【大数据基础】基于YELP数据集的商业数据分析
https://dblab.xmu.edu.cn/blog/2631/
数据预处理
from pyspark import SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
def data_process(raw_data_path):
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
business = spark.read.json(raw_data_path)
split_col = f.split(business['categories'], ',')
business = business.withColumn("categories", split_col).filter(business["city"] != "").dropna()
business.createOrReplaceTempView("business")
b_etl = spark.sql("SELECT business_id, name, city, state, latitude, longitude, stars, review_count, is_open, categories, attributes FROM business").cache()
b_etl.createOrReplaceTempView("b_etl")
outlier = spark.sql(
"SELECT b1.business_id, SQRT(POWER(b1.latitude - b2.avg_lat, 2) + POWER(b1.longitude - b2.avg_long, 2)) \
as dist FROM b_etl b1 INNER JOIN (SELECT state, AVG(latitude) as avg_lat, AVG(longitude) as avg_long \
FROM b_etl GROUP BY state) b2 ON b1.state = b2.state ORDER BY dist DESC")
outlier.createOrReplaceTempView("outlier")
joined = spark.sql("SELECT b.* FROM b_etl b INNER JOIN outlier o ON b.business_id = o.business_id WHERE o.dist<10")
joined.write.parquet("file:///home/hadoop/wangyingmin/yelp-etl/business_etl", mode="overwrite")
if __name__ == "__main__":
raw_hdfs_path = 'file:///home/hadoop/wangyingmin/yelp_academic_dataset_business.json'
print("Start cleaning raw data!")
data_process(raw_hdfs_path)
print("Successfully done")
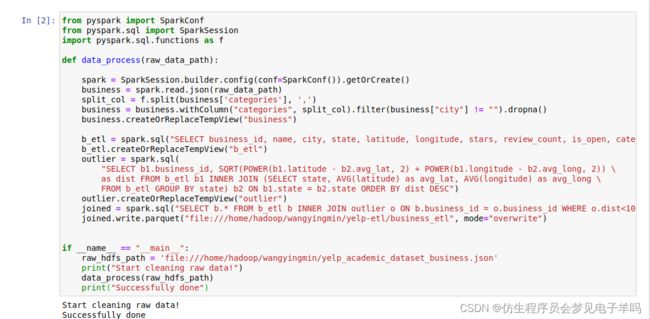
在上述代码中,使用“距离洲内商家平均位置的欧式距离”来除去离群值。
数据分析
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
import os
def attribute_score(attribute):
att = spark.sql("SELECT attributes.{attr} as {attr}, category, stars FROM for_att".format(attr=attribute)).dropna()
att.createOrReplaceTempView("att")
att_group = spark.sql("SELECT {attr}, AVG(stars) AS stars FROM att GROUP BY {attr} ORDER BY stars".format(attr=attribute))
att_group.show()
att_group.write.json("file:///usr/local/spark/yelp/analysis/{attr}".format(attr=attribute), mode='overwrite')
def analysis(data_path):
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
business = spark.read.parquet(data_path).cache()
business.createOrReplaceTempView("business")
part_business = spark.sql("SELECT state, city, stars, review_count, explode(categories) AS category FROM business").cache()
part_business.show()
part_business.createOrReplaceTempView('part_business_1')
part_business = spark.sql("SELECT state, city, stars, review_count, REPLACE(category, ' ','')as new_category FROM part_business_1")
part_business.createOrReplaceTempView('part_business')
print("## All distinct categories")
all_categories = spark.sql("SELECT business_id, explode(categories) AS category FROM business")
all_categories.createOrReplaceTempView('all_categories')
distinct = spark.sql("SELECT COUNT(DISTINCT(new_category)) FROM part_business")
distinct.show()
print("## Top 10 business categories")
top_cat = spark.sql("SELECT new_category, COUNT(*) as freq FROM part_business GROUP BY new_category ORDER BY freq DESC")
top_cat.show(10)
top_cat.write.json("file:///usr/local/spark/yelp/analysis/top_category", mode='overwrite')
print("## Top business categories - in every city")
top_cat_city = spark.sql("SELECT city, new_category, COUNT(*) as freq FROM part_business GROUP BY city, new_category ORDER BY freq DESC")
