该任务只能在该容器中执行,并使用该容器封装的资源
4. Hive
Hive 是一种数据仓库,Hive中的数据存储于文件系统( 大部分使用 Hdfs),Hive 提供了方便的访问数据仓库中数据的HQL方法,该方法将SQL翻译成MapReduce。能够很好的解决离线处理中需要对批量处理结果的查询。
Hive是对MapReduce和HDFS的高级封装,本身不存储表等相关信息。
Hive 将元数据存放在 metastore 中, Hive 的 metastore 有三种工作方式:
- 内嵌Derby方式: 在同一时间只能有一个进程连接使用数据库;
- Local方式 : 使用本地MySQL数据库存储元数据;
- Remote方式: 使用远程已经搭建完成的 Mysql 数据库存储元数据;
♥ 知识链接
数据模型

实验所需数据和格式如下:
employees.txt内容
John Doe,100000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1 Michigan Ave.|Chicago|IL|60600
Mary Smith,100000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1MichiganAve.|Chicago|IL|60601
Todd Jones,800000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1MichiganAve.|Chicago|IL|60603
Bill King,800000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1 Michigan Ave.|Chicago|IL|60605
Boss Man,100000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1 Michigan Ave.|Chicago|IL|60604
Fred Finance,800000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1 Michigan Ave.|Chicago|IL|60400
Stacy Accountant,800000.0,Mary Smith|Todd Jones,Federal Taxes:.2|State Taxes:.05|Insurance:.1,1 Michigan Ave.|Chicago|IL|60300
五、 任务实施
步骤1、新建hql文件
新建hql文件,在命令终端分别执行命令:cd /simple/和touch create.hql,如图1所示。

图1 创建文件
向其中写入hql语句,在命令终端中,在/simple目录下执行命令:vim create.hql, 向其中添加以下语句
1.
2. create table employee(
3.
4. name string,
5.
6. salary float,
7.
8. subordinate array<string>,
9.
10. deduction map<string,float>,
11.
12. address struct<street:string,city:string,state:string,zip:int>
13.
14. )
15.
16. row format delimited fields terminated by ","
17. collection items terminated by "|"
18. map keys terminated by ":";
最终创建如图2所示。
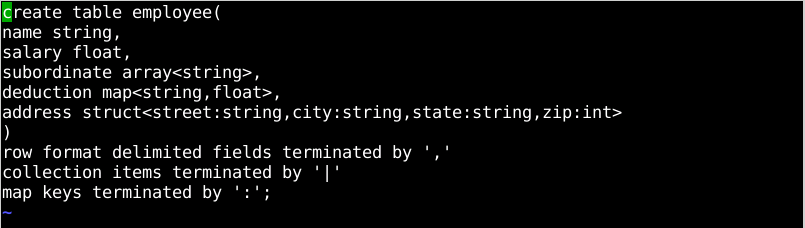
图2 代码显示
步骤2、hive中执行此文件
执行命令:service mysql start启动mysql服务,然后执行命令:start-all.sh启动hadoop,如图3所示。

