数仓选型必列入考虑的OLAP列式数据库ClickHouse(中)
优质资源分享
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| Python实战微信订餐小程序 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| Python量化交易实战 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
实战
案例使用
背景
ELK作为老一代日志分析技术栈非常成熟,可以说是最为流行的大数据日志和搜索解决方案;主要设计组件及架构如下:
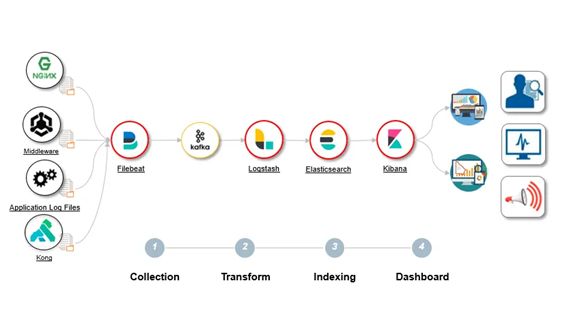
而新一代日志监控选型如ClickHouse、StarRocks特别是近年来对ELK地位发起较大的挑战,不乏有许多的大公司如携程,快手已开始把自己的日志解决方案从 ES 迁移到了 Clickhouse,将日志从ES迁移到ClickHouse可以节省更多的服务器资源,总体运维成本更低,优化日志查询性能提升了查询速度,特别是当用户在紧急排障的时候,这种查询速度的成倍提升,对用户的使用体验有明显的改善,让ClickHouse在日志分析领域为用户提供更大的价值。Clickhouse在大部分的查询的性能上都明显要优于Elastic ,在聚合场景下,Clickhouse表现异常优秀,充分发挥了列存引擎的优势;但是个人认为ClickHouse毕竟不是ES,在某些业务场景中ES仍然不可替代,ES全文检索的倒排索引是建立在内存全文检索查询较快但也比较耗内存;同样对于ClickHouse来说也不仅处理日志,ClickHouse还有更多的使用场景,这个在上一篇文章已经详细介绍过了。本篇我们先从一个简单日志采集的场景拉开ClickHouse在日志分析场景下的使用,以便于后续更深入学习ClickHouse的其他使用场景和技术。前面文章我们也清楚知道ClickHouse基于分片和副本实现了水平扩展和高可用。
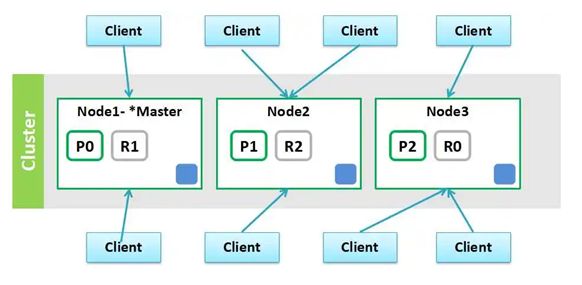
- ES集群架构自己实现
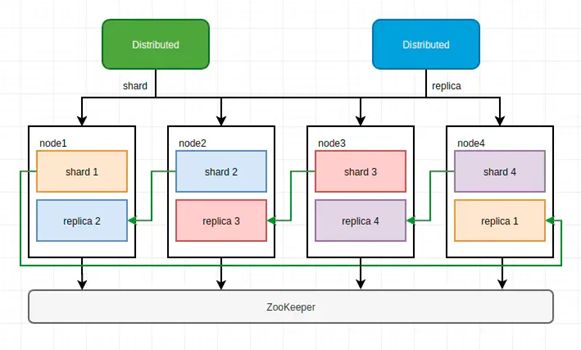
- ClickHouse集群架构依赖Zookeeper实现
- Elasticsearch VS Clickhouse
- Clickhouse 在大部分的查询的性能上都明显要优于 Elastic。
- 在正则查询(Regex query)和单词查询(Term query)等搜索常见的场景下,也并不逊色。
- 在聚合场景下,Clickhouse 表现异常优秀,充分发挥了列式引擎的优势。且在Clickhouse在没有任何优化和没有打开布隆过滤器。可见 Clickhouse 确实是一款非常优秀的数据库,可以用于某些搜索的场景。
- Clickhouse 在基本场景表现非常优秀,性能优于 ES。
- Elasticsearch仅支持Json格式的数据,Elasticsearch有独自生态和语言,学习成本相对较高。
- Elasticsearch最擅长的主要是完全搜索场景(where过滤后的记录数较少),在内存充足运行环境下可以展现出非常出色的并发查询能力。但是在大规模数据的分析场景下(where过滤后的记录数较多),ClickHouse凭借极致的列存和向量化计算会有更加出色的并发表现,并且查询支持完备度也更好。ClickHouse的并发处理能力立足于磁盘吞吐,而Elasticsearch的并发处理能力立足于内存Cache,这使得两者的成本区间有很大差异,ClickHouse更加适合低成本、大数据量的分析场景,它能够充分利用磁盘的带宽能力。数据导入和存储成本上,ClickHouse更加具有绝对的优势。
需求简述
满足业务系统的业务监控需求,达到业务实时监控、实施告警、监控可视化、高效运维的目的,涵盖对外部系统的各种业务数据的ftp文件上报的实现简单业务监控机制,本篇先解决日志的入库,后续有时间再讨论基于Clickhouse日志分析。
总体流程