top_cat_city.show()
top_cat.write.json("file:///usr/local/spark/yelp/analysis/top_category_city", mode='overwrite')
print("## Cities with most businesses")
bus_city = spark.sql("SELECT city, COUNT(business_id) as no_of_bus FROM business GROUP BY city ORDER BY no_of_bus DESC")
bus_city.show(10)
bus_city.write.json("file:///usr/local/spark/yelp/analysis/top_business_city", mode='overwrite')
print("## Average review count by category")
avg_city = spark.sql(
"SELECT new_category, AVG(review_count)as avg_review_count FROM part_business GROUP BY new_category ORDER BY avg_review_count DESC")
avg_city.show()
avg_city.write.json("file:///usr/local/spark/yelp/analysis/average_review_category", mode='overwrite')
print("## Average stars by category")
avg_state = spark.sql(
"SELECT new_category, AVG(stars) as avg_stars FROM part_business GROUP BY new_category ORDER BY avg_stars DESC")
avg_state.show()
avg_state.write.json("file:///usr/local/spark/yelp/analysis/average_stars_category", mode='overwrite')
print("## Data based on Attribute")
for_att = spark.sql("SELECT attributes, stars, explode(categories) AS category FROM business")
for_att.createOrReplaceTempView("for_att")
attribute = 'RestaurantsTakeout'
attribute_score(attribute)
if __name__ == "__main__":
business_data_path = 'file:///home/hadoop/wangyingmin/yelp-etl/business_etl'
print("Start analysis data!")
analysis(business_data_path)
print("Analysis done")


Start analysis data!
+-----+----------+-----+------------+--------------------+
|state| city|stars|review_count| category|
+-----+----------+-----+------------+--------------------+
| AZ|Cave Creek| 3.0| 51| Burgers|
| AZ|Cave Creek| 3.0| 51| Restaurants|
| AZ|Cave Creek| 3.0| 51| American (Tradit...|
| AZ|Cave Creek| 3.0| 51| Mexican|
| AZ|Cave Creek| 3.0| 51| Pizza|
| NC| Gastonia| 4.5| 23| Restaurants|
| NC| Gastonia| 4.5| 23| Chinese|
| OH| Twinsburg| 3.0| 4| Auto Repair|
| OH| Twinsburg| 3.0| 4| Automotive|
| OH| Twinsburg| 3.0| 4| Body Shops|
| OH| Twinsburg| 3.0| 4| Auto Glass Services|
| NV| Las Vegas| 2.0| 23| Mexican|
| NV| Las Vegas| 2.0| 23| Restaurants|
| NC| Charlotte| 4.0| 535| Southern|
| NC| Charlotte| 4.0| 535| American (Tradit...|
| NC| Charlotte| 4.0| 535| Restaurants|
| NC| Charlotte| 4.0| 535| American (New)|
| ON| Toronto| 2.5| 5| Bridal|
| ON| Toronto| 2.5| 5| Shopping|
| AZ| Mesa| 3.0| 44| Massage Therapy|
+-----+----------+-----+------------+--------------------+
only showing top 20 rows
## All distinct categories
+----------------------------+
|count(DISTINCT new_category)|
+----------------------------+
| 1318|
+----------------------------+
## Top 10 business categories
+--------------+-----+
| new_category| freq|
+--------------+-----+
| Restaurants|49936|
| Shopping|27014|
| Food|25985|
| HomeServices|16880|
| Beauty&Spas|16607|
|Health&Medical|14843|
| LocalServices|12003|
| Nightlife|11614|
| Bars|10448|
| Automotive| 9166|
+--------------+-----+
only showing top 10 rows
## Top business categories - in every city
+----------+--------------+----+
| city| new_category|freq|
+----------+--------------+----+
| Toronto| Restaurants|6573|
| Las Vegas| Restaurants|5573|
| Las Vegas| Shopping|4334|
| Toronto| Food|3453|
| Phoenix| Restaurants|3314|
