python 正则化表达式和泛型函数的使用及异常
目录
一、正则表达式
3.1匹配函数
3.2检索和替换
3.3正则表达式对象
二、常用方法使用
三、泛型函数的使用
四、上下文管理器
五、装饰器
六、异常
6.1抛出和捕获异常
一、正则表达式
正则表达式是一个特殊的字符序列,它帮助检查一个字符串是否与某种模式匹配
python中增加了re 模块,使 Python 语言拥有全部的正则表达式功能
- re.match():从字符串起始位置匹配,不成功则返回 none。
- re.search():匹配整个字符串,直到找到一个匹配。
- re.groups():返回匹配的表达式
- re.sub():用于替换字符串中的匹配项。
- re.compile ():用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
- re.finditer():在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
- re.split():匹配的子串将字符串分割后返回列表
(1)特殊字符类及其表示含义

(2)字符类

(3)正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。多数字母和数字前加一个反斜杠时会拥有不同的含义。标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。反斜杠本身需要使用反斜杠转义(\\)。由于正则表达式通常都包含反斜杠,所以最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 '\\t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
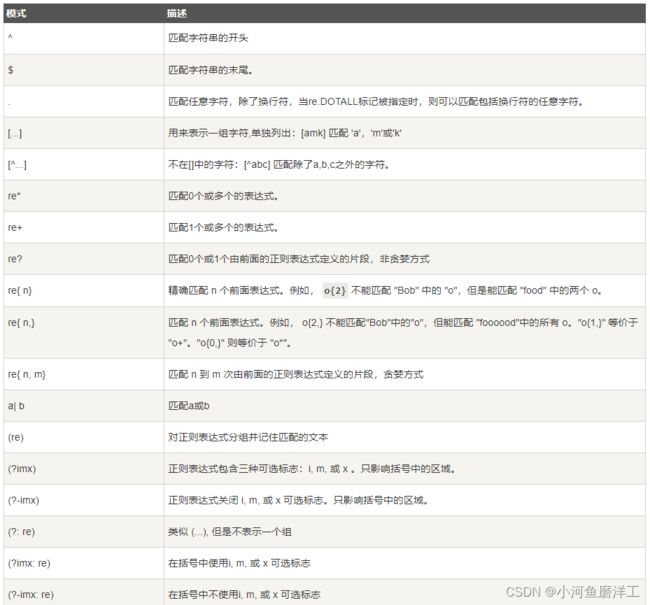
3.1匹配函数
(1)re.match函数
从字符串的起始位置匹配一个模式,匹配成功,则输出该字符的区间(前闭后开),若不是起始位置匹配成功的话,match() 就返回 none。
re.match(pattern, string, flags=0) #pattern:匹配的正则表达式;import re #导入模块
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 输出(0,3)
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配 输出None使用匹配对象函数来获取匹配表达式:
- group(num): 获取对应num下标的元素;
- group() 获取所有元素。
- groups():返回一个所有包含小组字符串的元组,从1到所含的小组号
import re
line = "Cats are smarter than dogs" #定义一个字符串变量
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
matchObj:
print("matchObj.group() : ", matchObj.groups()) # ('Cats', 'smarter')
print("matchObj.group() : ", matchObj.group()) # matchObj.group() : Cats are smarter than dogs
print("matchObj.group(1) : ", matchObj.group(1)) # matchObj.group(1) : Cats
print("matchObj.group(2) : ", matchObj.group(2)) # matchObj.group(2) : smarter
else:
print("No match!!")(2)re.search方法
扫描整个字符串并返回第一个成功的匹配。使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
re.search(pattern, string, flags=0)import re
print(re.search('www', 'www.runoob.com').span()) # www所在位置为(0,3)
print(re.search('com', 'www.runoob.com').span()) # com所在位置为(11,14)前闭后开
line = "Cats are smarter than dogs"
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group()) # Cats are smarter than dogs
print("searchObj.group(1) : ", searchObj.group(1)) # Cats
print("searchObj.group(2) : ", searchObj.group(2)) # smarter
else:
print("Nothing found!!")(3) re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到匹配(返回其位置)。
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I) #从字符串开始匹配dog,因为起始值不是dog,所以匹配不成功
if matchObj:
print("match --> matchObj.group() : ", matchObj.group())
else:
print("No mtch!!") # 执行此条语句
matchObj = re.search( r'dogs', line, re.M|re.I) #遍历整个字符串匹配dogs,可以匹配成功
if matchObj:
print("search --> searchObj.group() : ", matchObj.group()) #执行此语句,输出dogs(具体输出参考matchobj)
else:
print("No match!!")3.2检索和替换
(1)re 模块提供了re.sub用于替换字符串中的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
import re
phone = "2004-959-559 # 这是一个国外电话号码"
# 删除字符串中的 Python注释
num = re.sub(r'#.*$', "", phone)
print("电话号码是: ", num) #电话号码是: 2004-959-559