为了可用于生产设计,我们使用带有副本机制MergeTree家族的ReplicatedMergeTree表引擎(如果单表数据量很大再考虑使用分布表,利用shard),其中shard和replica在前面文章部署ClickHouse作为macros定义配置在每一个clickhouse-server的配置文件里。我们先尝试一个从FileBeat采集日志->Logstash(解析日志)->Kafka->clickhouse_sinker(housepower)->ClickHouse(当然也可以采用FileBeat采集日志->Kafka->Logstash(解析日志)>logstash-clickhouse->ClickHouse,这样更合理,可以用其他技术栈实现对于Kafka流式数据的日志实时监控需求)。
- 日志采集采用Beats平台的Beat工具,本篇主要先基于日志的Filebeat采集组件,很轻量,性能也高,不影响核心服务,将日志文件打上标签全量上报给Logstash;Beat工具部署在程序模块和需要采集日志的服务器上。也可以在Java程序直接引入logstash-logback-encoder依赖(net.logstash.logback),通过与logback整合实现程序上报日志。

- Logstash较重对服务器性能有消耗,Logstash对全量日志进行过滤和转换等处理,将处理后数据写到公共集群Kafka对应的Topic里。Logstash在每个业务集群可以一个或多个,根据实际情况调整。
- 通过第三方housepower的clickhouse_sinker插件从公共集群Kafka不断读取配置Topic的数据写入ClickHouse对应库中的日志表。
ClickHouse建表
由于业务日志的数据量规模不大,这里创建数据库和创建带有副本的ftp_log、import_log日志表,后续有其他日志可以再创建对应的表。当然如果想采集所有运行日志,可以直接通过标准logback如(时间、线程、日志级别、方法、内容信息),并加上服务名称、IP等输出存储日志记录的数据,通过对内容信息like模糊查询实现ELK中日志全文检索的系统维护工作。
CREATE DATABASE log_monitor ENGINE = Atomic;
use log_monitor;
# FTP上报日志表,通过分析ftp服务器vsftpd的日志监控上报文件的基本信息
CREATE TABLE ftp_log
(
host_name String COMMENT '主机名',
host_ip String COMMENT '主机IP',
service_name String COMMENT '服务名称',
file_type String COMMENT '文件类型',
file_name String COMMENT '文件名称',
file_size INT COMMENT '文件大小',
upload_time DateTime COMMENT '上传时间',
source_ip String COMMENT '上传客户端IP'
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/log\_monitor/ftp\_log', '{replica}')
PARTITION BY toYYYYMM(upload_time)
ORDER BY (file_type, upload_time);
# 导入大数据平台的日志表
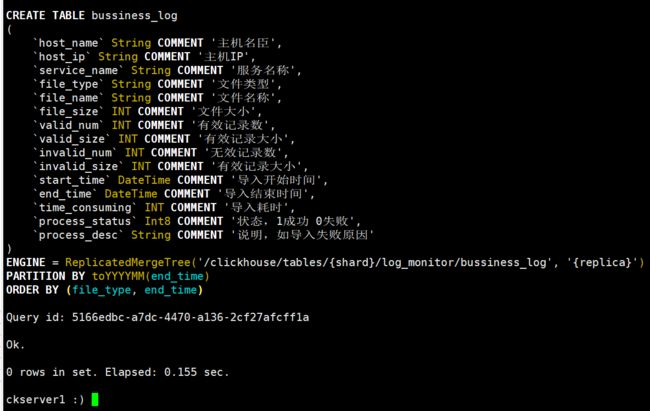
CREATE TABLE bussiness_log
(
host_name String COMMENT '主机名',
host_ip String COMMENT '主机IP',
service_name String COMMENT '服务名称',
file_type String COMMENT '文件类型',
file_name String COMMENT '文件名称',
file_size INT COMMENT '文件大小',
valid_num INT COMMENT '有效记录数',
valid_size INT COMMENT '有效记录大小',
invalid_num INT COMMENT '无效记录数',
invalid_size INT COMMENT '有效记录大小',
start_time DateTime COMMENT '导入开始时间',
end_time DateTime COMMENT '导入结束时间',
time_consuming INT COMMENT '导入耗时,单位毫秒',
process_status Int8 COMMENT '状态,1成功 0失败',