图3 启动hadoop服务
执行命令:cd /simple/hive/bin进入hive的安装目录bin下,执行命令:./hive启动hive终端,如图4所示。

图4 进入hive shell界面
hive命令行中执行以下语句:source /simple/create.hql; 如图5所示。

图5 在hive中执行文件创建表
可以看出创建成功。
步骤3、向表中插入数据
通过load命令向表中加载本地数据,如图6所示。

图6 向表中加载数据
步骤4、Select语句查询详解
使用索引查询集合数据类型中的元素。数组索引是基于0的,这和java中是一样的,下面是选择subordinate数组中的第一个元素的查询,如图7所示。
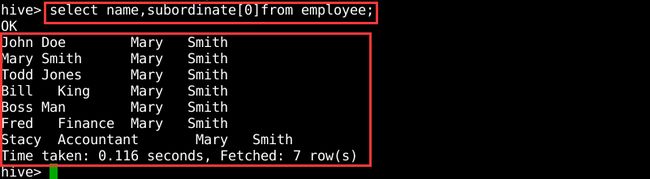
图7 查询数组数据
引用map类型中的一个元素。用户可以使用ARRAY[…]语法,但是使用的是键值而不是整数索引,如图8所示。
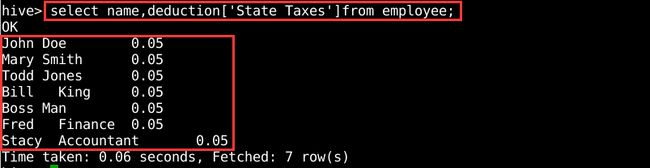
图8 查询map数据
引用struct中的一个元素,用户可以使用“.“符号,如图9所示。
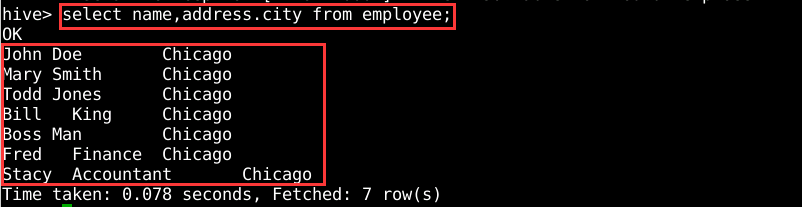
图9 查询struct数据
步骤5、使用列值进行计算
使用group by计算门牌号相同的雇员的总薪水,执行命令”select address.zip,sum(salary) from employee group by address.zip;”,如图10所示。
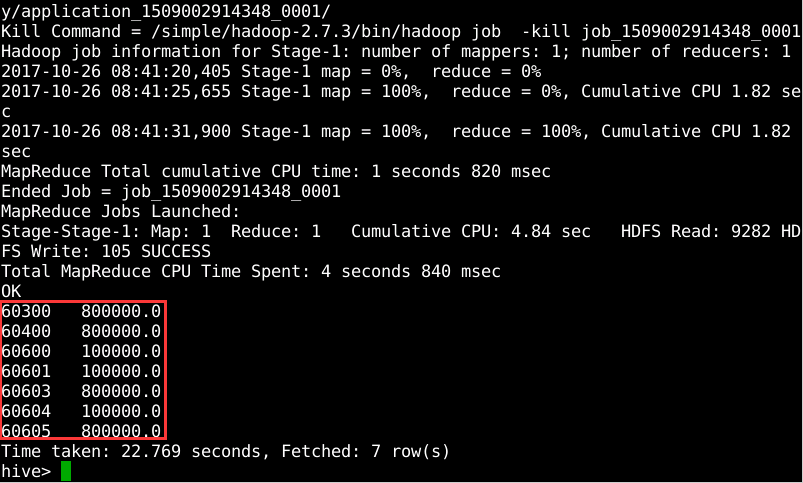
图10 门牌号相同的雇员的总薪水
使用group by 计算不同州的员工的平均薪水,执行命令”select address.state,avg(salary) from employee group by address.state;”,如图11所示。

图11 不同州的员工的平均薪水
可以看出,现在表中所有员工都位于IL州,所以最终结果只有一条记录。
使用group by 计算不同城市的员工的平均薪水,执行命令”select address.city,avg(salary) from employee group by address.city;”,如图12所示。
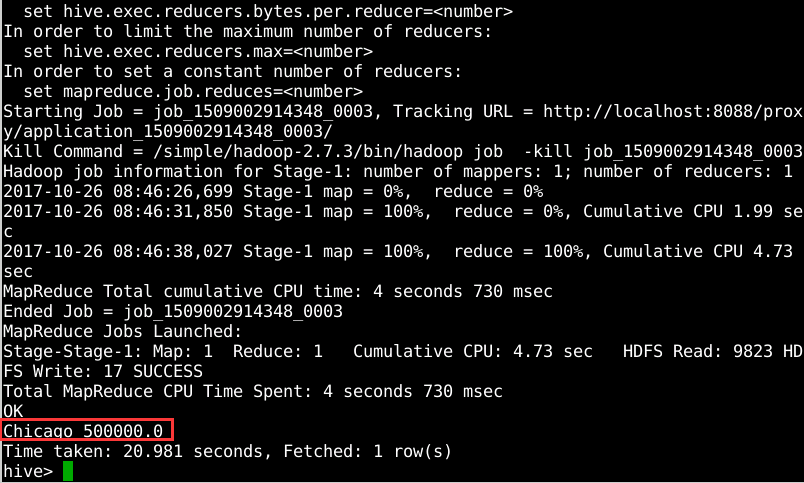
图12 不同城市的员工的平均薪水