| Las Vegas| HomeServices|3298|
| Las Vegas| Food|3134|
| Montréal| Restaurants|3130|
| Las Vegas| Beauty&Spas|2826|
| Phoenix| Shopping|2733|
| Phoenix| HomeServices|2682|
| Las Vegas|Health&Medical|2669|
| Toronto| Shopping|2463|
| Charlotte| Restaurants|2425|
| Calgary| Restaurants|2366|
| Las Vegas| LocalServices|2300|
|Pittsburgh| Restaurants|2133|
| Phoenix| Food|1877|
| Phoenix|Health&Medical|1829|
| Las Vegas| Nightlife|1747|
+----------+--------------+----+
only showing top 20 rows
## Cities with most businesses
+----------+---------+
| city|no_of_bus|
+----------+---------+
| Las Vegas| 22554|
| Phoenix| 14186|
| Toronto| 13602|
| Charlotte| 7487|
|Scottsdale| 6955|
|Pittsburgh| 5383|
| Calgary| 5260|
| Montréal| 4935|
| Mesa| 4850|
| Henderson| 3833|
+----------+---------+
only showing top 10 rows
## Average review count by category
+-----------------+------------------+
| new_category| avg_review_count|
+-----------------+------------------+
| StreetArt| 1253.0|
| MarketStalls| 1084.0|
| BeerGarden| 1063.5|
| Resorts| 489.8606060606061|
| Udon| 462.0|
| Tuscan| 446.6|
| Casinos|440.74581005586595|
|ConveyorBeltSushi| 410.5|
| Pancakes| 333.1111111111111|
| TikiBars| 329.3333333333333|
|NewMexicanCuisine| 325.2375|
| Airlines|290.44827586206895|
| JapaneseCurry|289.61538461538464|
| Izakaya| 285.44|
| Observatories| 275.6666666666667|
| Teppanyaki| 264.2432432432432|
| Guamanian| 243.0|
| Flyboarding| 240.0|
| Brazilian|230.25882352941176|
| BotanicalGardens|218.91176470588235|
+-----------------+------------------+
only showing top 20 rows
## Average stars by category
+--------------------+-----------------+
| new_category| avg_stars|
+--------------------+-----------------+
| EntertainmentLaw| 5.0|
| JapaneseSweets| 5.0|
| Stonemasons| 5.0|
| OutdoorMovies| 5.0|
| SignatureCuisine| 5.0|
| CourtReporters| 5.0|
|WildlifeHuntingRa...| 5.0|
| GameTruckRental|4.928571428571429|
| PublicArt|4.916666666666667|
| BrazilianJiu-jitsu|4.882352941176471|
|BeachEquipmentRen...|4.833333333333333|
| Caricatures|4.833333333333333|
| ScavengerHunts|4.833333333333333|
| Pickleball|4.833333333333333|
| BartendingSchools|4.833333333333333|
| PartyBikeRentals| 4.8125|
| HouseSitters| 4.8125|
| ArtTours| 4.8|
| VocalCoach| 4.8|
| Biketours|4.794117647058823|
+--------------------+-----------------+
only showing top 20 rows
## Data based on Attribute
+------------------+-----------------+
|RestaurantsTakeout| stars|
+------------------+-----------------+
| True|3.543621136355401|
| False|3.614546070715819|
| None|3.640769230769231|
+------------------+-----------------+
Analysis done
数据可视化
import json
import os
import pandas as pd
import matplotlib.pyplot as plt
AVE_REVIEW_CATEGORY = '/usr/local/spark/yelp/analysis/average_review_category'
OPEN_CLOSE = '/usr/local/spark/yelp/analysis/open_close'
TOP_CATEGORY_CITY = '/usr/local/spark/yelp/analysis/top_category_city'
TOP_BUSINESS_CITY = '/usr/local/spark/yelp/analysis/top_business_city'
TOP_CATEGORY = '/usr/local/spark/yelp/analysis/top_category'
AVE_STARS_CATEGORY = '/usr/local/spark/yelp/analysis/average_stars_category'
TAKEOUT = '/usr/local/spark/yelp/analysis/RestaurantsTakeout'
def read_json(file_path):
json_path_names = os.listdir(file_path)
data = []
for idx in range(len(json_path_names)):