process_desc String COMMENT '说明,如导入失败原因'
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/log\_monitor/bussiness\_log', '{replica}')
PARTITION BY toYYYYMM(end_time)
ORDER BY (file_type, end_time);
clickhouse-client -m
use log_monitor;
通过clickhouse-client创建好两张表
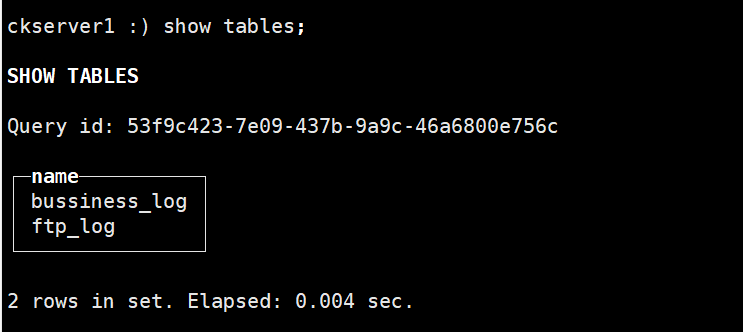
FileBeat采集日志文件配置
Filebeat 提供了一套预构建的模块,让您可以快速实施和部署日志监视解决方案,并附带示例仪表板和数据可视化。这些模块支持常见的日志格式,例如Nginx,Apache2和MySQL 等,这些后续我们在ELK章节再详细展开,本篇主要是ClickHouse为主。
# 下载filebeat,这里使用最新8.2.0版本
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.2.0-linux-x86_64.tar.gz
# 解压
tar -xvf filebeat-8.2.0-linux-x86_64.tar.gz
# 进入根目录
cd filebeat-8.2.0-linux-x86_64
# 在根目录下配置filebeat.yml
vim filebeat.yml
filebeat.inputs:
- type: filestream
id: ftplog
paths:
# Filebeat处理文件的绝对路径,默认部署vsftpd是在/var/log/vsftpd.log
- /home/monitor/ftplog/vsftpd*.log
# 使用 fields 模块添加字段
fields:
app_id: ftplog
# host_ip 为字段名称,后面的值为 SERVER_IP 变量值,该变量为系统变量,可以先通过shell脚本比写入环境变量MONITOR_SERVER_IP中
host_ip: ${MONITOR_SERVER_IP}
service_name: vsftpd
# 将新增的字段放在顶级,收集后字段名称显示 host\_ip。如果设置为 false,则放在子集,收集后显示为 fields.host\_ip
fields_under_root: true
- type: filestream
id: bussinesslog
paths:
# Filebeat处理文件的绝对路径
- /home/monitor/bussinesslog/*.log
# 使用 fields 模块添加字段
fields:
app_id: bussinesslog
# 将新增的字段放在顶级
fields_under_root: true
output.logstash:
hosts: ["192.168.12.27:5044"]
# 获取本机IP,可以根据实际编写获取本机IP脚本
export MONITOR_SERVER_IP=$(/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:")
# 这里是演示直接在会话窗口前台启动运行filebeat,nohup ./filebeat -e -c filebeat.yml > logs/filebeat.log 2>&1 &
filebeat -e -c filebeat.yml
创建Kafka Topic
# topic:ftp\_log,进入kafka的根目录
bin/kafka-topics.sh --create --zookeeper huawei27:2181,huawei29:2181,huawei29:2181 --replication-factor 3 --partitions 6 --topic ftp_log
# topic:bussiness\_log
bin/kafka-topics.sh --create --zookeeper huawei27:2181,huawei29:2181,huawei29:2181 --replication-factor 3 --partitions 6 --topic bussiness_log