# 删除非数字(-)的字符串
num = re.sub(r'\D', "", phone)
print("电话号码是 : ", num) #电话号码是 : 2004959559(2)re.compile 函数
用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释

在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
(3)findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表;若有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意!!! match 和 search 是匹配一次, findall 匹配所有。
findall(string[, pos[, endpos]])- string : 待匹配的字符串。
- pos : 可选参数,指定字符串的起始位置,默认为 0。
- endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
import re
pattern = re.compile(r'\d+') # 只查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)多个匹配模式:
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result) # 输出 [('width', '20'), ('height', '10')]3.3正则表达式对象
re.compile() 返回 RegexObject 对象。
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
二、常用方法使用
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配(0,3)
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配none
#------查找字符串中的所有数字--------#
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1) # ['123', '456']
print(result2) #['88', '12']
#------#多个匹配模式,返回元组列表--------#
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result) #[('width', '20'), ('height', '10')]1.正则查找网址
import re
str1 = input()
result = re.match("https://www",str1)
print(result.span()) ##输出返回结果的范围
# print(re.match('https://www', str1).span()) #输出网址从开头匹配到第一位不匹配的范围。2.map()函数:
from collections.abc import Iterator #导入迭代器
map_obj = map(lambda x: x*2, [1,2,3,4,5])
print(isinstance(map_obj,Iterator)) #True
print(list(map_obj)) #[2, 4, 6, 8, 10]
def square(x): #定义一个函数square()
v = x**2
print(v)
print(list(map(square, [1,2,3,4,5]))) 3.filter()函数:
filter_obj = filter(lambda x: x > 5,range(0,10))
print(list(filter_obj))4.isinstance() :可以确定一个对象是否是某个特定类型或定制类的实例。
print(isinstance("hello world",str)) #True
print(isinstance(10,int)) #True
print(isinstance(10.0,float)) #True
print(isinstance(5,float)) #False5.hasattr(obj,attribute):判断目标对象obj是否包含属性attribute
aa = hasattr(json,"dumps")
print(aa) ##True
bb = getattr(json,"__path__") #获取属性__path__的值
print(bb) # ['D:\\Anacoda3\\lib\\json']6.callable():确定一个对象是否是可调用的(如函数,类这些对象都是可以调用的对象。)
print(callable("hello python")) #False
print(callable(list)) #True7.模块
print(json.__doc__) #查询模块json的文档,它输出的内容和 help() 一样
print(json.__name__) #查询模块json的名字
print(json.__file__) #查询模块json的文件路径。若内建的模块没有这个属性,访问它会抛出异常!
print(json.__dict__) #查询模块json的字典类型对象三、泛型函数的使用
泛型: Python 中叫
singledispatch:根据传入参数类型的不同而调用不同的函数。
from functools import singledispatch
@singledispatch
def age(obj):
print('请传入合法类型的参数!')
@age.register(int)
def _(age):
print('我已经{}岁了。'.format(age))
@age.register(str)
def _(age):
print('I am {} years old.'.format(age))
age(23) # int 我已经23岁了。
age('twenty three') # str I am twenty three years old.
age(['23']) # list 请传入合法类型的参数!(1)函数的拼接
from functools import singledispatch
def check_type(func): #通用的拼接函数
def wrapper(*args):
arg1, arg2 = args[:2]
if type(arg1) != type(arg2):
return '【错误】:参数类型不同,无法拼接!!'