json_path = file_path + '/' + json_path_names[idx]
if json_path.endswith('.json'):
with open(json_path) as f:
for line in f:
data.append(json.loads(line))
return data
if __name__ == '__main__':
ave_review_category_list = read_json(AVE_REVIEW_CATEGORY)
open_close_list = read_json(OPEN_CLOSE)
top_category_city_list = read_json(TOP_CATEGORY_CITY)
top_business_city_list = read_json(TOP_BUSINESS_CITY)
top_category_list = read_json(TOP_CATEGORY)
ave_stars_category_list = read_json(AVE_STARS_CATEGORY)
takeout_list = read_json(TAKEOUT)
top_category_list.sort(key=lambda x: x['freq'], reverse=True)
top_category_key = []
top_category_value = []
for idx in range(10):
one = top_category_list[idx]
top_category_key.append(one['new_category'])
top_category_value.append(one['freq'])
plt.barh(top_category_key[:10], top_category_value[:10], tick_label=top_category_key[:10])
plt.title('Top 10 Categories', size = 16)
plt.xlabel('Frequency',size =8, color = 'Black')
plt.ylabel('Category',size = 8, color = 'Black')
plt.tight_layout()
top_business_city_list.sort(key=lambda x: x['no_of_bus'], reverse=True)
top_business_city_key = []
top_business_city_value = []
for idx in range(10):
one = top_business_city_list[idx]
top_business_city_key.append(one['no_of_bus'])
top_business_city_value.append(one['city'])
"""
plt.barh(top_business_city_value[:10], top_business_city_key[:10], tick_label=top_business_city_value[:10])
plt.title('Top 10 Cities with most businesses', size = 16)
plt.xlabel('no_of_number',size =8, color = 'Black')
plt.ylabel('city',size = 8, color = 'Black')
plt.tight_layout()
"""
ave_review_category_list.sort(key=lambda x: x['avg_review_count'], reverse=True)
ave_review_category_key = []
ave_review_category_value = []
for idx in range(10):
one = ave_review_category_list[idx]
ave_review_category_key.append(one['avg_review_count'])
ave_review_category_value.append(one['new_category'])
"""
plt.barh(ave_review_category_value[:10], ave_review_category_key[:10], tick_label=ave_review_category_value[:10])
plt.title('Top 10 categories with most review', size=16)
plt.xlabel('avg_review_count', size=8, color='Black')
plt.ylabel('category', size=8, color='Black')
plt.tight_layout()
"""
ave_stars_category_list.sort(key=lambda x: x['avg_stars'], reverse=True)
ave_stars_category_key = []
ave_stars_category_value = []
for idx in range(10):
one = ave_stars_category_list[idx]
ave_stars_category_key.append(one['avg_stars'])
ave_stars_category_value.append(one['new_category'])
"""
plt.barh(ave_stars_category_value[:10], ave_stars_category_key[:10], tick_label=ave_stars_category_value[:10])
plt.title('Top 10 categories with most stars', size=16)
plt.xlabel('avg_stars', size=8, color='Black')
plt.ylabel('category', size=8, color='Black')
plt.tight_layout()
"""
takeout_list.sort(key=lambda x: x['stars'], reverse=True)
takeout_key = []
takeout_value = []
for idx in range(len(takeout_list)):
one = takeout_list[idx]
takeout_key.append(one['stars'])
takeout_value.append(one['RestaurantsTakeout'])
"""
explode = (0,0,0)
plt.pie(takeout_key,explode=explode,labels=takeout_value, autopct='%1.1f%%',shadow=False, startangle=150)
plt.title('Whether take out or not', size=16)
plt.axis('equal')
plt.tight_layout()
"""
plt.show()
下面是可视化的效果:




