python+selenium+unittest自动化测试详解
#python+selenium+unittest自动化测试详解
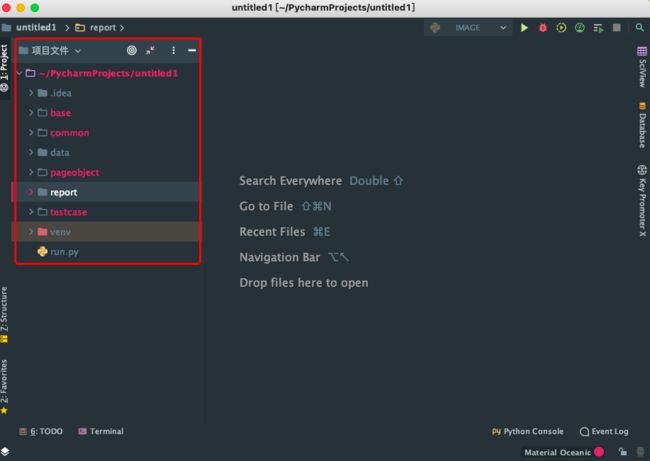
这是搭建好的自动化测试的目录。
Base(基类层)
最基础类,供其他文件调用,封装浏览器方法,以方便后面代码的调用。
可以二次封装自带的方法,方便调用。
其他地方调用基础类的方法。如果需要修改调用地方的方法,只需要修改基础类里面的方法,提高代码的复用性,可维护性。
Common(公共方法层)
存放公共方法,例如:excel处理,图片处理等。
需要用到什么公共类方法,全部写在这个文件夹下,需要用到的时候调用就行,方便管理。
Data(数据层)
这个文件夹存放测试所需要的测试数据,测试图片。
Pageobject(页面层)
这个文件夹存放的是自动化测试用到的页面,测试页面。一个页面一个py文件,页面文件中存储的是页面中的静态元素定位和动态页面方法。
静态元素定位,是定位好需要用到的元素,测试中未用到的元素不需要定位,用到什么元素就定位什么元素。把需要用到的元素一个个封装定位好,方便写页面方法的时候调用。
动态页面方法,是指该页面下的操作,比如:登陆页面,输入用户名。密码,点击登陆按钮。这些操作都是在这个页面内完成的,属于该页面独有的页面动作,就是动态页面方法。跟静态元素定位一样的是,测试中需要用到的动作才进行封装编写。测试中不需要用到的动作流程,不需要封装到这个页面文件中。
动态页面方法,是页面下一个个方法,一个动作封装为一个方法,再利用页面中定位好的静态元素,以及继承自base基类中的方法,编写好每一个动态页面方法的流程,方便调用。
Report(报告层)
存放测试报告的文件夹,在执行文件中配置好了,只要执行一次用例,会自动写入本地用例的执行情况,方便记录,测试报告可以自定义修改样式。
Testcase(测试用例层)
存放测试用例,测试用例层调用页面包中对应页面下的动作方法,完成测试步骤,以及不同的测试用例,编写不同的断言,判断该条测试用例是否正确通过。
Run.py(执行文件)
执行文件,相当于整个测试用例的开关,这个文件中配置的是测试报告,以及HTTPTestRunner自动化测试执行器,可以指定执行哪一个测试用例,或所有测试用例。该文件也可以定制自动化测试报告,生成报告文件的代码也是编写在这个文件中。
这个是最基础的自动化测试框架,还有一些都可以自定义加上的,如log文件,发送emall文件。
框架是可以自己定义的,需要用到什么,自己就加上什么,但是基础框架层还是要有,需要编写的有调理。要不代码很复杂,再次调试编写的时候,看起来没有调理。别人看你的代码也会没有思路。
基础框架层每层用法编写完,接下来就可以分每个模块,文件的功能进行分析。
先从run.py执行文件开始。

执行文件,顾名思义,这个文件相当于自动化测试脚本的开关按钮。编写好脚本,配置好测试地址,配置好测试数据,所有准备工作做完之后,就在这个文件下执行。
If__name__=’main’:
这个是python内的的main方法,意思在这个main方法下的代码,只能在此文件执行时运行。就像base文件下封装的内置方法,可以在别的地方调用使用和运行。