Logstash配置
# 下载Logstash,这里使用最新8.2.0版本,最新版本JDK要求11或17,下面二进制文件已包含JDK因此文件较大有336M
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.2.0-linux-x86_64.tar.gz
# 解压
tar -xvf logstash-8.2.0-linux-x86_64.tar.gz
# 进入根目录,
cd logstash-8.2.0
# 在conf目录下配置logstash.conf
针对grok语法表达式我们可以在Kibana可视化页面里面调试,也可以找一些grok语法在线调试网站或者工具
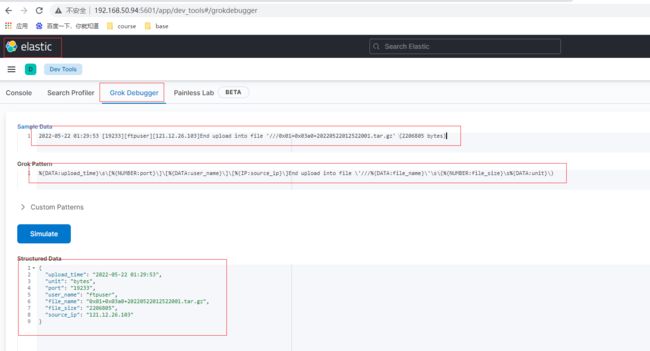
ftplog日志格式示例2022-05-22 01:29:53 [19233][ftpuser][121.12.26.103]End upload into file ‘///0x01+0x03a0+20220522012522001.tar.gz’ (2206805 bytes)
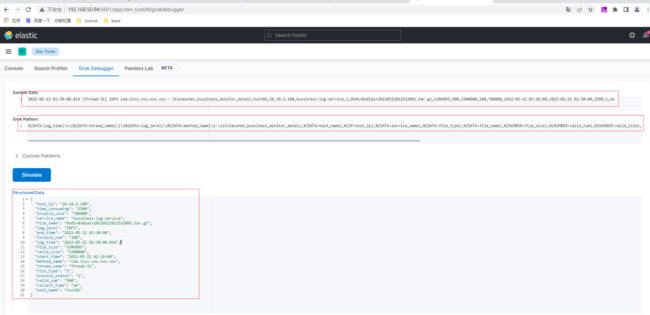
bussinesslog为程序输出的日志格式可以定义如下
2022-05-22 01:30:00.016 [Thread-31] INFO com.itxs.xxx.xxx.xxx - itxiaoshen_bussiness_monitor_detail,host01,10.10.2.100,bussiness-log-service,1,0x01+0x01a1+20220522012522001.tar.gz,2206805,900,1500000,100,700000,2022-05-22 01:28:00,2022-05-22 01:30:00,2500,1,ok
vim conf/logstash.conf
input {
beats {
port => "5044"
client_inactivity_timeout => 3000
add_field => {"[logstash_host_ip]" => "${LOGSTASH_SERVER_IP}"}
}
}
filter {
if [app_id] == "ftplog" {
grok {
match => {
"message" => ["%{DATA:upload_time}\s\[%{NUMBER:port}\]\[%{DATA:user_name}\]\[%{IP:source_ip}\]End upload into file \'///%{DATA:file_name}\'\s\(%{NUMBER:file_size}\s%{DATA:unit}\)"]
}
}
date {
match => [ "upload_time" , "dd/MMM/YYYY:HH:mm:ss" ]
}
mutate {
convert => ["file_size", "integer"]
add_field => { "host_name" => "%{[host][name]}" }
copy => { "file_name" => "file_name_arr" }
}
mutate {
split=>["file_name_arr","+"]
add_field => {"file_type_arr" => "%{[file_name_arr][1]}"}
}
grok {
match => {
"file_type_arr" => "(?(?<=0x)(.{4}))"
}
}
mutate {
convert => ["source\_flag", "integer"]
add\_field => { "file\_type" => "f%{[file\_type\_tmp]}" }
}
}
if [app\_id] == "bussinesslog" {
grok {
match => {
"message" => ["%{DATA:log\_time}\s\[%{DATA:thread\_name}\]\s%{DATA:log\_level}\s%{DATA:method\_name}\s-\sitxiaoshen\_bussiness\_monitor\_detail,%{DATA:host\_name},%{IP:host\_ip},%{DATA:service\_name},%{DATA:file\_type},%{DATA:file\_name},%{NUMBER:file\_size},%{NUMBER:valid\_num},%{NUMBER:valid\_size},%{NUMBER:invalid\_num},%{NUMBER:invalid\_size},%{DATA:start\_time},%{DATA:end\_time},%{NUMBER:time\_consuming},%{NUMBER:process\_status},*(?.*)"]
}
}
mutate {
convert => ["file\_size", "integer"]
convert => ["valid\_num", "integer"]
convert => ["valid\_size", "integer"]
convert => ["invalid\_num", "integer"]
convert => ["invalid\_size", "integer"]
convert => ["time\_consuming", "integer"]
convert => ["process\_status", "integer"]
}
}
if "\_grokparsefailure" in [tags] {
drop {}
}
}
output {
if [app\_id] == "ftplog" {
kafka {
codec => json
topic\_id => "ftp\_log"
bootstrap\_servers => "huawei27:9092,huawei28:9092,huawei29:9092"
}
}
if [app\_id] == "bussinesslog" {
kafka {
codec => json
topic\_id => "bussiness\_log"
bootstrap\_servers => "huawei27:9092,huawei28:9092,huawei29:9092"
}
}
stdout {
codec => json\_lines
}
}
# 获取本机IP,可以根据实际编写获取本机IP脚本
export LOGSTASH_SERVER_IP=$(/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:")
# 检查配置文件语法是否正确
bin/logstash -f config/logstash.conf --config.test_and_exit
# 这里是演示直接在会话窗口前台启动运行logstash,如果通过了文件检查, 我们就可以执行下面这条命令指定配置文件来运行Logstash,--config.reload.automatic可以在Logstash不重启的情况下自动加载配置文件,正式使用通过nohup &放在后台运行即可
bin/logstash -f config/logstash.conf --config.reload.automatic
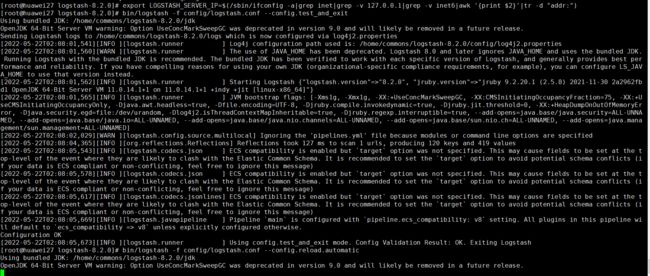
clickhouse_sinker
# github上下载housepower的clickhouse\_sinker,这里使用最新2.4.0版本
wget https://github.com/housepower/clickhouse_sinker/releases/download/v2.4.0/clickhouse_sinker_2.4.0_Linux_x86_64.tar.gz
# 解压
tar -xvf clickhouse_sinker_2.4.0_Linux_x86_64.tar.gz
Nacos上创建命名空间monitor,id为monitord82caf3f-33ee-4bb2-a9b2-630fee68995d,创建ftp-log和bussiness-log两个Json格式的配置文件,所属组为log-monitor。ftp-log配置内容如下
{
"clickhouse": {
"hosts": [
[
"192.168.5.52",
"192.168.5.53",
"192.168.12.27"
]
