Pandas:利用Styler对象设置Series、Dataframe在Jupyter Notebook中的输出样式(3)——格式化显示值、内置显示值格式化方法、表格外观、样式复用
当前pandas版本为:1.2.5。
pandas数据结构在Jupyter Notebook中以表格形式呈现。这些表格的格式化依赖于pandas中的Styler对象。Dateframe.style属性返回值为Styler对象。
Styler对象的方法的返回值大部分还是Styler对象,Styler对象支持链式调用,这样就可以将多种样式叠加在一起。
1. 显示值格式化
pandas在notebook中的值分为显示值和实际值。Styler.format()方法可以格式化显示值。
Styler.format()方法的签名如下:Styler.format(formatter, subset=None, na_rep=None)
Styler.format()方法具有以下参数:
formatter:格式。类型为字符串、可调用对象、字典或None。默认值为None。- 字符串:格式化字符串。
- 字典:键为列索引,值为对应列的格式化字符串。
- 可调用对象:参数为单独的一个值即元素,返回值为字符串。
- 可调用对象字典:键为列索引,值为可调用对象。
subset:用于指定生效范围,即DataFrame的索引。na_rep:缺失值的显示值。类型为字符串。默认为None,即不作任何更改。
Styler.format()方法的返回值为Styler对象。
案例:Styler.format()方法formatter参数演示
本案例案例中,formatter参数分别采用字符串、字典、可调用对象字典对DataFrame进行格式化。
首先对设置所有单元格均保留小数点后2位数字,然后再设置b列显示为百分比保留2位小数,最后将c列字符串设置为大写。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4, 2), columns=['a', 'b'])
df['c'] = ['a', 'b', 'c', 'd']
df.style.format("{:.2f}").format({'b':"{:.2%}"}).format({'c': str.upper})
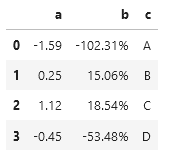
运行df可知,df的通过Styler对象格式化的显示值不影响实际值。

2. 内置显示值格式化方法
为了便于格式化显示值,Styler类内置了一些针对所有单元格的全局性的内置方法。
设置浮点数精度
Styler.set_precision()方法用于全局设置浮点数的显示精度。
Styler.set_precision()方法的签名如下:Styler.set_precision(precision)
Styler.set_precision()方法具有一个参数: precision:指定浮点数的显示精度。类型为整数。
Styler.set_precision()方法的返回值为Styler对象。
设置缺失值显示值
Styler.set_na_rep()方法可用于全局设置缺失值的显示值。
Styler.set_na_rep()方法的签名如下:Styler.set_na_rep(na_rep)
Styler.set_na_rep()方法只有一个参数: na_rep:指定缺失值显示值。类型为字符串。
Styler.set_na_rep()方法的返回值为Styler对象。
案例:演示Styler.set_precision()方法和Styler.set_na_rep()方法
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4, 2), columns=['a', 'b'])
df.iloc[1, 1] = np.nan
df.style.set_precision(3).set_na_rep('FAIL')

3. 表格外观
Styler类还定义了一些与数据无关的控制表格外观的方法
设置表格标题
Styler.set_caption()方法可用于设置表格的标题。
Styler.set_caption()方法的签名如下:Styler.set_caption(caption)
Styler.set_caption()方法只有一个参数: caption:指定表格的标题。类型为字符串。
Styler.set_caption()方法的返回值为Styler对象。
隐藏行索引
Styler.hide_index()方法可用于隐藏行索引。
Styler.hide_index()方法的签名如下:Styler.hide_index()
Styler.hide_index()方法的返回值为Styler对象。
隐藏列
Styler.hide_columns()方法可用于隐藏列。
Styler.hide_columns()方法的签名如下:Styler.hide_columns(subset)
Styler.hide_columns()方法只有一个参数 subset:用于指定生效范围,即DataFrame的索引。
Styler.hide_columns()方法的返回值为Styler对象。
案例:演示设置标题、隐藏行索引、隐藏列
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4, 3), columns=['a', 'b', 'c'])
df.style.set_caption("标题").hide_index().hide_columns("a")

4. 样式复用
通过Styler对象构建的样式可以复用。Styler.export()方法用于输出样式,Styler.use()方法用于应用样式,两者往往配合使用。
输出样式
Styler.export()方法可用于输出样式,往往与Styler.use()方法配合使用。
Styler.export()方法的签名如下:Styler.export()
Styler.export()方法的返回值为样式函数列表。
输出样式
Styler.use()方法可用于应用样式,往往与Styler.export()方法配合使用。
Styler.use()方法的签名如下:Styler.use(styles)
Styler.use()方法具有一个参数 styles:指定样式。类型为样式函数列表,通常为Styler.use(styles)方法的返回值。
Styler.use()方法的返回值为Styler对象。
案例:复用样式
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4, 2), columns=['a', 'b'])
style1 = df.style.highlight_max()
style1
df2=-df
df2.style.use(style1.export())

参考文献
https://pandas.pydata.org/docs/user_guide/style.html