但是加了这个main方法后,文件只能在当前py文件下被执行,别的文件不能调用。这个方法的意义,意思就是相当于这个开关只能在这个文件执行,要是别的文件都可以调用,都可以执行和运行代码,这个文件就没意义。而且这个文件调用一次,那个文件调用一次,非常不利于管理,所以每一个脚本都会有一个执行文件。
suite = unittest.defaultTestLoader.discover(‘./testcase’, ‘test_case.py’)
使用unittests默认的测试用例的加载器去发现tesecase目录下以py结尾的所有测试用例。方便管理,所有的测试用例都是以test开头的,统一格式,语句中索引的时候可以改程‘。/testcase’,‘test_*.py’意思是执行当前目录下testcase文件夹下以test_*开头的任意py文件。就可以一次跑多个测试用例,当文件名是指定的,唯一文件,运行就会执行这个单一的用例。
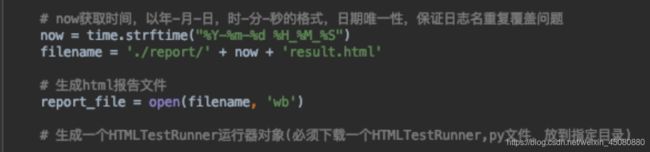
这三句是一起的,目的就是把测试报告写入到report文件夹下。
now这个对象,是调用time方法,生成当前时间,括号内的是生成的格式,因为时间是动态的。如果随便写,例如:xxx,跑完用例后,report文件夹下生成以一个xxx_result.html的自动化测试报告。代码不动,当换了测试数据,重新运行脚本,系统再一次生成xxx_result.html的自动化测试报告后,后面生成的同名的自动化测试报告会覆盖掉之前的报告。
所以引入time模块,取当前时间,因为时间是变量,会让每次生成的报告的名称不一样,不会覆盖,而且方便管理。

最后这一行open方法,是写入方法。’wb’是二进制写入模式。打开文件名为filename这个变量名的文件,写入报告,到这一行自定义保存自动化报告已经写完了。
接下来讲解框架模型,框架是采用POM模型(page object model)
方法层,页面层,用例层
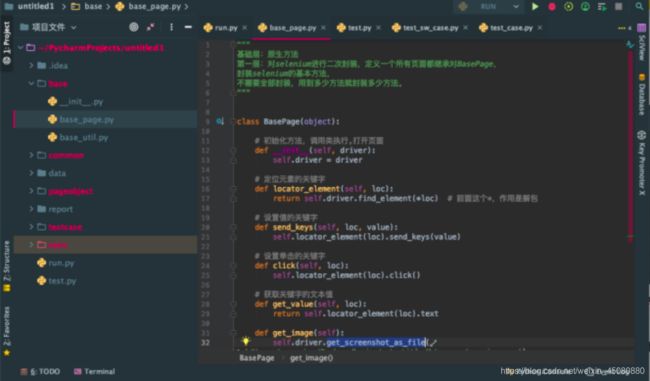
方法层
新建一个base的包,这个包中新建一个base_page的文件。
定义一个类,二次封装selenium中的方法,让所有页面都继承自这个类,方便调用。不需要全部封装,当需要用到什么方法,就手动在这个类中添加什么方法。
对方法的归类整理。好处是,二次封装的话,可以自定义拼接改造原生方法,更方便自己在自己的框架中使用。而且不同文件调用封装好的方法,如果要一起改掉,直接改源头的方法就可以了,代码的可维护性增强了。
 页面层
页面层
新建一个pageobject的包,存放所有的页面文件。
页面层主要是基于自动化测试会用到的界面。一个页面新建一个py文件,一个页面中封装一个页面,这个页面类继承base基类。方便页面类中调用selenium的原生方法。
页面中主要分为两个块:静态元素定位,动态页面方法。
静态元素定位:自动化测试脚本需要用到的元素,封装成一个个对象,方便写方法的时候调用,页面中只要定义需要用到的元素,页面中不需要用到的元素不需要定义写在类中。
动态元素方法:自动化测试脚本中封装好的页面方法,一个动作编写一个方法,利用页面中封装好的元素定位,完成页面动作,跟静态元素定位一样,只需要封装用到的动作,不需要的动作不需要封装方法。编写封装好页面动作,方便之后测试用例层调用。