],
"port": 9000,
"db": "log\_monitor",
"username": "default",
"password": "",
"retryTimes": 0
},
"kafka": {
"brokers": "huawei27:9092,huawei28:9092,huawei29:9092",
"version": "2.5.0"
},
"task": {
"name": "ftp\_log",
"topic": "ftp\_log",
"consumerGroup": "ftp\_log",
"earliest": true,
"parser": "json",
"autoSchema": true,
"tableName": "ftp\_log",
"excludeColumns": [
"day"
],
"flushInterval": 5,
"bufferSize": 50000
},
"logLevel": "debug"
}
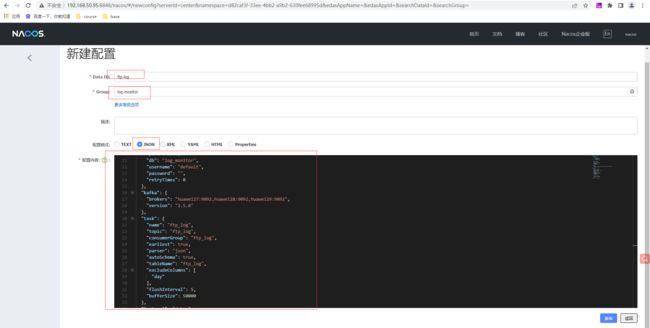
和上面相似ftp-log,bussiness-log配置内容如下:
{
"clickhouse": {
"hosts": [
[
"192.168.5.52",
"192.168.5.53",
"192.168.12.27"
]
],
"port": 9000,
"db": "log\_monitor",
"username": "default",
"password": "",
"retryTimes": 0
},
"kafka": {
"brokers": "huawei27:9092,huawei28:9092,huawei29:9092",
"version": "2.5.0"
},
"task": {
"name": "bussiness\_log",
"topic": "bussiness\_log",
"consumerGroup": "bussiness\_log",
"earliest": true,
"parser": "json",
"autoSchema": true,
"tableName": "bussiness\_log",
"excludeColumns": [
"day"
],
"flushInterval": 5,
"bufferSize": 50000
},
"logLevel": "debug"
}

# 这里采用Nacos配置启动方式,简单的也可以直接指定本地配置文件的方式,clickhouse\_sinker可以部署多个实现负载均衡和高可用,正式使用通过nohup &放在后台运行即可
./clickhouse_sinker --nacos-addr 192.168.50.95:8848 --nacos-username nacos --nacos-password nacos --nacos-namespace-id d82caf3f-33ee-4bb2-a9b2-630fee68995d --nacos-group log-monitor --nacos-dataid ftp-log
# 可以另开一个窗口启动第二个sinker,正式使用通过nohup &放在后台运行即可
./clickhouse_sinker --nacos-addr 192.168.50.95:8848 --nacos-username nacos --nacos-password nacos --nacos-namespace-id d82caf3f-33ee-4bb2-a9b2-630fee68995d --nacos-group log-monitor --nacos-dataid bussiness-log
启动后日志输出
日志测试
这里我们简单模拟写日志文件方式,后续可以通过实际业务流程进行测试。在/home/monitor/ftplog写入日志

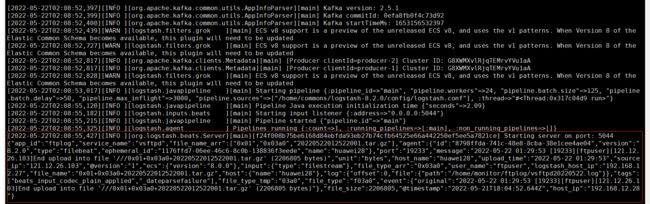
Logstash输出日志如下
查看ClickHouse的ftp_log表数据已成功写入

在/home/monitor/ftplog写入日志

Logstash输出日志如下

查看ClickHouse的ftp_log表数据已成功写入
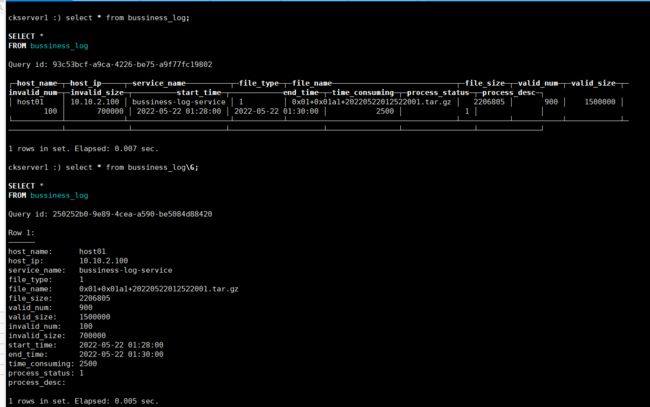
至此,一个完整流程完毕