return func(*args)
return wrapper
@singledispatch
def add(obj, new_obj):
raise TypeError
@add.register(str)
@check_type
def _(obj, new_obj):
obj += new_obj #字符串拼接
return obj
@add.register(list)
@check_type
def _(obj, new_obj):
obj.extend(new_obj) #列表拼接
return obj
@add.register(dict)
@check_type
def _(obj, new_obj):
obj.update(new_obj) #字典拼接
return obj
@add.register(tuple)
@check_type
def _(obj, new_obj):
return (*obj, *new_obj) #元组拼接
print(add('hello',', world')) #hello, world
print(add([1,2,3], [4,5,6])) #[1, 2, 3, 4, 5, 6]
print(add({'name': 'wangbm'}, {'age':25})) #{'name': 'wangbm', 'age': 25}
print(add(('apple', 'huawei'), ('vivo', 'oppo'))) #('apple', 'huawei', 'vivo', 'oppo')
#list 和 字符串 无法拼接(不同类型无法拼接)
print(add([1,2,3], '4,5,6')) # 输出:【错误】:参数类型不同,无法拼接!!四、上下文管理器
上下文管理器的好处:提高代码的复用率、优雅度、可读性;
(1)读取文件内容
file = open("C:\\Users\HY\\Desktop\\Autotest\\1.txt")
print(file.readline()) #读取首行
print(file.read()) #读取文件全部内容
file.close() #手动关闭文件句柄(2)使用with关键字读取文件,读取结束后可自动关闭文件句柄(with即是上下文管理器)
- 上下文表达式:
with open('test.txt') as file: 上下文管理器:open('test.txt')file是资源对象
with open("C:\\Users\HY\\Desktop\\Autotest\\1.txt") as file:
print(file.read())(3)在类里实现一个上下文管理器:也即是在类里定义:__enter__和__exit__方法,这个类的实例也即是上下文管理器
class Resource():
def __enter__(self):
print("-----connect to resource-----")
return self
def __exit__(self,exc_type,exc_val,exc_tb):
print("-----close resource connection------")
def func(self):
print("----执行函数内部的逻辑")
with Resource() as result:
result.func()
#输出:
# -----connect to resource-----
# ----执行函数内部的逻辑
# -----close resource connection------在 写__exit__ 函数时,需要注意的事,它必须要有这三个参数:
-
exc_type:异常类型
-
exc_val:异常值
-
exc_tb:异常的错误栈信息
当主逻辑代码没有报异常时,这三个参数将都为None。
(4)使用 contextlib构建一个上下文管理器(通过一个函数来实现上下文管理器,而不用一个类)
python中,contextlib 的协议实现了一个打开文件(with open)的上下文管理器。
import contextlib
@contextlib.contextmanager
def open_func(file_name):
# __enter__方法
print("open file:",file_name,"in__enter__")
file_handler = open(file_name,"r") #打开文件
yield file_handler #生成器(带有yield)
# __exit__方法
print("close file:",file_name,"in__exit")
file_handler.close() #关闭句柄
return
with open_func("C:\\Users\HY\\Desktop\\Autotest\\1.txt") as file_in:
for line in file_in:
print(line)上面这段代码只能实现上下文管理器的第一个目的(管理资源),并不能实现第二个目的(处理异常)。如果要处理异常,可以改成:
import contextlib
@contextlib.contextmanager
def open_func(file_name):
# __enter__方法
print("open file:",file_name,"in__enter__")
file_handler = open(file_name,"r") #读取文件
try:
yield file_handler #生成器(带有yield)
except Exception as exc:
print("the exception was thrown")
finally:
print("close file:",file_name,"in__exit") # __exit__方法
file_handler.close() #关闭句柄
return
with open_func("C:\\Users\HY\\Desktop\\Autotest\\1.txt") as file_in:
for line in file_in:
1/0
print(line)五、装饰器
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
常用于有切面需求的场景:如插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
装饰器的使用方法:
先定义一个装饰器decorator(帽子)
再定义你的业务函数或者类(人)wrapper
最后把这装饰器(帽子)扣在这个函数(人)头上
#=================装饰器的使用==========================
# 定义装饰器
def decorator(func):
def wrapper(*args,**kw):
return func()
return wrapper
# 定义业务函数并进行装饰
@decorator
def function():
print("hello world")(1)普通装饰器
#=================普通装饰器的使用==========================
#定义装饰器函数,logger是装饰器,参数func是被装饰的函数
def logger(func):
def wrapper(*args,**kw):
print('开始执行{}函数:'.format(func.__name__)) #
#函数逻辑体:真正需要执行的逻辑
func(*args,**kw)
print('执行完毕')
return wrapper
#写函数,具体功能
@logger
def add(x,y):
print(f"{x}+{y}={x+y}") #两种输出都可
print("{}+{}={}".format(x,y,x+y))
add(20,30)六、异常
异常:导致程序在运行过程中出现异常中断和退出的错误。正常情况下,异常都不会被程序处理,而是以错误信息的形式展现出来。所有异常都是异常类,首字母是大写的!
- SyntaxError:语法错误
- TypeError:类型错误,也就是说将某个操作或功能应用于不合适类型的对象时引发,比如整型与字符型进行加减法
- IndexError:索引出现了错误,比如最常见下标索引超出了序列边界
- KeyError:关键字错误,主要发生在字典中,比如当用户试图访问一个字典中不存在的键时会被引发。
- ValueError:传入一个调用者不期望的值时引发,即使这个值的类型是正确的,比如想获取一个列表中某个不存在值的索引。
- AttributeError:属性错误,试图访问一个对象不存在的属性时引发。(如字典有get方法,列表没有,若列表对象调用get方法就会引发该异常。)
- NameError:变量名称发生错误,如用户试图调用一个未被赋值或初始化的变量时被触发。
- IOError:打开文件错误,当用户试图以读取方式打开一个不存在的文件时引发。
- StopIteration:迭代器错误,当访问至迭代器最后一个值时仍然继续访问,就会引发这种异常,提醒用户迭代器中已经没有值可供访问了
- AssertionError:断言错误,当用户利用断言语句检测异常时,如果断言语句检测的表达式为假,则会引发这种异常。
- IndentationError:缩进异常
- ImportError:导包过程中出现的错误,包名错误或者路径不对、包未安装,抛出 ImportError
6.1抛出和捕获异常
异常处理工作包括:抛出、捕获。
捕获指的是使用try....except包裹特定语句,而raise则是主动抛出异常
(1)抛出异常
异常产生有两种来源:
-
程序自动抛出:如
1/0会自动抛出 ZeroDivisionError -
开发者主动抛出:使用
raise关键字抛出。
def demo_func(filename):
if not os.path.isfile(filename):
raise Exception #raise抛出异常(2)捕获异常
异常的捕获的语法有如下四种:
#====================只捕捉,不获取异常信息===================#
try:
代码A
except [EXCEPTION]:
代码B
#=========捕捉了,还要获取异常信息,赋值给 e 后,把异常信息打印到日志中。================#
try:
代码A
except [EXCEPTION] as e:
代码B
#==================代码A发生了异常,则会走到代码B的逻辑=======================#
try:
代码A
except [exception] as e :
代码B
#============代码A发生了异常,则走到代码B的逻辑,如果没有发生异常,则会走到代码C=============#
try:
代码A
except [exception] as e:
代码B
else:
代码C
#============代码A发生了异常,则走到代码B的逻辑,最后不管有没有异常都会执行代码C=============#
try:
代码A
except [exception] as e:
代码B
finally:
代码C(3)捕获多个异常:except可以捕获一个或者多个异常
1)每个except捕获一个异常
一个 try 语句可能有多个 except 子句,以指定不同异常的处理程序,但是最多会执行一个处理程序。
try:
1/0 #此处抛出异常,因为除数不能为0
except IOError:
print("IO读写出错")
except FloatingPointError:
# 浮点计算错误
print("计算错误")
except ZeroDivisionError: #因此这里捕捉到异常,执行这部分的代码,其余异常代码不执行
# 除数不能为 0
print("计算错误") #最后输出为:计算错误2)一个except捕获多个异常
except 后面可以接多个异常的,多个异常之间使用括号包裹。只要匹配上一个就算捕获到,就会进入相应的代码分支。
try:
1/0
except IOError:
print("IO读写出错")
except (ZeroDivisionError, FloatingPointError): #此处捕获到异常
print("计算出错")(4)自定义异常
自定义异常应该继承 Exception 类,直接继承或者间接继承都可
自定义的异常或错误类,下面使用 InputError (异常的名字都以Error结尾,我们在为自定义异常命名的时候也需要遵守这一规范,就跟标准的异常命名一样),表示接受用户输入时发生问题。
class InputError(Exception):
def __init__(self, msg):
self.message = msg
def __str__(self):
return self.message
def get_input():
name = input("请输入你的姓名:")
if name == '':
raise InputError("未输入内容")
try:
get_input()
except InputError as e:
print(e)(5)如何关闭异常自动关联上下文
如果在异常处理程序或 finally 块中引发异常,默认情况下,异常机制会隐式工作会将先前的异常附加为新异常的 __context__属性。这就是 Python 默认开启的自动关联异常上下文。
若想控制这个上下文,可以加个 from 关键字(from 语法会有个限制,就是第二个表达式必须是另一个异常类或实例。),来表明你的新异常是直接由哪个异常引起的
try:
print(1/0) #抛出异常
except Exception as exc:
raise RuntimeError("Something bad happened") from exc #执行此语句抛出RuntimeError同时抛出1/0产生的ZeroDivisionError异常也可以通过with_traceback()方法为异常设置上下文__context__属性,这也能在traceback更好的显示异常信息。
try:
print(1 / 0)
except Exception as exc:
raise RuntimeError("bad thing").with_traceback(exc)总结:
只捕获可能会抛出异常的语句,避免含糊的捕获逻辑
保持模块异常类的抽象一致性,必要时对底层异常类进行包装
使用“上下文管理器”可以简化重复的异常处理逻辑