用例层
新建一个tasecase的包,存放所有编写的测试用例文件。
用例层是直接调用页面层定义好的方法,运行用例。用例层一般添加测试数据,实现断言。
写完脚本,通过run文件就是执行用例层里面的文件,这一层通过ddt数据驱动,可以向测试用例中添加不同的情景,正常输入错误输入,然后加上新的断言。断言适用unittest中自带的断言方法,正确断言通过,错误断言,说明用例执行预期结果跟实际结果不一致,系统自动截图,最后统一结果返回。一个自动化测试流程基本就完整了。
能在用例层直接点击单条用例的执行按钮,可以调试单条执行用例,也可以直接点击类左边的执行按钮,执行类下的测试用例,用作调试。
自动化测试流程说明完了,接下来就是配置跟测试数据处理了。

这个写在base下的base_util文件,里面是配置的unittest下的两个原生方法。
本来testcase测试用例类事要继承自unittest.TestCase这个类的,才能调用到unittest下面的方法,但是把testcase类继承到BaseUtil类,继承到定义unittest夹具的类,然后BaseUtil这个类继承unittest.TestCase,相当于A继承自B,B继承自C,嵌套继承,所以testcase里面也能直接调用unittest.TestCase的内置方法,A能直接调用C的方法。
setUp是前置方法,执行每条测试用例之前,会先执行这个方法,所以把定义浏览器,打开浏览器的方法写在这个前置方法中,每执行一个测试用例,系统会自动打开浏览器,不需要每个用例中重写,节省类代码量。如果需要修改网址的话,只需要在setUp这个方法中修改网址,不需要每一个用例重写,可添加代码的可维护性。
tearDown方法是后置方法,在每个测试用例执行之后自动执行,例如可以截图,跑完一条用例截图放在指定文件,就可以写在这个方法下面,图中是没有需要每个用例后执行的东西,就写了个pass占位,什么都不执行,但是保证程序不报错。
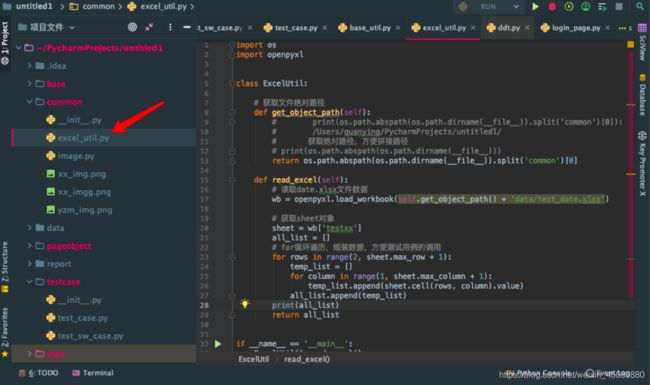
写在common文件夹下的excel_util文件是处理excel的方法。因为要导入测试数据,测试数据写在excel文档中,存放在data文件夹下。Excel_util文件中包含了两个方法,第一个是获取文件的绝对路径,调用了os内置库的方法,第二个read_excel方法是,读取文件。获取excel文件sheet页数据,再利用for循环的嵌套,把excel里面的数据按照我们需要的格式排列出来。可以用文件底部的main方法,利用print函数,去调用方法,把值打印在控制台上,看输出的是不是我们预想的结果和格式。这里输出的格式主要是契合ddt数据驱动,方便测试用例使用ddt数据驱动来对测试用例里面传值。
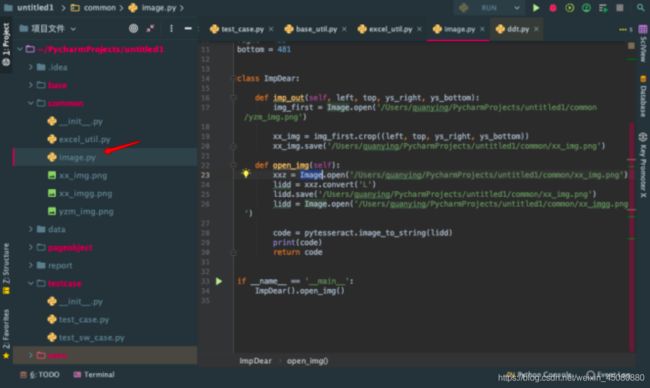
写在common下的另一个image.py文件,是对图片处理方法的代码。主要是针对验证码,需要安装一个PIL驱动,可以使用main方法调用。

ddt数据驱动
ddt数据驱动是加在测试用例层,哪个测试用例需要就给哪条用例加装上。
ddt: data driver test 数据驱动测试,结合unittest实现数据驱动
使用方法:装饰器
@ddt 装饰类,作用是申明当前类使用ddt数据驱动
@data 装饰函数,作用是给函数传值
@unpack 装饰函数,作用是数据解包
file_data 装饰函数,作用是直接读取yaml,json文件
这个是ddt的具体用法, 装饰器函数,哪个类需要用到,就在函数上面加@ddt

现在这个taskcase,用例类上面加上了@ddt.ddt,代表这个测试用例用到ddt数据驱动,然后后面需要调用的用例上加需要用的装饰器。
@ddt.data,给函数传值。ExcelUtil().read_excel(),这一节就是调用ExcelUtil类下的read_excel方法,刚才那个方法就是处理excel,让数据变成一组组的列表嵌套。
[[1,2,3],[4,5,6],[7,8,9]]像是这种,Excel.read_excel()取到read_excel返回的这组数据。前面这个的意思为解包。取掉最外层的[ ],就相当于三组数据[1,2,3],[4,5,6],[7,8,9],利用类数据驱动,有几组数据,这个测试用例就会执行几次。
然后加上@unpack,解包,把参数传到test_01_login这个函数中,函数的形参为args,这个为万能参数,就是不论传入多少参数,这个函数都不会报错,然后在下面给传入的数据赋值对象。
Index = arg[0]
username = arg[1]
password = arg[2]
列表是有序排列的,下标是从0开始的,就把传进来的数据依次赋值,在函数内部方法中使用。
如果不使用*args万能参数,也可以写成test_01_login(self, index, username, password),直接传递三个形参,这种也需要一一对应,这是属于位置参数的传递。使用类这种传参方式,函数内部就不需要赋值类,可以直接使用。
这就是给测试用例添加测试数据,然后有几组测试数据,该条测试用例执行几次。只要在正确的测试数据那条判断,比如在用例函数下写下判断。
If index == 1,写个if判断,因为传进来的index是序号,如果index为1,就进行断言操作,判断设置好的预期结果跟跑用例查到的实际结果是不是一致。一般回归测试只需要在正确的那条用例进行测试,如果错误的数据也要断言,看它返回提示是否正确,可以多加几条判断,例如:if index == 2,不同的测试数据,不同的序号,加if判断,判断下加断言。
编写自动化测试用例
1.先写页面层,把需要测试的页面定位,元素都写完。写的时候调用方法调用基类的方法,如果方法来定义,就去基类二次封装方法。调用。
2.写好页面层之后,就可以开始写用例层了,每一条用例一个方法,都需要test开头,用例里面直接调用页面方法,然后写base_util,夹具层,把启动浏览器,打开网站每条用例都需要用到的代码剥离出来。
3.然后使用ddt数据驱动给用例加测试数据,用例层是直接调用的common中定义的excel处理方法,excel处理方法直接取到存放在data下的excel文件,进行处理,方法处理完使用return返回出来。
4.用例层调用指定方法取到返回出来的测试数据,使用ddt一次次传到测试用例方法中,调用。再根据用例层写好定义好的断言,判断用例是否通过,执行完查看report文件夹,查看测试结果。